- bilibili
- 头条号
随着AI大模型训练、分布式计算等高性能应用的快速发展,智算网络对端到端路径质量的监控需求日益提升。近年来 INT(In-band Network Telemetry,带内网络遥测)作为新一代网络质量分析技术,也已从前瞻性学术研究领域走向了真实网络环境下的应用。
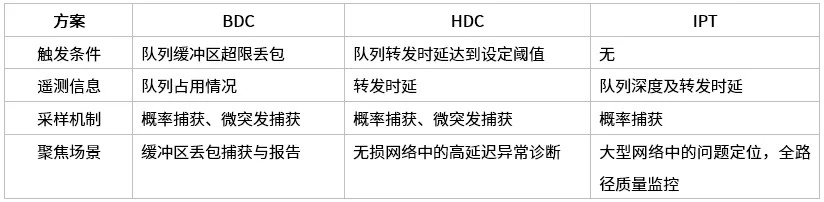
星融元现有方案中应用到的 INT 技术包含 BDC、HDC 以及 IPT 。其中 BDC 和 HDC 相关技术和工具应用我们之前已有专题文章介绍,请参阅:EasyRoCE 新年上新!基于INT的网络拥塞监控和告警工具
INT 技术对比
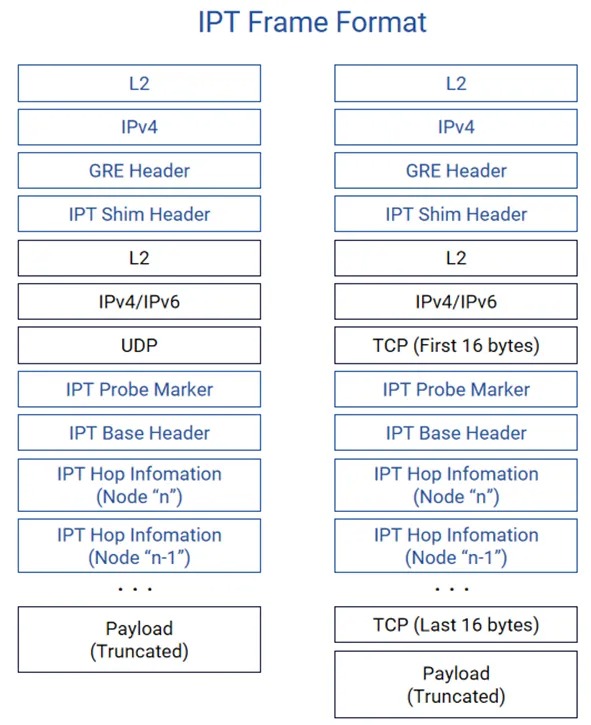
IPT,全称 In-band Path Telemetry,带内路径遥测。
通过前文的对比表格可以看到,作为 INT 技术的标准方案之一,IPT 侧重于实现端到端路径质量的精准监控。
IPT 报文由多层头部构成,包含外层L2/L3封装、GRE头部、IPT Shim头部、探针标记(Probe Marker),IPT Base Header,及各节点统计信息(IPT Hop Information)等字段。
在遥测域的每个交换节点之间(包括入口和出口节点),每跳统计信息都会被插入到IPT 探测数据包中,以下是记录统计信息的报文格式和字段描述。
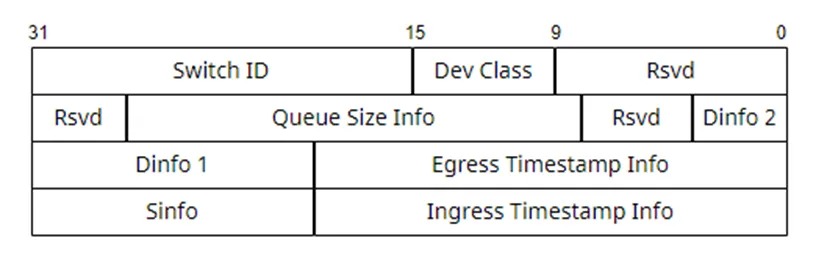
Switch ID 节点设备Dev Class 识别设备芯片的唯一编码,用于解码数据包中的信息。Queue Size Info 报文转发时队列实时占用大小队列占用大小Dinfo 2IPT数据包从该跳节点转发出去的出口队列信息。Dinfo 1IPT数据包从该跳节点转发出去的出接口信息Egress Timestamp InfoIPT数据包从该跳节点转发出去的时间戳信息SinfoIPT数据包进入该跳节点的入接口信息Ingress Timestamp InfoIPT数据包进入该跳节点的时间戳信息
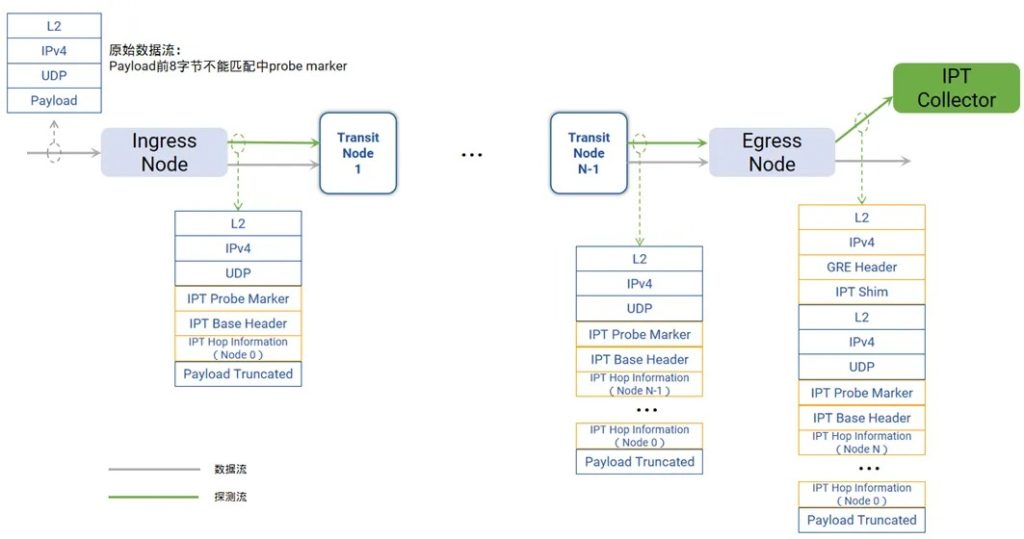
IPT工作流程图
IPT 通过在遥测域内配置入口节点、出口节点及传输节点,利用探针标记(Probe Marker)唯一标识遥测域,沿原始路径生成探测数据包并收集各节点统计信息,最终封装至收集器,为网络运维提供整网路径质量的多维分析能力。
我们可以将其工作流程简要拆解如下:
这是 IPT 技术的核心环节,重点在于流量采样、复制与探测包构造。
- 识别与采样:通过采样或者配置DSCP来指定队列的方式识别目标流量,而非对所有流量进行复制。
- 复制与截断:克隆原始业务报文,保留报文的二三层首部(Header),并截断原始负载(Payload),以降低遥测流量对带宽的占用。
- 探测包封装:在 UDP 或 TCP 首部的 前 16 字节之后 插入 IPT 专有字段。
- 插入标记与头信息:包含 探针标记(Probe Marker) 用于后续节点识别、IPT Base Header(标识版本和跳数等)以及该入口节点的统计信息。
- 同路径转发:探测包被赋予与原始报文相同的转发特征,确保它在网络中走过完全一致的路径。
中间节点不再需要处理庞大的业务流量,只需专注处理探测包,对其进行识别、追加与透传。
- 精准识别:节点通过识别报文特定偏移位置的 Probe Marker,迅速判定该报文为 IPT 探测包。
- 元数据追加:在不改变报文原有结构的基础上,将本节点的路径统计信息(如设备 ID、入/出接口、实时时延等)追加到 IPT 数据段中。
- 硬件透传:利用硬件转发面的能力,确保探测包的累加处理不会引入额外的计算开销,从而保证时延数据的真实性。
当探测包到达 IPT 域的出口节点,将会执行最终节点的数据收集与路径遥测数据的封装转发。
信息补全:写入最后一个节点的元数据,形成完整的端到端路径视图。
探测包终结和封装:出节点不再转发该探测包,而是将其从业务转发路径中“摘除”将收集到的全路径元数据封装并发送给采集器(Collector)。
由于探测包已经包含了原始报文的首部信息,分析平台可以轻松地将遥测数据与对应的业务流关联起来。
与直接修改业务报文的“染色”方式相比,基于采样和生成独立的探测报文的遥测方式,实现遥测流量与业务流量的分离,同时又能真实模拟业务报文在网络中的转发行为。
- 业务零干扰:由于修改的是复制出的探测包,即便遥测逻辑出现异常,也不会影响原始业务数据的完整传输。
- 低带宽压力:通过截断 Payload,极大减小了探测包的体积,适合大规模部署。
- 部署灵活性:在不支持 IPT 的设备上,探测包可以作为普通报文透传,而在支持的节点上则进行数据采集,具备更好的兼容性。
在某超千卡GPU集群的大模型训练场景中,集群依赖高性能网络实现节点间数据同步(如All Reduce操作),路径质量直接影响训练效率。IPT技术可在以下环节优化路径性能:
如下图所示,训练过程中,梯度数据需经多台Leaf/Spine交换机转发。IPT通过探测数据包采集各节点转发时延,结合入口到出口的总时延,定位高延迟节点(如某Spine交换机转发时延异常升高),辅助调整流量转发路径,避免因单节点延迟导致整体训练效率下降。
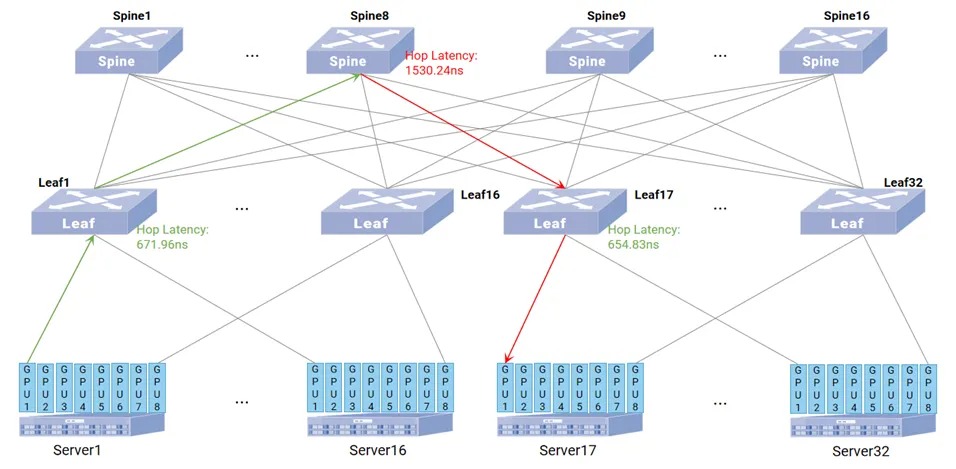
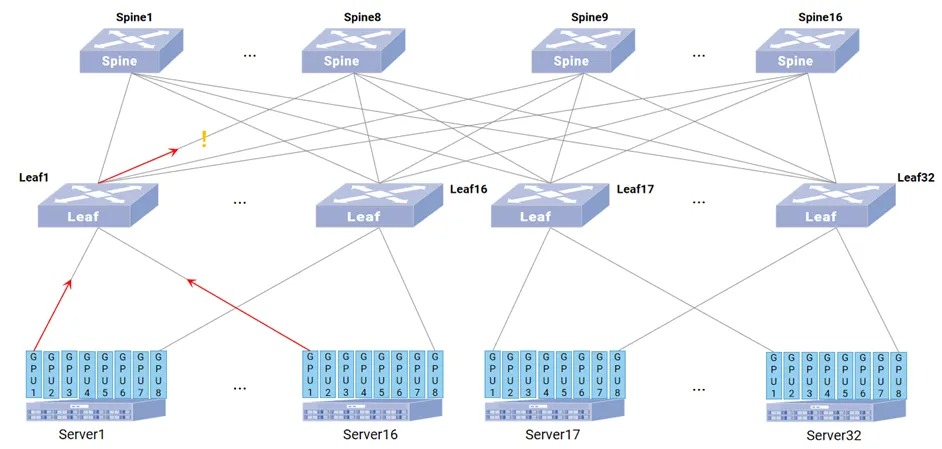
如图8所示,当多台GPU服务器通过同一交换机端口发送数据时,出方向队列可能因流量激增出现拥塞。IPT探测数据包携带队列占用大小、QP(Queue Pair)等信息,运维人员可快速识别拥塞队列,调整缓冲区分配策略(如增加突发流量处理容量),保障数据同步稳定性。
基于IPT技术的EasyRoCE小工具即将发布,敬请期待。
- bilibili
- 头条号
随着网络带宽向 100G 演进及云服务的普及,企业网络边缘正面临新挑战:传统的基于 IP 五元组(源 IP、目的 IP、端口、协议)的路由策略在处理各类企业 SaaS 应用和 CDN 内容时显得力不从心,具体来说网络工程师经常面临以下痛点:
- IP 动态化: 服务器 IP 频繁变化,静态 IP 列表维护极其困难。
- IP 复用: 单个 CDN IP 可能承载多个不同服务,仅靠 IP 无法实现精确识别。
- 性能瓶颈: 在高吞吐环境下,复杂的匹配规则会导致严重的转发性能下降。
应对以上挑战,AsterNOS-VPP(什么是AsterNOS-VPP?) 通过 GeoSite/GeoIP 技术提供了一个快捷准确的流量调度方案:摒弃臃肿的 DPI 插件,通过仅解析报文头实现了线速转发,并完美适配 TLS 1.3 时代的加密环境,将流量控制权交还给网络工程师。
AsterNOS 将网络策略的重心从传统的“地址”转向了身份(Identity)与来源(Origin),其工作流遵循简洁的“三步法”:
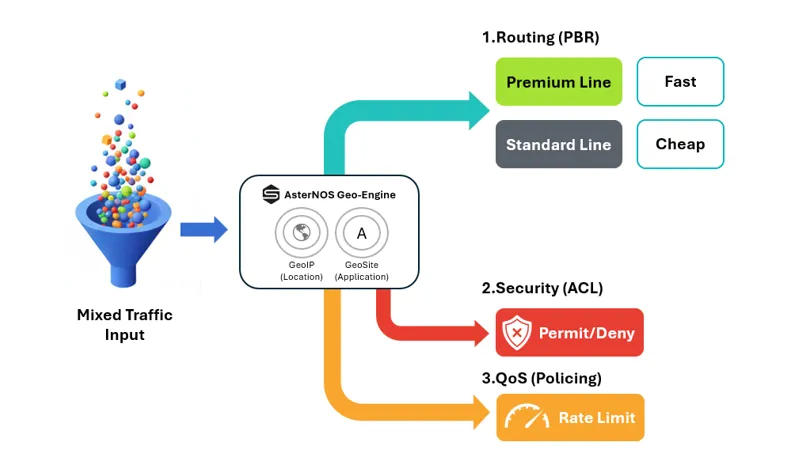
1、识别 利用 Geo-Engine 实时分类流量,无需手动维护 IP 列表
- GeoIP: 按区域(如 CN, US)识别
- GeoSite: 按应用(如 YouTube, 游戏,办公应用)识别
2、定义: 关联标准功能模块确定处理动作,如策略路由(PBR)、安全策略(ACL的允许或拒绝)或带宽限速(QoS策略)
3、执行: 将策略绑定至物理或逻辑接口
AsterNOS 选择了 GeoSite 路径而非传统的 L7 DPI(深层数据包检测),主要基于以下技术维度的考量:
为了在数据面线速识别流量,AsterNOS 开发了 geosite_plugin.so 插件,将其作为 geosite_input_node 集成在 VPP 节点中。
与深层数据包检测(DPI)不同,该技术专注于不同协议的报文头特征字段的提取:
- HTTPS/TLS: 在 TLS 握手阶段解析
Client Hello包,提取SNI(Server Name Indication) 字段

- HTTP/1.1: 解析请求头中的
Host字段

- DNS: 当设备作为 DNS 代理或网关时,直接从
Query Name字段提取域名

- SOCKS5: 提取
ATYP为域名类型时的DST.ADDR

提取域名和IP地址特征后,系统需将其与规则数据库(.dat文件)进行比对,借助高效的数据结构确保线速的转发性能。
- IP 匹配: 通过 PATRICIA Trie 管理IP掩码规则,支持最长前缀匹配(LPM)。即使单个IP匹配多条规则(如同时属于Google和US),系统仍能根据优先级返回准确结果。
Patricia Trie(帕特里夏树)是一种专门处理字符串匹配的高效索引结构。它通过合并只有单一子节点的路径来“压缩”空间,像一棵去掉了冗余分叉的树。在网络路由中,它能以极速实现最长前缀匹配,即从成千上万条路由规则中瞬间锁定最精确的那一条 。
- 域名后缀匹配: 支持根域名匹配,通过 Trie 树结构加速检索
数据包进入VPP的 ip4/6 输入节点后的处理流程如下:
- 域名提取:数据包进入
geosite_input节点,根据协议类型提取域名。 - 会话查询:系统查询现有会话表。若存在匹配结果则直接复用,减少重复解析开销。
- 规则匹配:
- 域名特征匹配:对于携带域名信息的数据包(如TLS客户端初始化、HTTP主机字段、DNS查询),系统优先提取域名特征并与GeoSite规则库进行匹配,这是最精确的识别方式。
- IP匹配:对于域名未匹配任何规则的数据包,系统利用DNS解析结果匹配配置的GeoIP规则。
- 对于无法提取域名数据包,系统直接使用IP地址进行匹配。
根据匹配结果,系统执行相应动作,例如允许、拒绝或配置策略路由的下一跳。
背景: 企业拥有高速但昂贵的企业专线和较为廉价的 ISP 线路,传统方案下需手动收集海量 IP 段,让重要的办公业务应用如 ZOOM,Office 365 走企业专线确保网络性能,其他一般占用大带宽的非关键应用走 ISP 普通线路。但是,一旦应用更新了 IP,策略便会马上失效
AsterNOS方案: 编写基于域名的策略路由,无论应用如何改变 IP,只要 SNI(服务器名称指示) 匹配 geosite:zoom,流量自动导向企业专线
伪代码示例:
pbr-map SMART_ROUTING
match geosite ZOOM set nexthop <Premium_Gateway_IP>
match geosite MICROSOFT set nexthop <Premium_Gateway_IP>
- 背景: 企业禁止特定国家 IP 访问内部服务器,或限制员工办公时间访问社交媒体;传统方案是在防火墙产品内订阅 GeoIP 数据库(可能存在高昂的订阅费用)或者手动添加基于IP的策略规则,以上都会影响防火墙的性能
- AsterNOS方案: 利用 GeoIP 和 GeoSite 的分类能力,在 VPP 转发面直接阻断违规流量,不消耗下游处理资源
- 伪代码示例:
access-list SECURE_ACL
# Deny all media websites (based on domain classification)
rule 10 deny geosite CATEGORY-MEDIA
# Block US IPs (based on geo-location)
rule 20 deny geoip US
- 背景: 办公工具应用(如 ZOOM 会议)与带宽大户(Youtube)共享同一加密通道(HTTPS/443),传统基于端口的 QoS 无法区分
- AsterNOS方案: 利用有状态的应用感知 QoS。在初始握手阶段识别特定应用,并创建动态会话仅对目标流进行限速
- 伪代码示例:
# Define the throttle policy
traffic behavior LIMIT_STREAMING
car sr-tcm cir 100 cbs 6400
# Create Stateful ACL
access-list REFLECT_L3 APP_QOS_POLICY
rule 10 geosite YOUTUBE traffic-behavior LIMIT_STREAMING
AsterNOS-VPP 目前主要支持运行在星融元ET系列智能业务处理平台之上。
 产品图" width="300" height="140" class="alignnone size-medium wp-image-26839" srcset="https://asterfusion.com/wp-content/uploads/2025/05/20250514_ET2500_02-300x140.jpg 300w, https://asterfusion.com/wp-content/uploads/2025/05/20250514_ET2500_02-1024x479.jpg 1024w, https://asterfusion.com/wp-content/uploads/2025/05/20250514_ET2500_02-768x359.jpg 768w, https://asterfusion.com/wp-content/uploads/2025/05/20250514_ET2500_02-1536x719.jpg 1536w, https://asterfusion.com/wp-content/uploads/2025/05/20250514_ET2500_02-600x281.jpg 600w, https://asterfusion.com/wp-content/uploads/2025/05/20250514_ET2500_02.jpg 1697w" sizes="(max-width: 300px) 100vw, 300px" />
产品图" width="300" height="140" class="alignnone size-medium wp-image-26839" srcset="https://asterfusion.com/wp-content/uploads/2025/05/20250514_ET2500_02-300x140.jpg 300w, https://asterfusion.com/wp-content/uploads/2025/05/20250514_ET2500_02-1024x479.jpg 1024w, https://asterfusion.com/wp-content/uploads/2025/05/20250514_ET2500_02-768x359.jpg 768w, https://asterfusion.com/wp-content/uploads/2025/05/20250514_ET2500_02-1536x719.jpg 1536w, https://asterfusion.com/wp-content/uploads/2025/05/20250514_ET2500_02-600x281.jpg 600w, https://asterfusion.com/wp-content/uploads/2025/05/20250514_ET2500_02.jpg 1697w" sizes="(max-width: 300px) 100vw, 300px" />
ET2500开放智能业务处理平台
- 设备尺寸:220 x 310 x 44 mm
- 业务接口:4 x 10GE (SFP+), 4 x 2.5GE (RJ45), 8 x 1GE (RJ45);其中4个 2.5G 和 1G 接口可选 POE++供电,总功率预算为 150W
- 风扇模块 x2 ,电源模块 x1
- 满负载功耗 60w,不含 PoE
- 扩展支持 5G/LTE、WiFi-6E/7、BlueTooth 5.3、GNSS、TPM等
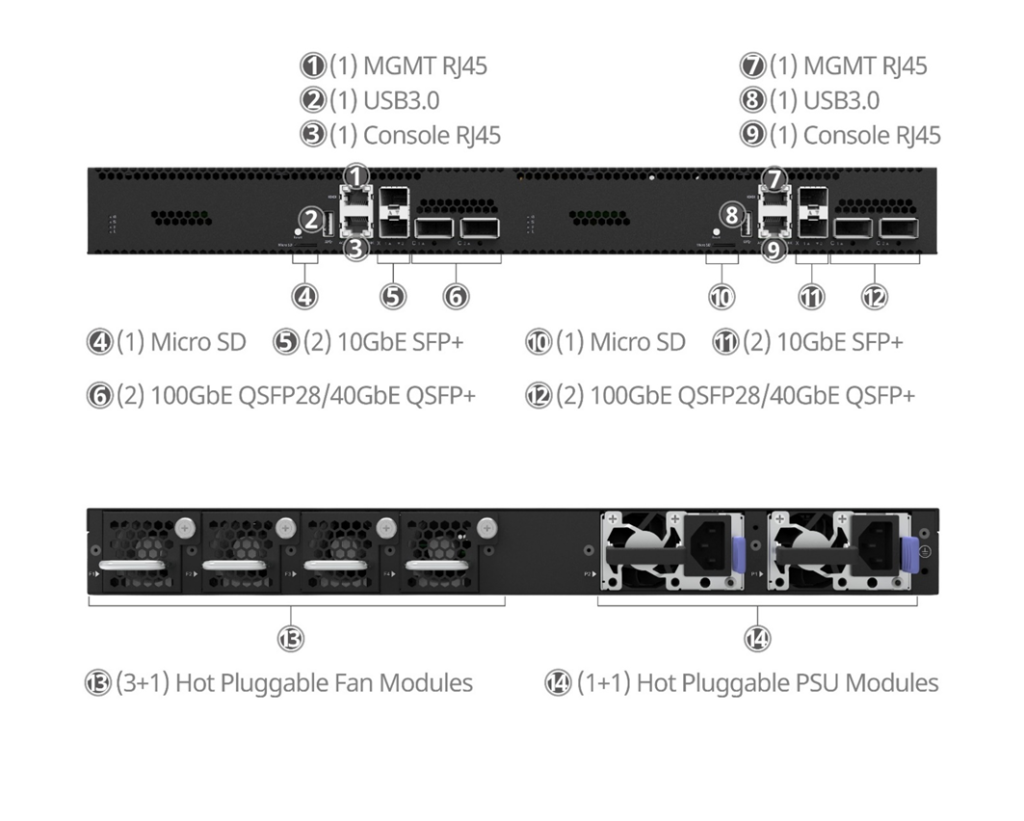
ET3600 系列开放智能业务处理平台
- 设备尺寸:440 x 470 x 44 mm
- 业务接口:2或4 x 10GE (SFP+), 2或4 x 100GE (QSFP28)
- 风扇模块3+1 ,电源模块1+1,2个M.2插槽, 可选PTP模块
- 满负载功耗100w或200w
- bilibili
- 头条号
前言:基于 INT 技术,星融元开发了 EasyRoCE-CMA( Congestion Monitoring & Alert,拥塞监控与告警) 工具实现纳秒级的采集精度,一站式呈现交换机端口队列级的拥塞丢包异常状态,辅助网络快速调优
在网络监控演进中,Pull与Push是两种传统的基础范式。
Pull 模式由监控服务器主动向被管设备发起数据采集,例如通过 SNMPGet或 ICMPPing 定期轮询设备状态。该方式便于集中控制,适合指标趋势分析,但实时性依赖轮询间隔,且高频率采集会增加服务器与网络负担。
Push 模式则由被管设备主动将数据发送至监控服务器,例如设备通过 SNMP Trap 或 Syslog 主动上报故障事件,其优势在于实时性较强,但信息孤立。
带内网络遥测(In-band Network Telemetry)区别于传统网络监控运维的最大差异,是从“外部观测”到“数据自述”的革命性转变——不只是基于事件的 Push,而且还让网络数据包自身成为探针,在转发路径中“自行记录”网络状态,同时做到最高纳秒级的实时性与路径级的可视化,完美捕捉网络中偶发的、微突发(Micro-burst)的问题。
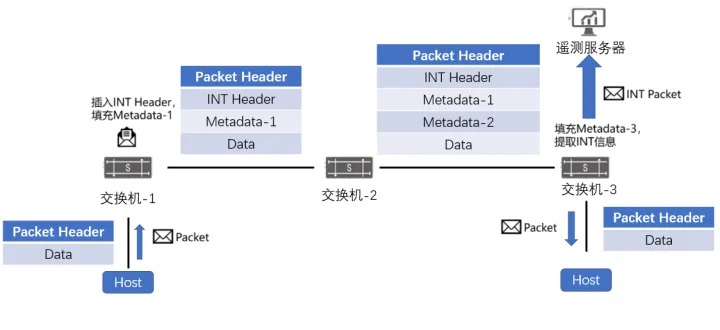
INT 技术的实现由交换机底层硬件支持,在数据平面芯片内部进行采集,通过在业务数据包内嵌入指令,使交换机在转发时动态插入本地的精准遥测数据(如设备ID、队列时延、拥塞状态等),最终由接收端(如服务器或其他网络边缘设备)解析并上报这些信息。
服务于AI智算等大规模复杂流量环境的 EasyRoCE- CMA工具主要借助了星融元交换机基于 INT 特性生成的 High Delay Capture(高延迟捕获) 与 Buffer Drop Capture(缓冲区丢包捕获) 信息。
BDC 专注于捕获和分析与交换机 Buffer 相关的问题。
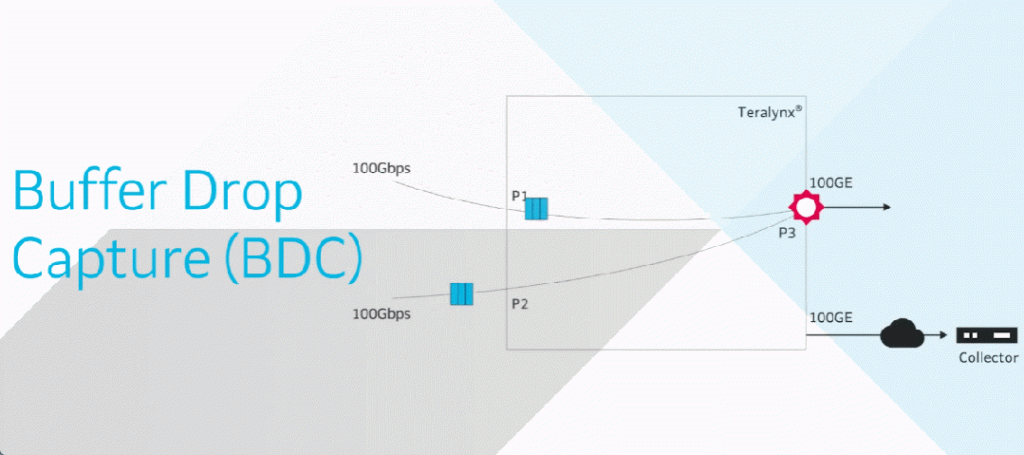
当数据包因缓冲区容量限制被丢弃时,交换设备会为该丢弃数据包添加元数据,并将原始数据包前150字节,连同元数据打包作为 BDC 数据包发送至远端收集器或者本地交换设备CPU——通过收集BDC报文中包含的报文节点ID、队列缓冲区大小和QP(Queue Pair)队列等信息,我们可以识别出潜在的缓冲区溢出和数据丢失情况,由此网络工程师可快速采取措施优化缓冲区配置,提高通信性能。
HDC 则专注于捕获和分析网络中的高延迟问题。
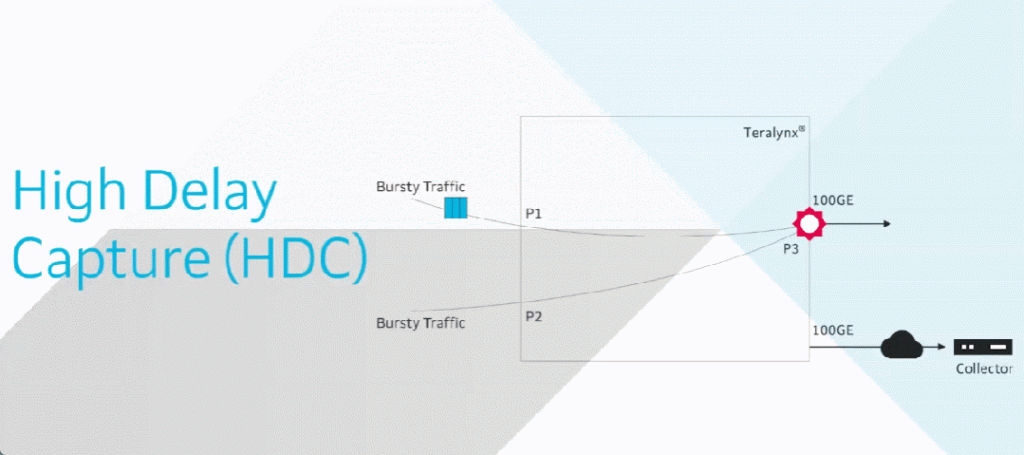
交换机设备会捕获所有超过用户设定阈值的延迟数据包,并将原始数据包的前 150 字节连同元数据打包成 HDC数据包发送至远端收集器或者本地交换设备CPU,同时原始数据包仍保持正常传输——通过监测 HDC 报文中的节点ID、累计时延和丢包数量等关键字段,帮助工程师识别出网络延迟的根本原因,辅助系统优化或排障。
EasyRoCE-CMA( Congestion Monitoring & Alert,拥塞监控与告警) 运行在安装有 EasyRoCE Toolkit 相关组件的服务器上,该服务器连接到所有被监控交换机的 INT 接口(星融元交换机大多拥有额外的两个10G口用于传输此类网络遥测数据,不影响生产网络)。
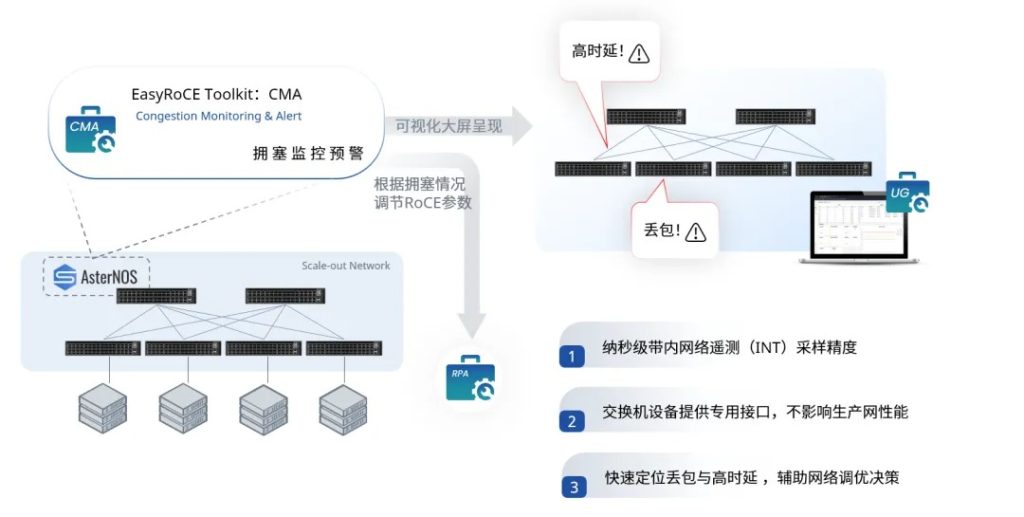
CMA工具主要分为控制面与业务监控面两部分。
启用工具时,CMA控制面会先从EasyRoCE-AID工具读取到交换机的基础信息,此后用户可在相应界面图形化地设置交换机 HDC/BDC功能的启停状态;
业务监控面则负责解析收到的 HDC 和 BDC报文,并将各交换机的流量运行状况和异常流量的详细报文信息导出到后端监控平台,做可视化呈现,比如 EasyRoCE-UG;除此之外,CMA 所采集到的信息也可以用于 EasyRoCE- RPA 工具的参数优化。
CMA 本次发布的1.0版本主要包含以下几个功能界面。
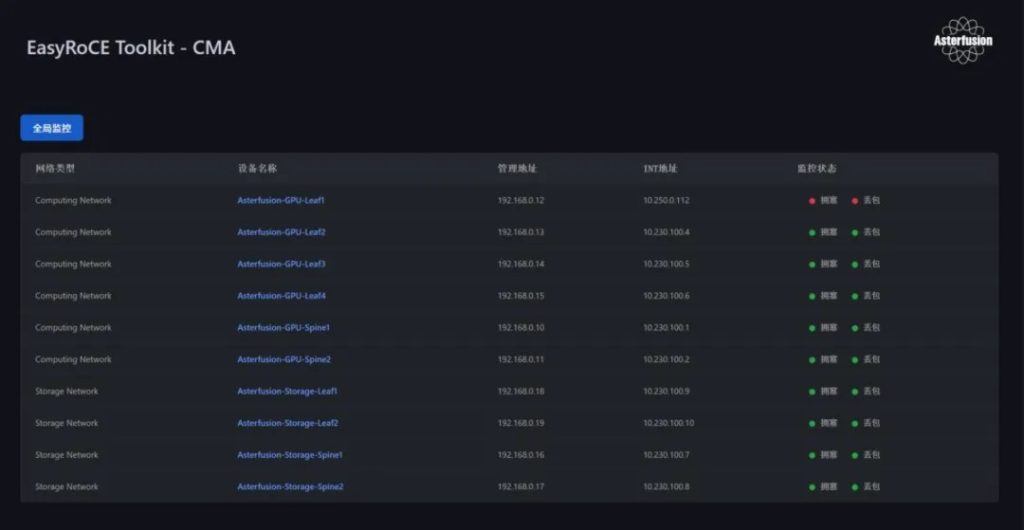
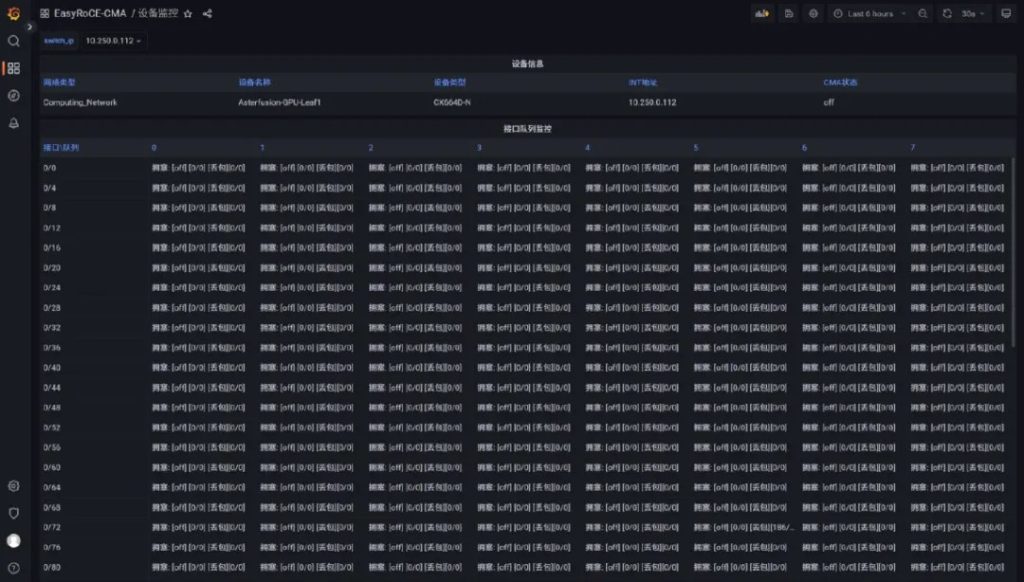
CMA 首页可以通览所有交换机的网络拥塞和丢包状态,默认情况下,CMA在5分钟内收到某个交换机的HDC/BDC报文,监控状态一栏相应状态会显示变红。
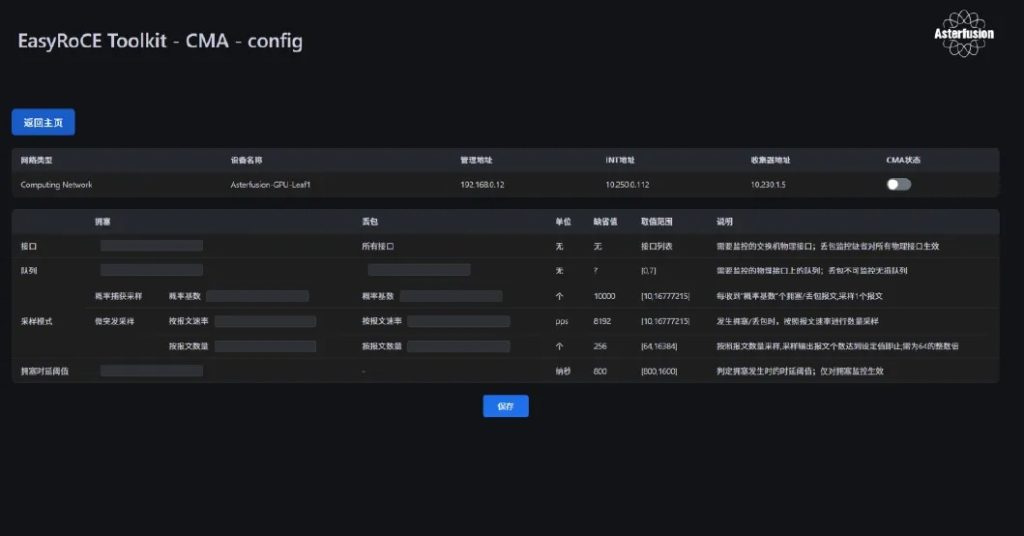
首页点击交换机名称进入该设备的配置面板,进入该页面时,CMA会实时从交换机同步 INT 配置的开关和具体参数情况,如需修改编辑参数先要关闭 CMA 开关。
CMA 首页点击全局监控按钮后可在一个页面上查看被监控的所有交换机发出最近1000条 HDC 和 BDC 报文信息,其中包含报文相关的上下行设备和该报文所关联的业务报文详情。
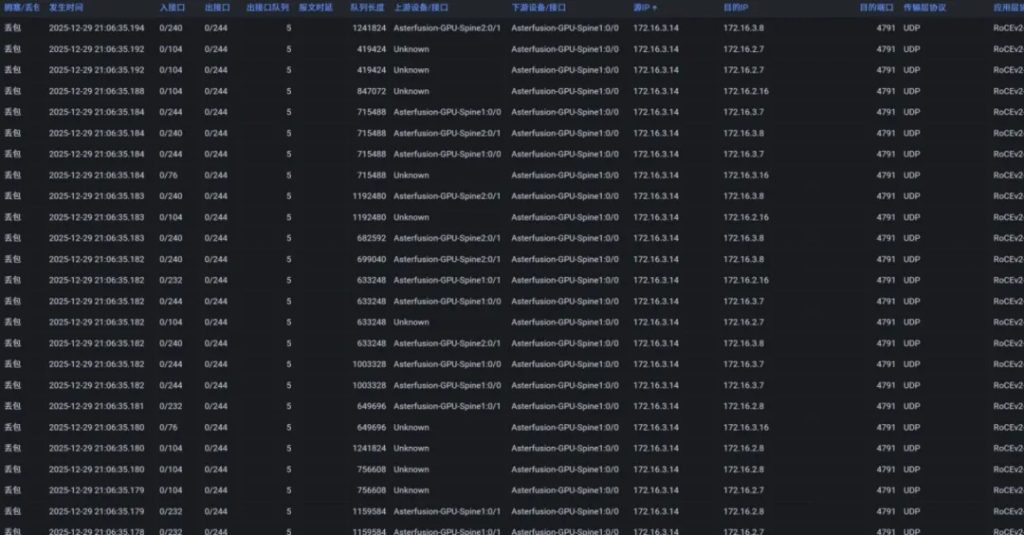
CMA 首页点击设备所在行会展示指定设备上所有接口,以及接口上所有8个队列的拥塞/丢包状态,此表下方附有该交换机发出的所有 BDC/HDC 报文详情。
相关阅读:
EasyRoCE:AI基础设施蓝图规划 AI Infrastructure Descriptor (AID)
INT-based Routing:AI时代的智能路由
- bilibili
- 头条号
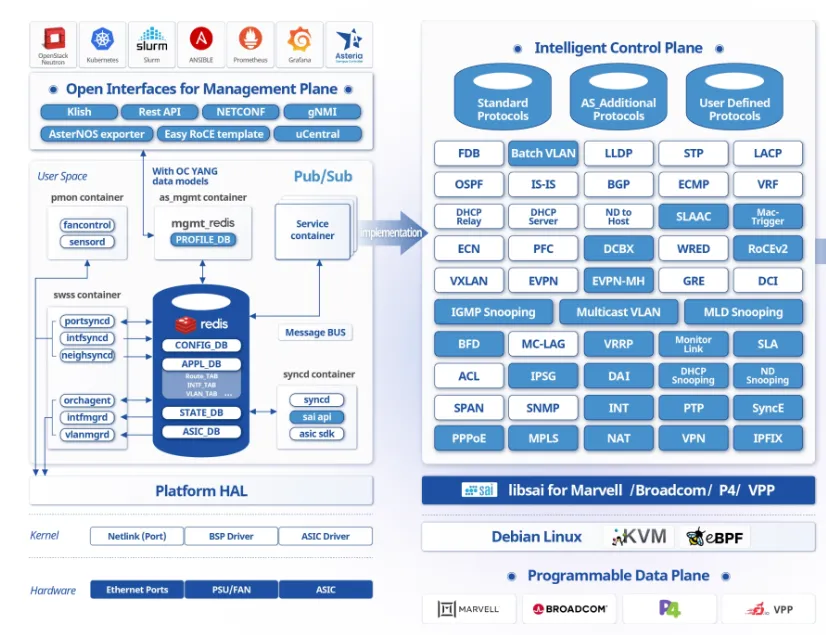
截至2025年底,运行最新版本AsterNOS的星融元交换机已支持新一代的基于 YANG 数据模型的运维管理接口,包括 NETCONF,RESTCONF(REST API)和 gNMI,覆盖数据中心、园区和边缘智能网关/路由等场景。
CLI(命令行接口) 是一种基于文本的交互界面,用户通过键盘输入文字指令,由命令解析器完成解析之后向被管理设备下发指令。
CLI 作为最广泛最基础的管理手段用来管理小规模简单网络基本够用,一旦组网规模扩大,业务复杂化,其管理效率的下降显而易见。
SNMP(简单网络管理协议) 开发于上世纪 80 年代末,是第一个被广泛部署的互联网网络管理标准。
SNMP 基于服务器/客户端架构,被管理网络设备作为 SNMP Agent,向网管系统(NMS)提供各种信息,NMS 则通过 SNMP 协议向设备进行查询和配置,两者的交互过程主要是 NMS 和 Agent 一问一答的 Pull 模式,也可以由 Agent 主动上报信息(比如告警)。
尽管 SNMP 最初是为网络设备配置而设计的,但由于其缺乏更复杂的网络配置任务所需的灵活性和可靠性,目前主要用于采集呈现监控指标——通过整合不同设备厂家的管理信息库(MIB, Management Information Base),从中拿到所需指标的 OID 值由NMS完成对多厂商设备的统一集中监控。
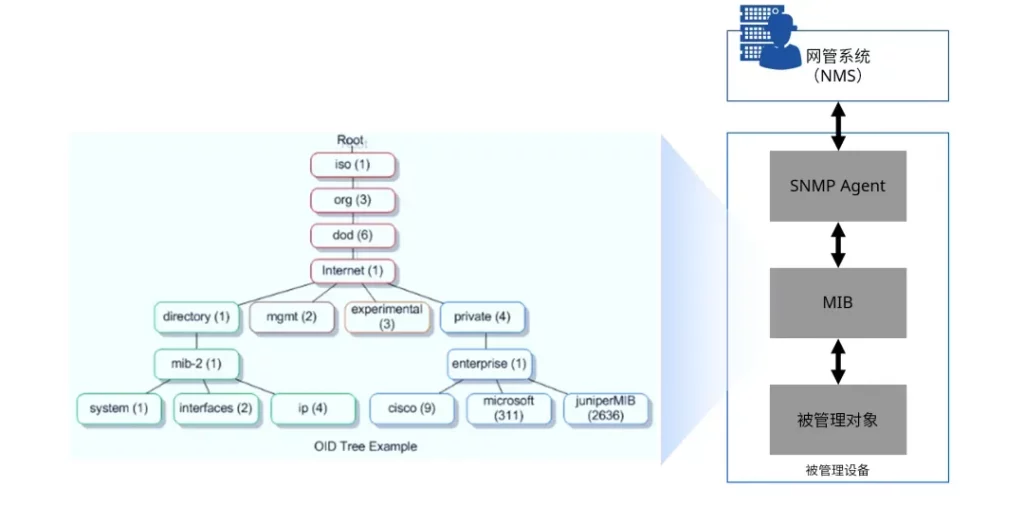
MIB 是一个树型结构的数据库,定义网络设备中可管理资源,包括变量名称、数据类型、访问权限等,通过对象标识符 OID(object identifier)确定与被管理对象的对应关系;每个支持 SNMP 管理的设备都有自己的 MIB。
可以看到 SNMP 在定义监控参数方面的确有效,但也存在诸多缺陷,例如 SNMP 仅支持分钟级的监控精度,无法反映微突发流量,以及大规模监控需求下的 Server 资源占用问题等等。
无论是CLI还是SNMP,在应对现代网络复杂、动态的需求时,逐渐显现出其在效率、精确性和一致性方面的局限性,这种局限性的本质在于它们是面向被管理对象单独配置的,而不是面向业务。
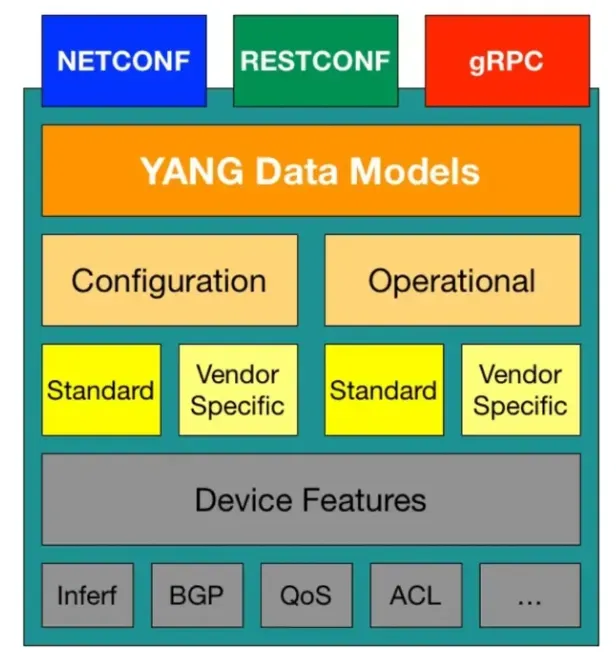
为了解决以上问题并应对现代网络环境中日益增长的配置管理需求,IETF 提出了 YANG(Yet Another Next Generation)作为描述网络配置数据的建模语言,正如其名,YANG 定义了一种适用于新一代网络管理的数据结构,其上是新一代的网管协议如NETCONF、RESTCONF、gRPC 等等。
相较于SNMP 使用的 MIB,YANG 模型更有层次,可扩展性更强。
MIB 使用平铺的表结构,难以区分配置和状态数据,用唯一的OID(如 1.3.6.1.2.1.4.3)来访问对象,而 YANG 模型支持用更灵活丰富的数据结构去描述设备的配置(configuration)和运行状态(state)信息,甚至是操作。
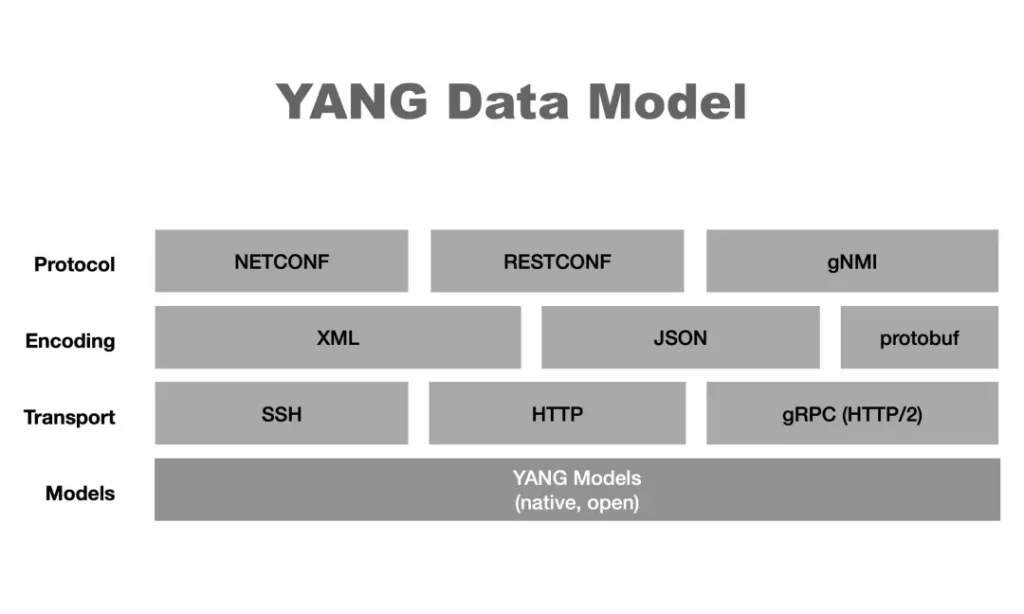
有了结构良好的 YANG 建模语言,网络运维工程师依照设备厂商所支持的 YANG 模型文件(厂商私有或开放标准,用于具体定义设备状态/配置数据的层次化结构)编写YANG 数据实例,并将其用 XML 或 JSON 编码后下发到设备用以执行各类配置管理操作。
发送方式可以是基于 SSH 的 NETCONF,也可以是基于 HTTP 的 RESTCONF(RESTful API),或是基于HTTP/2的 gRPC。
设备供应商使用原生的 YANG 模型或 IETF/OpenConfig 提供的标准 YANG 模型来描述其所有配置层次结构和所有支持的功能。网络工程师若需对设备进行配置,仅需要拿到对应设备的YANG文件并按照它的定义向设备下发即可。
以下是使用 NETCONF 在星融元园区交换机的eth1上创建静态ARP的示例。
<config><top>
<interfaces>
<interface>
<name>Ethernet1</name>
<ipv4>
<address operation=“create”>
<ip-prefix>20.1.1.1/20</ip-prefix>
</address>
<address operation=“create”>
<ip-prefix>30.1.1.1/20</ip-prefix>
</address>
<neighbor operation=“create”>
<ip>20.1.1.2</ip>
<mac-address>00:0e:c6:56:9d:35</mac-address>
</neighbor>
<neighbor operation=“create”>
<ip>30.1.1.2</ip>
<mac-address>00:0e:c6:56:9d:35</mac-address>
</neighbor>
</ipv4>
</interface>
</interfaces>
</top></config>
设备供应商使用 YANG 模型描述设备上当前运行的各种接口和协议的所有运行状态,这些信息可以通过以下两种方式获取。
- 使用 NETCONF 的 GET RPC (远程过程调用)和或供应商支持的其他管理接口的 RPC,与 SNMP 非常相似
- 使用网络遥测技术(Telemetry)来定义需要监控的字段,并将遥测信息发送到指定的收集器,采集精度可达纳秒级
可见, YANG 数据模型适用于各种现代化的网络管理场景,包括但不限于:
- 网络配置管理:自动配置和同步网络配置,减少人为错误,提高运营效率
- 网络状态监控:利用 YANG 模型对网络状态进行实时监控和验证,从而实现主动管理和故障排除
- 网络服务编排:支持 NFV 和 SDN 架构中的复杂服务定义和编排,从而实现动态的、按需的网络服务
NETCONF 定义了基于 YANG 的现代网络管理范式,管理应用通过安全可靠的连接,使用基于XML的数据编码对网络设备进行精准的配置操控与数据获取,有明确的连接建立、会话和关闭过程,适用于电信级网络、核心路由器/交换机等对配置可靠性和精确性要求极高的组网环境。
以下是一个典型的数据中心带外管理网拓扑:
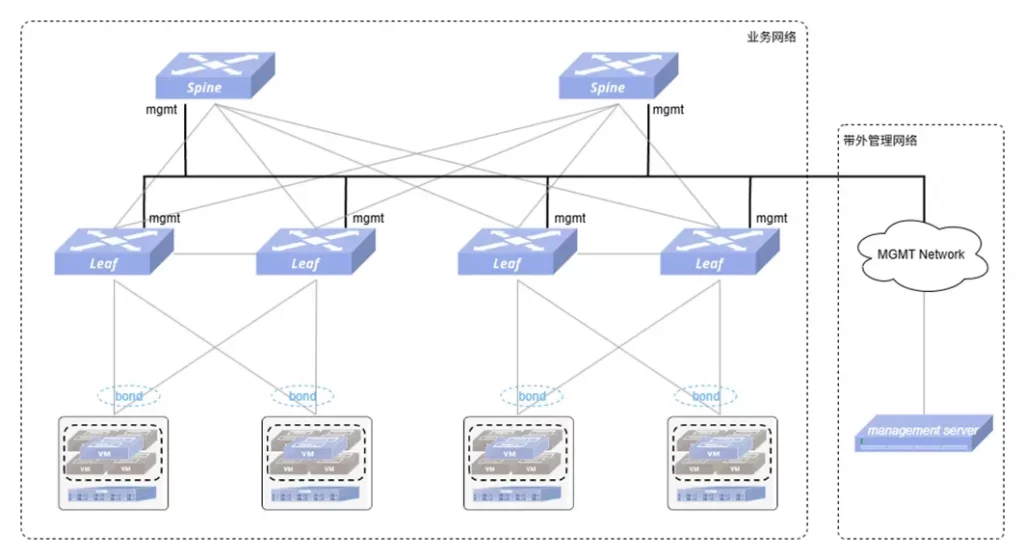
在带外管理网络内部部署一台管理服务器,使其能与所有交换机进行网络通信,即可对所有交换机进行集中管理,例如配置变更和状态检查。
NETCONF 和 YANG 提供了相对统一的操作接口来管理跨厂商的设备,同时具备强大的配置事务机制,配置失败时可以自动回滚。尽管不同厂商的设备支持的YANG模型可能不同,但管理应用可以建立在相同的底座上对所有设备执行相同的操作(如<edit-config>)。当具体的操作数据不同,可能需要网络管理员针对不同厂商设备编写不同的配置数据模板,而配置数据的语法又是相同的。
RESTCONF 是 NETCONF 面向 RESTful API 的“简化版”,2017年融合了 NETCONF 和 HTTP 协议的 RESTCONF 悄然诞生,为用户提供高效开发 Web 化运维工具的能力,提供的编程接口符合IT业界流行RESTful风格,与现代云原生应用和 DevOps 工具链(如 Ansible, Python脚本)集成度极高,学习成本低。
与 NETCONF相比,RESTCONF 提供基本的 CRUD 操作,使用标准的 HTTP 方法(GET, POST, PUT, PATCH, DELETE),通常不用来实现复杂的事务配置。
gRPC(google Remote Procedure Calls)是Google于2015年发布的高性能通用RPC开源软件框架,基于HTTP/2协议实现,支持以Protocol Buffers格式定义接口,并以二进制编码传输数据,此外还具备跨平台等特性。通信双方都基于该框架进行二次开发,gRPC承担了传输、安全、编码等工作,使得开发者可以专注于应用层的接口定义和实现。
gNMI(gRPC Network Management Interface)是基于gRPC定义的一套用于管理目标设备的开源接口协议,gNMI 由谷歌发起,并得到 OpenConfig 社区大力推动,是未来发展方向,尤其在需要实时可视性和自动闭环控制的云原生网络中优势明显。
gNMI定义了以下四种服务:
- Capabilities:获取目标设备的能力。
- Get:获取目标设备当前的状态和配置数据。
- Set:向目标设备下发/修改配置。
- Subscribe:订阅/高速采集目标设备的数据。
在常规的状态查询和配置修改方面,gNMI 和 NETCONF 的能力相差无几;但对于大型数据中心、云网络、5G 核心网等需要海量、实时监控数据和高频配置的场景,gNMI 性能卓越,通过单一协议解决了配置与监控需求,并且原生支持流式遥测,推送模式效率远高于轮询,是云原生/可编程网络的首选。
以下是一个典型的数据中心云网场景组网拓扑,使用遥测方式对网络进行监控:
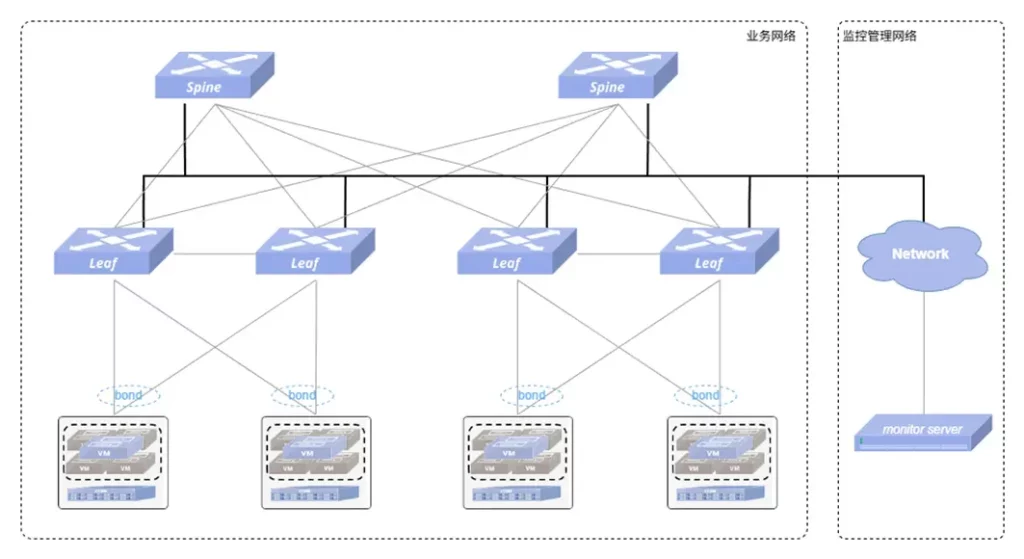
通过连接星融元数据中心网络交换机提供的额外 10G 接口并辅以隔离性配置,监控服务器可在不干扰业务流量的情况下对所有设备发起gNMI订阅请求,持续高频获取网络设备的各类信息,只要是设备支持的YANG模型有建模的数据均可。
gNMI 可采集的数据十分丰富,可用于监控设备状态、监控流量计数,配合 Prometheus 和 Grafana 等可视化工具,以上时序数据可被转化为直观的统计图表,并进一步实现系统异常告警、流量分析等功能。
截至2025年底,运行最新版本AsterNOS的星融元交换机,包含数据中心、园区和边缘智能网关/路由产品系列,已支持新一代的基于 YANG 数据模型的运维管理接口,其中包括 NETCONF,RESTCONF(RESTful API)和 gNMI ,提供设备配置(如路由协议配置)、系统状态(如CPU负载、内存使用量、主板温度、风扇转速)以及端口转发计数、ACL命中计数、关键资源使用量在内的丰富统计信息。
- bilibili
- 头条号
数据中心的带外管理网是一个独立于业务网络的专用管理通道,是数据中心运维体系中关键的容错和保障机制,其核心作用是在主业务网络发生故障、设备宕机或系统无法远程登录时,为管理员提供一条“备用通道”,从而实现对设备的持续访问和控制,保障业务的连续性。
通常我们会使用千兆电口交换机去连接区域内所有不同类型服务器和网络交换机的带外管理口,并为其划分出独立的IP地址段,与业务网络地址段严格区分,以避免路由混淆。
典型配置工作如下:
- 登录所有服务器设备,按照规划给服务器带外口/网络设备管理口配置静态的管理IP地址,掩码和网关信息
- 在交换机上根据设备类型或管理权限划分不同的VLAN(如服务器管理VLAN、网络设备管理VLAN),以实现逻辑隔离和权限细分
而如今,上述的配置工作也可以免去了。
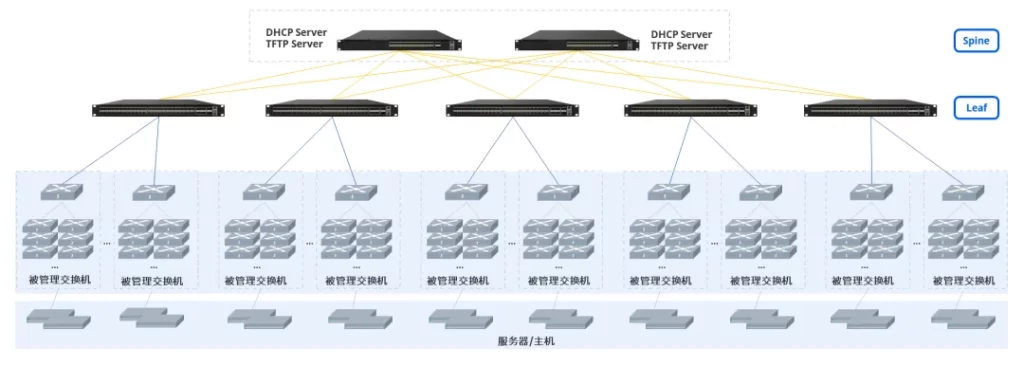
图1:管理网零配置上线方案概要
在星融元的交付实践中,我们依托SONiC交换机的开放特性,通过在交换机内部运行DHCP server 和 TFTP server,已轻松实现了带外管理网的“即插即用”零配置开局配置,无需额外的管理节点。
✦ 交换机自动上线并分配到不同 VLAN 用于标识和区分
✦ 终端主机根据DHCP请求包 option 携带的主机位置自动获取到预先规划的IP地址,完成上线(比如按照设备物理安装和连接位置按序分配,后续管理时可轻松定位)
✦ 双活DHCP服务器,高可靠设计保障业务
本例所用到的设备为:

- 星融元 CX202P-24Y-M,2x100GE + 24x25GE QSFP28,作为管理网的Spine /核心交换机,运行TFTP server 和 DHCP server,支持 DHCP option82/66/67

- 星融元 CX206Y-48GT-M,6x10GE+48x1GE RJ45,作为管理网的 Leaf/接入交换机,下连各类被管理设备;
以上交换机均搭载基于SONiC的 AsterNOS 网络操作系统,容器化架构,支持完备的数据中心/云化园区网络特性。
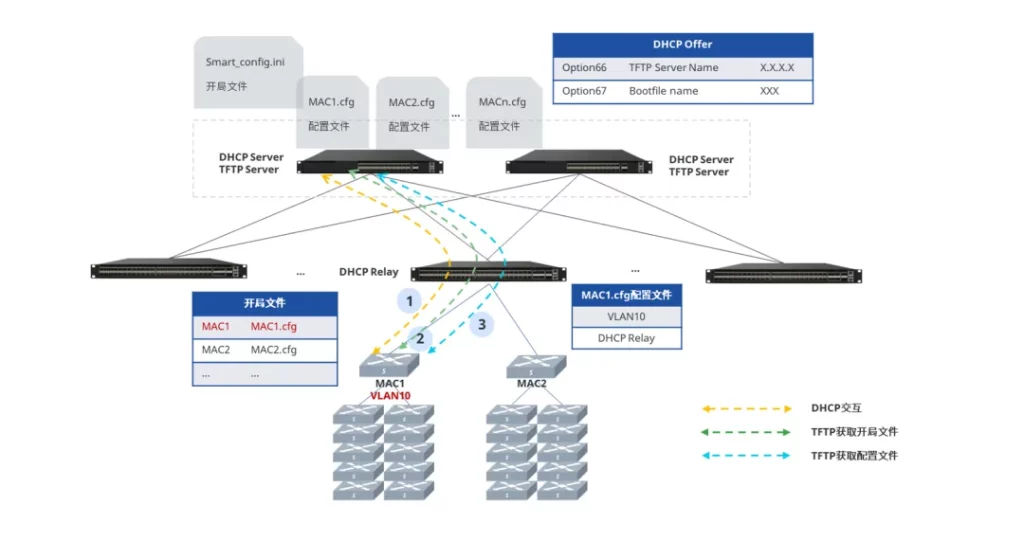
- 被管理交换机通过发起DHCP请求获取IP地址、配置文件所在的TFTP服务器地址和开局文件名称
- 被管理交换机根据 DHCP 服务器给出的地址与TFTP Server 建立联系,获取开局文件(
Smart_config.ini)并解析,开局文件中包含与此设备MAC匹配的唯一配置文件名称(MACn.cfg) - 被管理交换机根据解析出的配置文件名称再次向TFTP Server 获取对应的配置文件并应用
配置文件为每台交换机分配了 VLAN,并配置好 DHCP Relay使其下接入的终端也能顺利通过 DHCP 过程获取到 IP 地址。
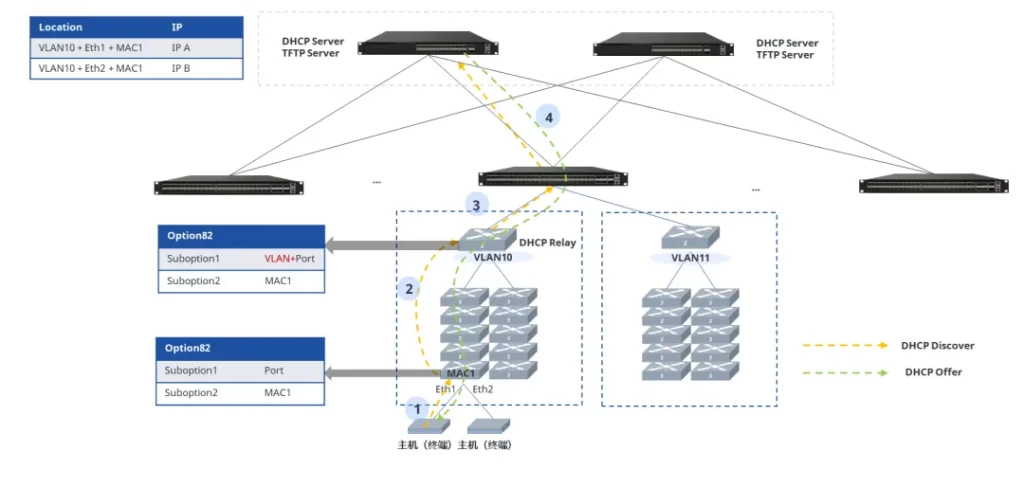
- 主机通过DHCP请求获取IP地址
- 主机所连接的被管理交换机分别在 DHCP discover 报文 Option 82 字段中加入自身MAC地址和连接终端的端口号、VLAN号,用来标识该主机位置
- Spine 交换机上DHCP Server 根据 Option82 字段中的信息,匹配到唯一的IP地址并回复给接入主机
- 主机按照规划获得到与位置对应的 IP 地址
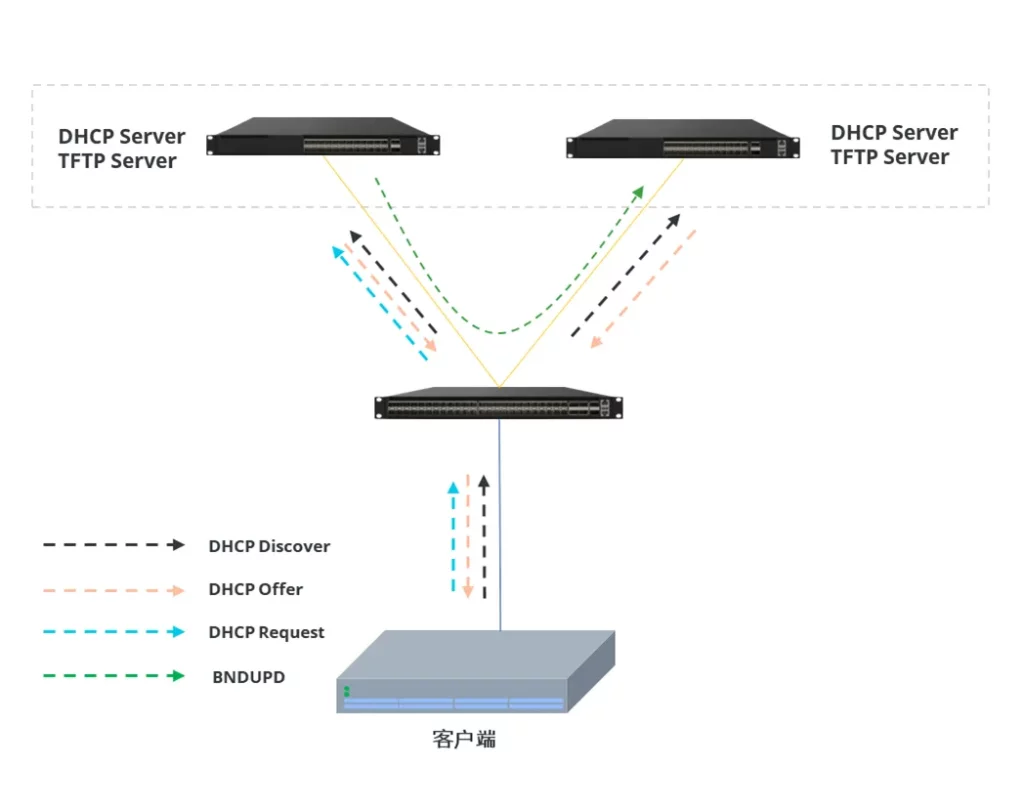
上述方案中,管理交换机和上行链路之外,DHCP server 也支持双活部署以提升业务可靠性:两台Spine交换机上都分别运行了DHCP服务器,并进行地址分配等相关信息的同步,当其中一台服务器出现故障,另一台服务器将继续从地址池中续订租约
正常情况下:两台DHCP服务器均收到DHCP请求,并向客户端发送IP地址,客户端挑选一条回复,收到回复的服务器并向对端设备同步地址信息,客户端到达任一个服务器均可以续租。
若某台DHCP服务器出现故障:客户端获取地址时由当前存活的DHCP服务器响应请求,根据客户端信息和地址池状态分配地址,交互完成后,本地更新租约信息,客户端的续租请求仅向存活服务器发起。
- bilibili
- 头条号
科创型企业是数字化时代的核心引擎,其发展势头与竞争力,取决于底层网络架构的稳定与高效。这类企业通常依托两大核心网络——承载关键业务的服务器区和支持高效接入的办公网(采用“混合组网”架构),以满足高性能与高可靠性的双重需求。
- 服务器区Leaf通过MC-LAG技术与服务器相连,实现服务器双活接入;
- 办公网与服务器区之间则通过全三层路由实现灵活可控的互访与高效的传输路径。
在网络规模持续扩张的背景下,“MC-LAG + 全三层”架构虽能提供高可用和灵活的路由能力,但其运维复杂度可想而知。传统网络控制器手工配置、分散管理和被动运维的模式,已成为制约企业业务敏捷发展与稳定安全的瓶颈。
面对科创型企业提出的“混合组网”需求,星融元基于TIP OpenWiFi框架构建的园区网络控制器(ACC)在规划拓扑环节新增了“混合组网”场景,显著简化了传统“MC-LAG + 全三层”架构的部署与运维流程。
在已做好网络规划的前提下。
第1步,设备导入
根据模板规范填写设备信息并上传,完成后即可在库存信息界面查看已创建的设备。
第2步,规划拓扑
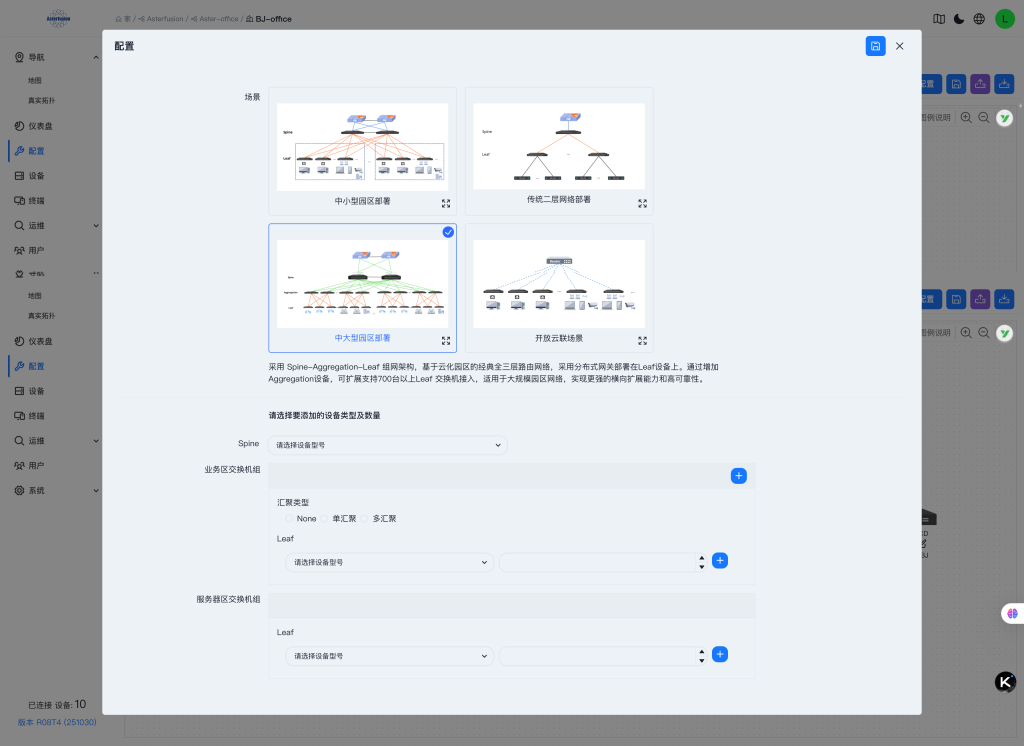
ACC – 拓扑场景规划
选择“混合组网场景”模板。
按角色(Spine/Aggregation/Leaf)分配设备并填写互联接口,控制器会根据填写内容生成网络拓扑。
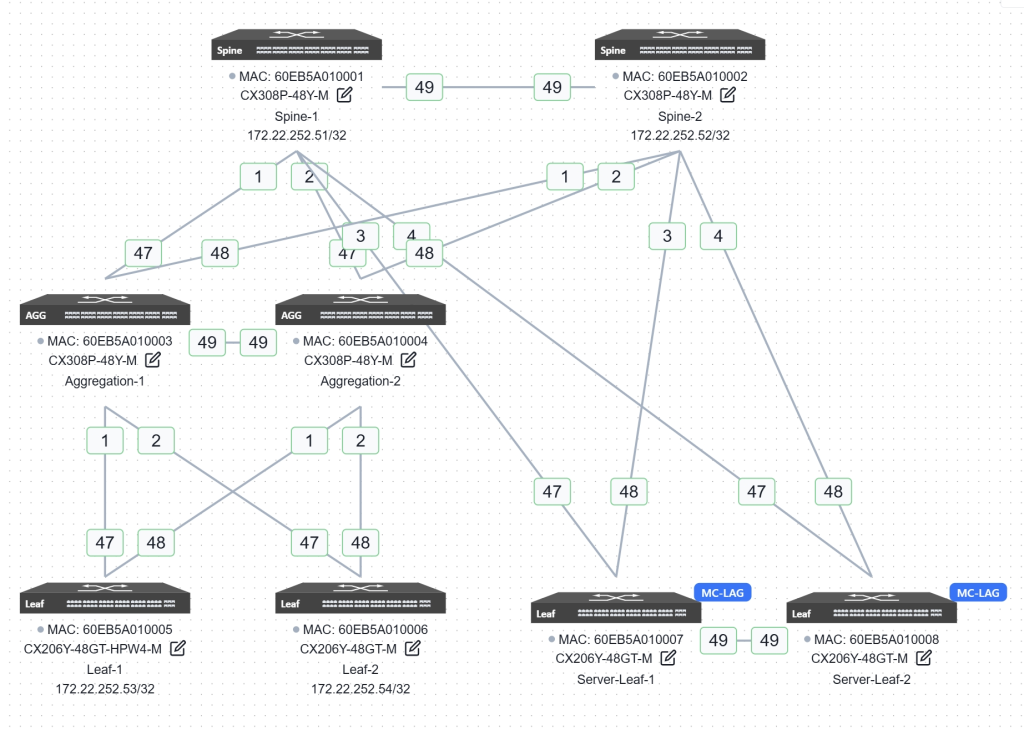
ACC – 拓扑生成
Leaf1与Leaf2作为分布式网关,Leaf1负责连接AP及无线终端,Leaf2负责连接有线终端。通过横向扩展汇聚层(Agg1、Agg2)实现高可用与负载均衡,Spine与汇聚设备间均运行MC-LAG,以保障链路可靠性。
Server-Leaf1与Server-Leaf2通过MC-LAG技术以纯二层模式连接服务器,网关集中部署在Spine设备上,简化服务器区网络管理并提升转发效率。
第3步,基础网络配置
ACC通过图形化界面,极大地简化了传统控制器上需要复杂命令行操作的MC-LAG(跨设备链路聚合)与全三层路由混合组网配置。
- 业务区网络配置
这一步主要针对园区网络中的汇聚层设备,为其实现带内管理和MC-LAG功能奠定基础。如:管理地址段、PeerLink VLAN、PeerLink IP……
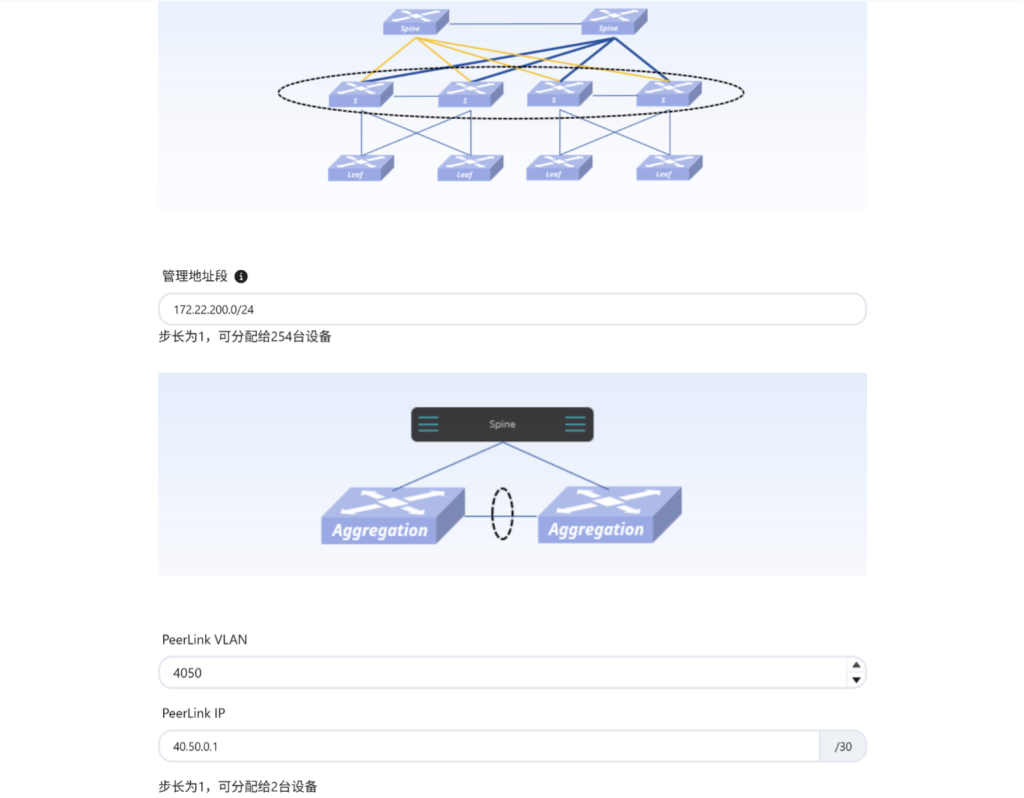
ACC – 业务区网络配置
- 服务器区网络配置
针对服务器区的Leaf设备,配置内容与业务区类似,为Leaf设备提供带内管理能力,并为其Peer-Link接口做好准备。
![]()
ACC – 服务器区网络配置
- 出口路由配置
确保整个园区网络能够通过Spine设备与外部网络进行通信。
第4步,业务配置
- 有线业务配置
默认业务区的主要在Leaf1和Leaf2设备上进行,为不同业务区域定义VLAN、网关、DHCP中继及PoE供电等参数。
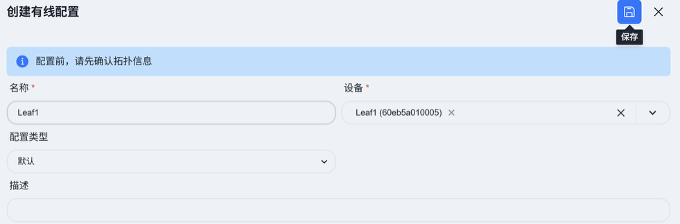
ACC – 有线业务配置
为服务器区Leaf交换机创建链路聚合组及业务VLAN,在Spine设备上创建与Leaf设备对应的VLAN。
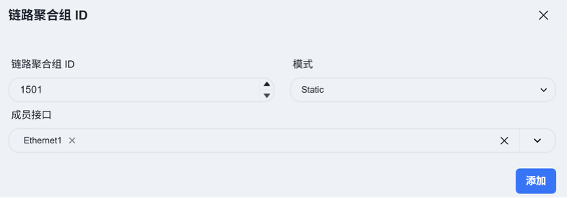
- 无线业务配置
管理员可以在此集中管理无线接入点(AP),配置SSID、安全策略、有线终端接入方式等,并利用标签系统实现配置的自动匹配与下发。
- DHCP Server
在Spine设备上配置DHCP Server,为整个园区网络中的终端设备(如AP、无线终端、有线终端)自动分配IP地址,是实现网络自动化管理的核心环节。
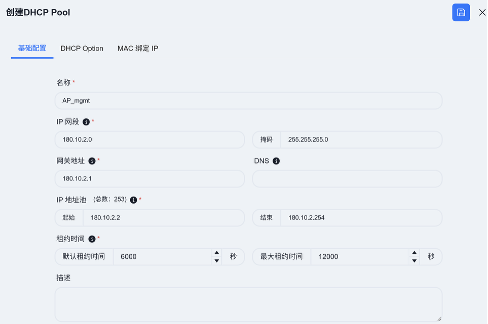
ACC – 配置DHCP Server
第5步,配置下发
在完成所有网络与业务配置后,一键向交换机批量推送基础网络、有线业务及DHCP配置,而AP在上线后则根据预分配标签自动拉取对应配置,实现全自动化部署,彻底告别了传统的人工逐台配置模式。

ACC – Dashboard
ACC通过图形化界面,实现了网络状态的全面可视化,帮助运维人员直观地掌握整个网络的运行状况。

ACC – 主动告警
还能够实时监控设备的关键服务状态。一旦发现异常,会立即自动生成包含详细信息的告警,并根据告警的严重程度,精准地推送给相应的人员,从而实现高效、主动的运维管理。
同时,智能巡检功能支持对巡检项目进行精细化配置,确保运维工作的全面性和准确性。
- Spine-leaf架构
有线网络采用简洁、高可靠的 Spine/Leaf 架构运行全三层网络,天然无环路,隔绝广播风暴,同时支持按需横向扩展满足未来5-8年的扩容升级需求;下一代园区网络,用Leaf/Spine架构替代传统三层拓扑 下一代园区网络,用Leaf/Spine架构替代传统三层拓扑
- 分布式网关
无线网络则借助分布式网关设计,提供超大漫游域的无缝漫游,实现跨楼栋漫游不中断,网随人动,策略随行,兼顾安全和便利性;园区网前沿实践:基于开放网络架构的云化路由设计 园区网前沿实践:基于开放网络架构的云化路由设计
- 多元化认证方式
智能地自动识别接入网络的终端类型,并根据其属性和场景,自动匹配并执行最合适的认证方式,如802.1X或Portal认证,从而实现高效、安全且体验友好的网络准入控制。
- bilibili
- 头条号
传统分流器 / TAP 一般是通过 Web 界面手动调整配置,而实际业务中成千条配置的周期性调整给一线运维人员造成了极大的负担。
举例来说,传统方式下假设我们要配置 10 台 NPB 专用设备,为其更新 VLAN 镜像规则与目标端口映射,我们需要依次登录这 10 台设备,打开 Web 界面进行手动添加/修改规则 1000+ 条,然后检查、保存,一通操作耗时动辄数小时,甚至一整天。
随着近些年的产品迭代,虽然部分 NPB 设备已经可以做到集群内的批量配置同步,但无论是在 Web 界面上如何优化,只要运维模式依旧是手工完成的拖拉点拽,还是免不了耗时耗力易出错。
关于星融元 NPB 2.0 ,请参阅:无需TAP/分流器,SONiC上跑容器,交换机秒变NPB
在 NPB2.0 中,我们已抛弃了过往使用专用设备的方案,而是在交换机上容器化运行 NPB 组件来实现相应功能。不光如此,我们也支持用 Ansible 去调用 sonic-cli 来批量配置新一代基于SONiC的 NPB 设备(包括园区和数据中心场景),实现快速、标准化、零差错的策略部署。
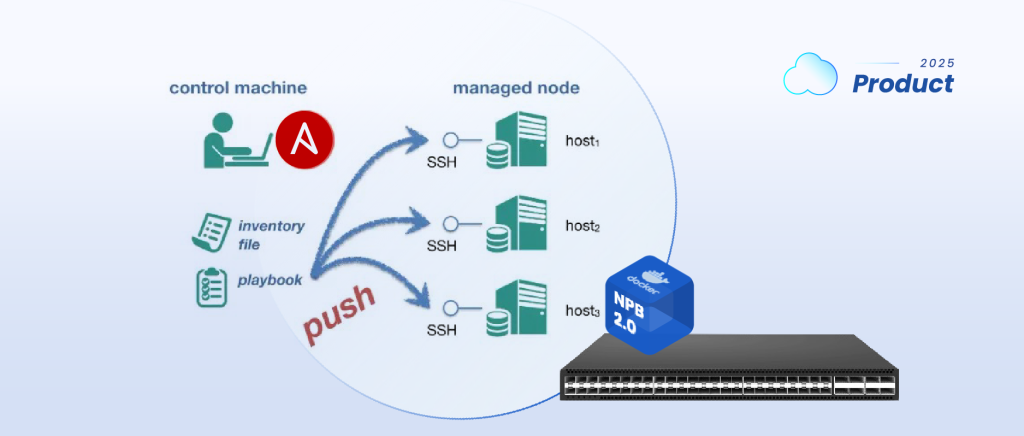
Ansible是一款基于 Python 开发的开源自动化运维工具,由 Red Hat 公司主导维护,其诞生背景源于云计算时代下IT基础设施的规模化与动态化,传统手工运维方式难以应对频繁的配置变更和批量部署需求。
该工具的核心特点是基于agentless和声明式模型,借助 SSH 或 WinRM 协议直接管理节点,避免了客户端代理的安装和维护成本,其大致的交互模式为 用户通过YAML语言编写 Playbook定义目标状态,Ansible 自动将模块推送到远程节点执行配置。
由此我们可以建立标准化流程,将重复性运维操作转化为可版本控制的自动化任务,显著提升网络运维效率与可靠性。
目前 Ansible 已成为 DevOps 和云原生技术栈中的重要组件,帮助运维工程师跨平台配置统一管理各大基础设施,包括网络设备、云主机、容器集群等等。
星融元的 Ansible 官方模块集合 Asterfusion AsterNOS Collection 已完成cliconf 插件和asternos_command 模块的开发适配,这些模块可在 Playbook 中直接调用,然后在 Ansible 的 inventory 文件中定义 SONiC 设备并为其设置正确的连接变量。
运维人员根据实际需求使用上述的 CLI 模块编写 Playbook 任务并运行,即可快速完成 NPB 策略下发、ACL 更新、端口配置等批量操作,几秒钟内即可将规则同步到所有 NPB 设备(SONiC 设备),并在 Git 中追踪变更历史。
pip3 install ansible
[defaults]
inventory = inventory #指定为’inventory’文件
host_key_checking = False
retry_files_enabled = False
gathering = explicit
stdout_callback = yaml
[sonic]
sonic1 ansible_host=192.168.1.x ansible_user=x ansible_password=x
# group_vars/sonic.yml
host: “{{ ansible_host }}”
user: “{{ ansible_user }}”
password: “{{ ansible_password }}”
以下为两组示例的命令行配置
config_vlan_cmd: |
configure
vlan 3003
end
exit
config_acl_test_cmd: |
configure
access-list L3 test1 ingress priority 500000
rule 1 packet-action permit redirect-action ethernet 11
exit
interface ethernet 11
acl test1
end
exit
不需要改动,用来调用设备的 CLI(代码略)
新增两个task分别调用config_acl_test_cmd和config_vlan_cmd
—
– hosts: sonic
gather_facts: no
tasks:
– name: Push klish commands
sonic_klish:
commands: “{{ config_acl_test_cmd }}”
host: “{{ host }}”
user: “{{ user }}”
password: “{{ password }}”
delegate_to: localhost
register: result
– name: Push klish commands 1
sonic_klish:
commands: “{{ config_vlan_cmd }}”
host: “{{ host }}”
user: “{{ user }}”
password: “{{ password }}”
delegate_to: localhost
register: result
– debug: var=result.stdout
[root@localhost ansible]# ansible-playbook -v site.yml
Using /home/ryan/ansible/ansible.cfg as config file
打印如下,则执行完毕:
PLAY [sonic] *********************
TASK [Push klish commands] ****************
changed: [sonic1 -> localhost] => changed=true
stdout: |-
Warning: Permanently added ‘192.168.1.102’ (RSA) to the list of known hosts.
…Entering cli view, please wait…
stty: ‘standard input’: Inappropriate ioctl for device
stty: ‘standard input’: Inappropriate ioctl for device
sonic# configure
sonic(config)# access-list L3 test1 ingress priority 500000
sonic(config-L3-acl-test1)# rule 1 packet-action permit redirect-action ethernet 13
sonic(config-L3-acl-test1)# exit[J
sonic(config)# interface ethernet 13
sonic(config-if-13)# acl test1[J
sonic(config-if-13)# end[J
sonic# exit
stdout_lines: <omitted>
TASK [debug] ***********************
ok: [sonic1] =>
result.stdout: |-
Warning: Permanently added ‘192.168.1.102’ (RSA) to the list of known hosts.
…Entering cli view, please wait…
stty: ‘standard input’: Inappropriate ioctl for device
stty: ‘standard input’: Inappropriate ioctl for device
sonic# configure
sonic(config)# access-list L3 test1 ingress priority 500000
sonic(config-L3-acl-test1)# rule 1 packet-action permit redirect-action ethernet 13
sonic(config-L3-acl-test1)# exit[J
sonic(config)# interface ethernet 13
sonic(config-if-13)# acl test1[J
sonic(config-if-13)# end[J
sonic# exit
TASK [Push klish commands] *****************
changed: [sonic1 -> localhost] => changed=true
stdout: |-
Warning: Permanently added ‘192.168.1.102’ (RSA) to the list of known hosts.
…Entering cli view, please wait…
stty: ‘standard input’: Inappropriate ioctl for device
stty: ‘standard input’: Inappropriate ioctl for device
sonic# configure
sonic(config)# vlan 3003
sonic(config-vlan-3003)# end[J
sonic# exit
stdout_lines: <omitted>
TASK [debug] *********************
ok: [sonic1] =>
result.stdout: |-
Warning: Permanently added ‘192.168.1.102’ (RSA) to the list of known hosts.
…Entering cli view, please wait…
stty: ‘standard input’: Inappropriate ioctl for device
stty: ‘standard input’: Inappropriate ioctl for device
sonic# configure
sonic(config)# vlan 3003
sonic(config-vlan-3003)# end[J
sonic# exit
PLAY RECAP ************************
sonic1 : ok=4 changed=2 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
- bilibili
- 头条号
在数据中心智算场景中,除了 GPU 本身的性能和调度算法,集群的整体性能很大程度上还取决于底层通信栈的效率。
智算集群的底层通信机制可分为机内通信和机间通信两大类。机内通信指在一台服务器内部,各个计算部件之间的数据交换,最典型的就是一台AI服务器内部,多个GPU(例如8张A100/H100卡)之间、GPU与CPU之间的高速通信。机间通信,则是让成百上千台AI服务器通过高性能网卡和交换机实现互联(scale-out网络)进行数据交换和协同工作,将算力规模成倍放大。
从“机内通信”的 NVLink/PCIE 通道,到“机间通信”所经过的网卡、交换机的每个端口,以及每个无损传输队列,都必须完成精密高效的协同运作,任何一个环节成为瓶颈都会导致昂贵的计算资源(GPU)处于“等待数据”的空闲状态,极大降低整个集群的算力利用率。
作为IB网络强有力的竞争者,RoCEv2拥有高性能、兼容标准以太网生态、成本可控、扩展性强、支持多租户与虚拟化等优点,但其对网络无损有严格要求,配置不当很可能会放大拥塞,例如 PFC、ECN、Buffer 滞留等RoCE参数配置不合适,对外都是笼统表现为通信异常,网络性能下降,而逐项排查的操作相当繁琐。
为解决 RoCE 网络监控运维上的不便,此前我们已发布用于监控星融元 RoCE 交换机各项网络配置和状态指标的 AsterNOS Exporter 和 RoCE exporter以及配套的一系列高效运维工具。参考阅读:一文解读开源开放生态下的RDMA网络监控实践
现在我们新推出了 EasyRoCE-NE (NIC Exporter)网卡状态采集工具,不光是交换机和光模块, 服务器网卡信息也可一并纳入统一监控平台。
NE 是 EasyRoCE 工具集中针对服务器网络监控部分的组件,主要分为 Exporter 客户端(NIC Exporter)code>和监控面板自动化创建程序(NIC Generator)两部分。
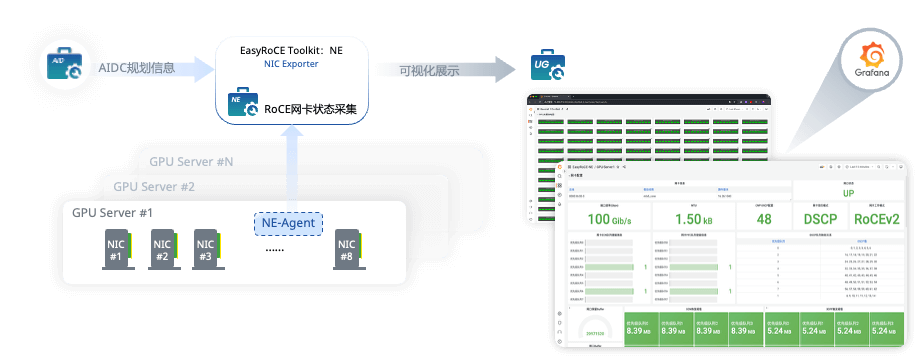
NIC Exporter 运行在 GPU 服务器内部,主要工作是采集服务器网卡(例如 Mellanox NIC )的配置以及流量状况,将其转换为 Prometheus 能理解的标准格式并通过 HTTP 接口暴露。
NIC Generator 运行在部署管理节点(安装了星融元 EasyRoCE Toolkit 的服务器),该程序从EasyRoCE-AID(配套的数据库组件,什么是AID工具?)读取GPU服务器的IP信息,自动在EasyRoCE-UG(Unified Glancer)创建可视化监控面板,把客户端采集的信息一站式展示出来。
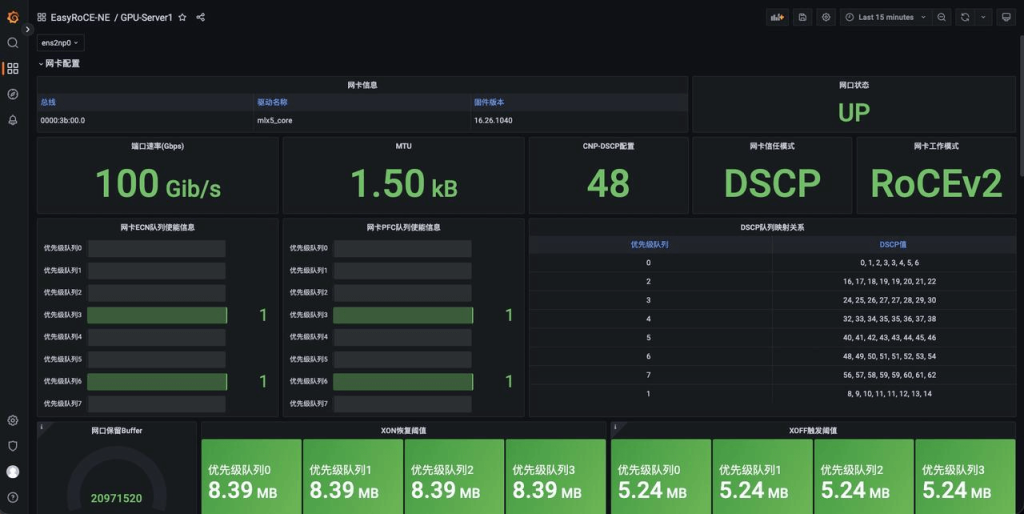
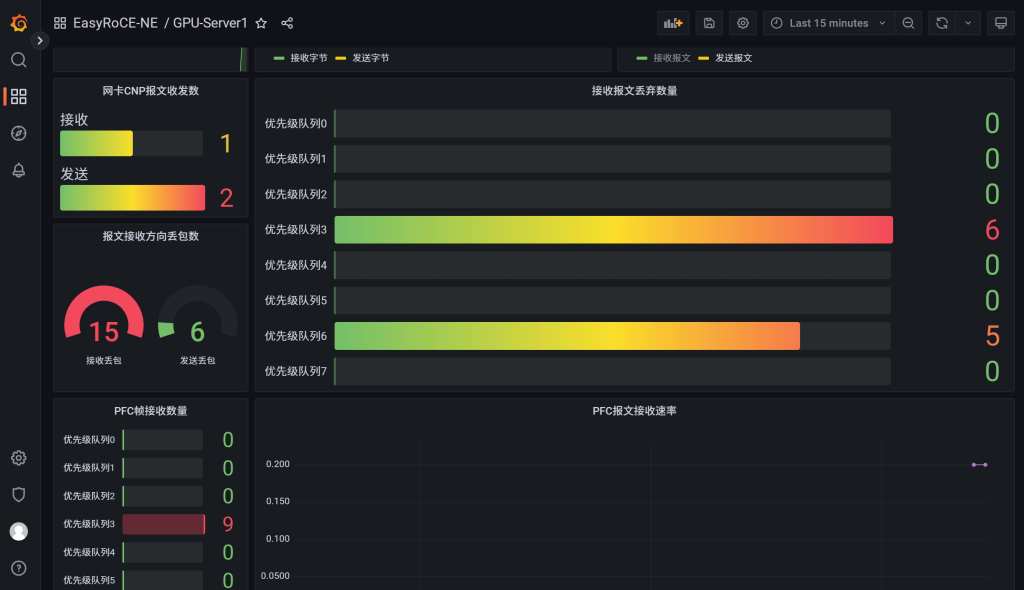
- 网卡配置:网卡驱动固件版本、名称,运行状态
- RoCE配置:DSCP, TOS, ECN, PFC, CNP 报文DSCP值
- 网卡流量:网口带宽,收发速率,丢包统计
- ECN标记数,CNP收发统计,PFC收发帧数统计
nic_exporter.tgz、nic_exporter,请联系销售/售前人员获取。
用户需要事先通过EasyRoCE-AID完成网络规划,并将其上传到服务器的EasyRoCE Toolkit目录下。
将nic_exporter上传到GPU服务器中并后台启动,默认监听9105端口。
chmod +x nic_exporter
nohup ./ nic_exporter &
将nic_exporter.tgz上传到服务器的 EasyRoCE Toolkit 目录下并解压,解压后目录结构如下:
.
├── ne_dashboard.json #UG面板文件
├── nic_generator.py #启动脚本
└── requirements.txt #依赖
为了避免影响服务器自身的python环境,推荐使用venv 作资源隔离:
python -m venv .venv
source .venv/bin/activate
pip install -r requirement.txt
./nic_generator.py
打印如下即成功创建面板:
Pushing dashboard to Grafana...
Dashboard pushed successfully: {'id':116, 'slug': 'gpuserver8',
'status': 'success', 'uid': 'easyroce-ne-gpu-server8',
'url': '/d/easyroce-ne-gpu-server8/gpu-server8', 'version':
4}All dashboards processed. Total: 8.
Url: http://10.106.219.5:3000/dashboards/f/XXXXXXX
- bilibili
- 头条号
PTP,简写自 Precision Time Protocol(精确时间协议) 。顾名思义,PTP 用于为时间同步敏感的系统和应用程序在局域网或广域网上创造高精度时间同步的环境,往往需要通过硬件辅助才能实现。
PTP 在 IEEE 1588 标准中定义,目前已发展到的 IEEE 1588 v2 具有双向通道、纳秒级精度、广泛适应不同接入环境。
PTP 网络的基本架构如下图所示:所有时钟都会按照主从(Master-Slave)关系组织在一起,以GMC为起始点,向各节点逐级同步时钟。
需要注意的是,这种主从关系是相对而言的,因为一些设备不但会从上层设备同步时钟(此时作为从节点/时钟),也会向下层设备发布时钟(此时作为主节点/时钟)。
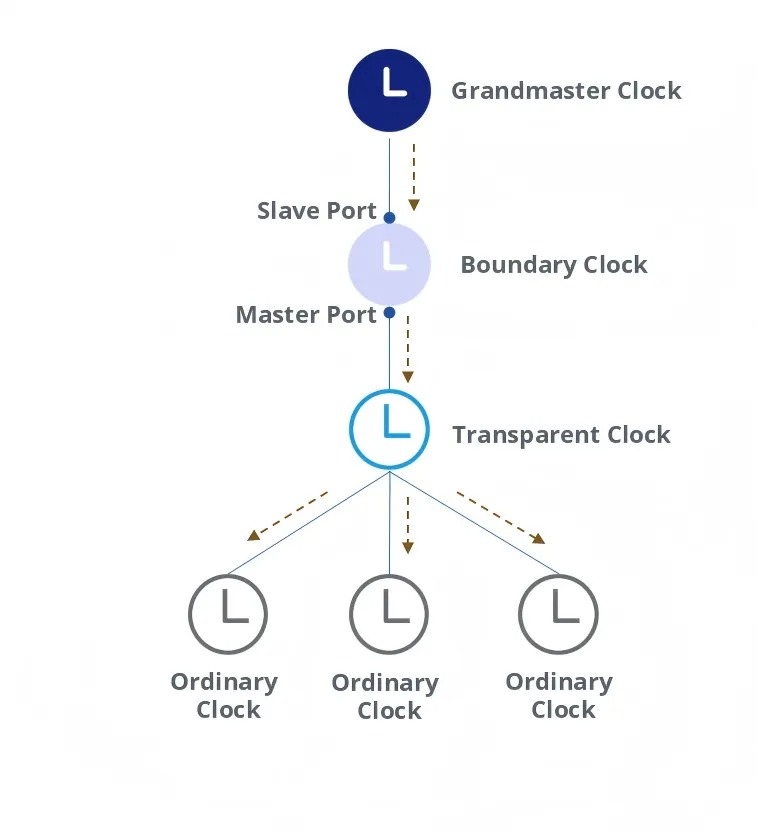
- Grandmaster Clock:(GMC,大师钟)最高级别的时钟,作为时钟源为整个PTP域提供参考时间。设备一般需要具有GNSS(全球导航卫星系统,例如GPS,北斗等)接收器。GMC的产生方式,可以是手工配置一个静态的,也可以通过最佳主时钟 BMC(Best Master Clock)算法动态选举。
- Boundary Clock(BC,边界时钟):提供两个或多个物理端口参与PTP域的时间同步,其中一个端口与上游设备同步时间,其他端口将时间发送给下游设备。
- Transparent Clock(TC,透明时钟):不与其他设备同步时间,仅在其 PTP 端口之间转发 PTP 消息并测量消息的链路延迟。
- Ordinary Clock(OC,普通时钟):仅提供一个物理端口参与PTP域内的时间同步,通常用作网络的终端节点,连接到需要同步的终端设备。
设备上运行 PTP 协议的端口称为 PTP 端口,其中发布同步时间的端口称为“主端口(Master Port)”,接收同步时间的端口则称为“从端口(Slave Port)”。此外,也有既不接收也不发送同步时间的“被动端口”(Passive Port),它只存在于边界时钟(BC)上。
实现时钟同步主要包括3个步骤:
- 建立主从关系,选取大师时钟(GMC)、协商端口主从状态等。
- 频率同步(Frequency synchronization),从节点时间与主节点同步,信号之间保持恒定相位差。
- 相位同步(Phase synchronization),从节点时间与主节点同步,信号之间相位差恒定为零。
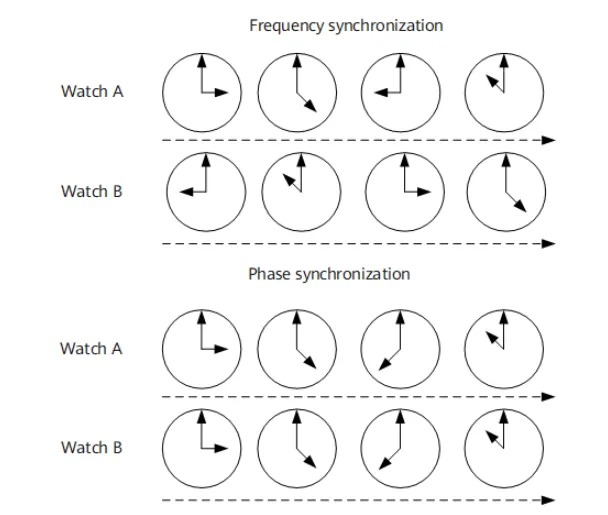
要实现高精度时间同步,很关键的一点是让“从时钟”通过 PTP 报文中携带的时间戳信息,计算与“主时钟”之间的偏移和延时,并据此调整本地时钟来实现时间同步。
根据报文是否携带时间戳,我们可以将PTP报文分为两类:
- 非时间概念报文,进出设备时不会打上时间戳;用于 PTP 网络系统主从关系的建立、时间信息的请求和发布,
- 时间概念报文,进出设备端口会打上精确时间戳;PTP 网络系统会根据报文携带的时间戳计算链路延迟。该类报文包含以下四种:Sync、Delay_Req、Pdelay_Req和Pdelay_Resp。
PTP 网络如何从 PTP 报文中计算得出偏移和延时信息呢?这里就必须说到延迟测量机制,主要有“端到端(E2E)”和“点对点 (P2P) ”两种。
E2E 机制下,中间设备(E2E TC)在转发计时消息的同时,会添加一个停留时间 (rt) ,E2E 机制使用双向消息计算总路径延迟作为时间补偿。
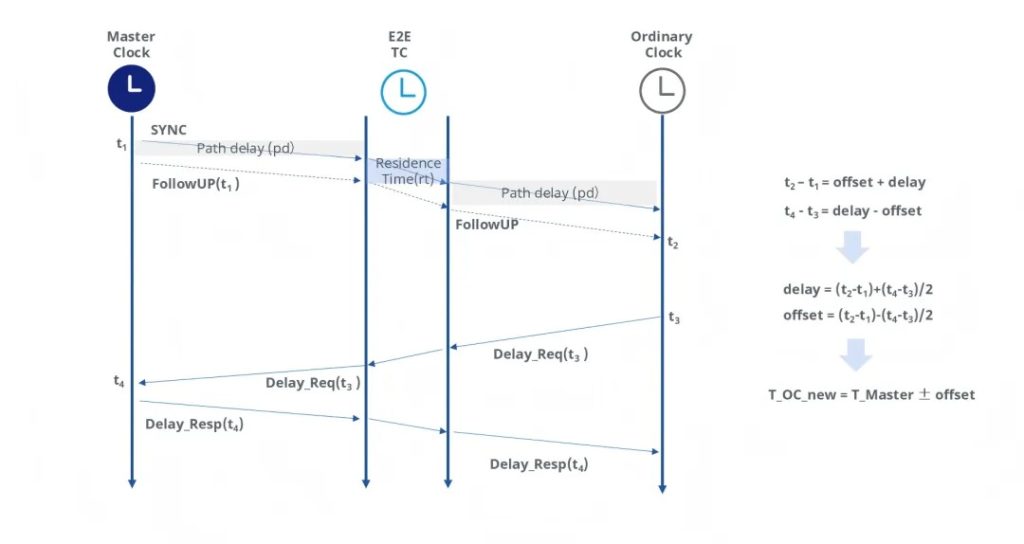
计算公式:
t₂ – t₁ = 偏移 + 延迟
t₄ – t₃ = 延迟 – 偏移
延迟 = (t₂-t₁)+(t₄-t₃)/2
偏移量 = (t₂-t₁)-(t₄-t₃)/2
T_OC_new = T_Master ± 偏移量
不同于 E2E 机制,P2P 的测量机制在会在每一跳交换消息以测量链路延迟,从而实时测量并纠正每跳延迟。
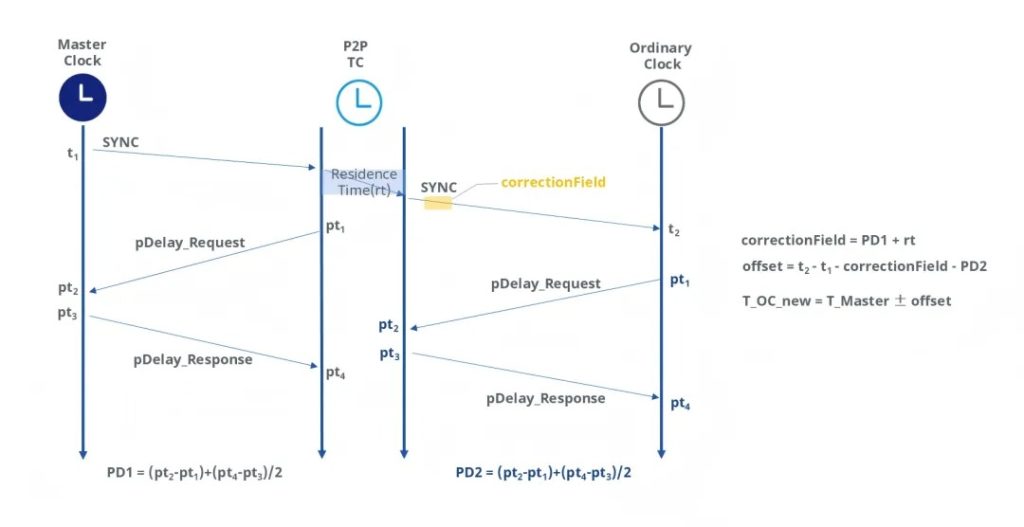
计算公式:
PD1 = (pt2-pt₁)+(pt₃-pt2)/2
PD2 = (pt₄-pt₁)+(pt₄-pt₃)/2
校正字段(correction field) = PD1 + rt
偏移量 = t₂ – t₁ – 校正字段 – PD2
T_OC_new = T_Master ± 偏移量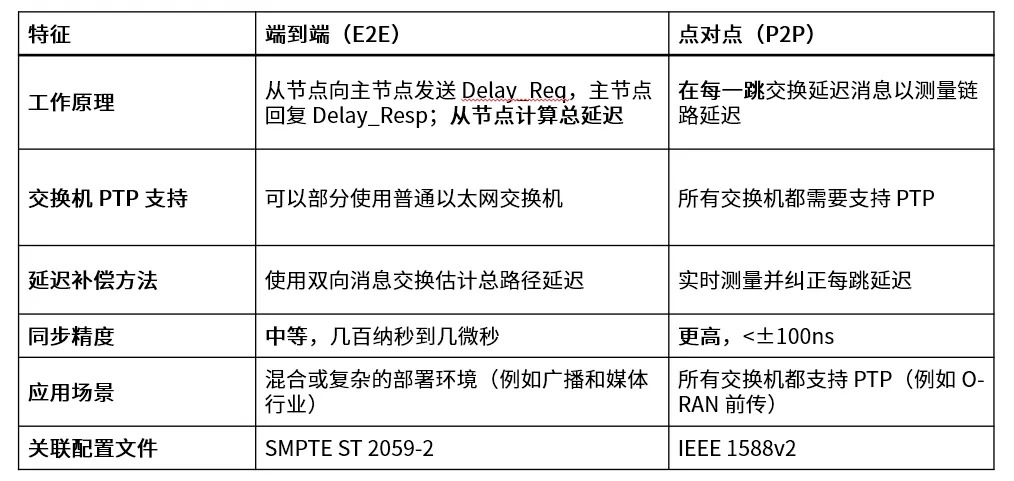
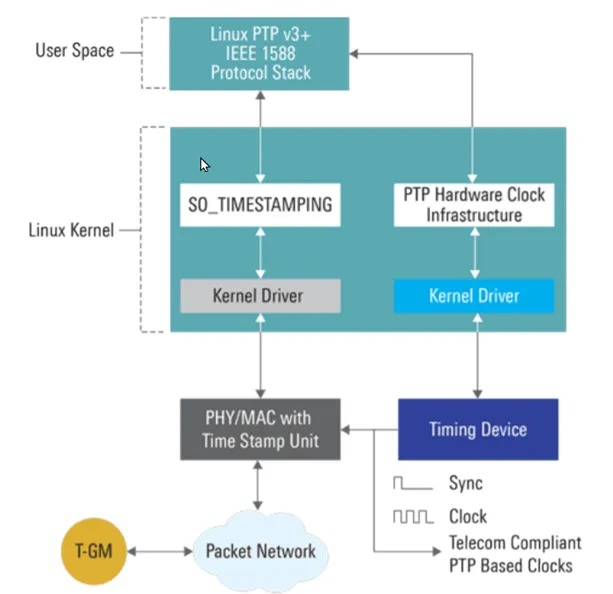
在 Linux 中,PTP 协议的实现称为 Linux PTP,它基于 IEEE 1588 标准,软件包有 ptp4l 和 phc2sys。
我们基于 ptp4l 和 Linux 网卡做了测试,可以看到:同步精度分布在 1000ns(1μs)以内,并且存在 8000ns(8μs)以上的不稳定跳变。
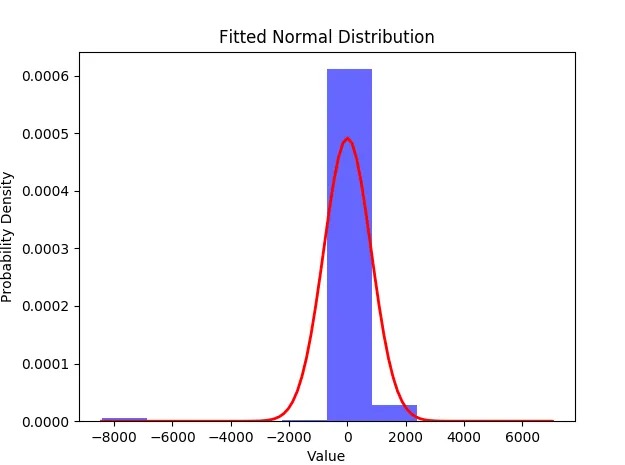
在没有额外调优工作的前提下,这样的同步精度对于个人爱好者或一般实验环境或许足够,但离企业级商用场景还远远不够。
作为参考,此处列出 ITU(国际电信联盟)提出的时间同步能力分类,
- A类:时间误差≤50ns,适用于对同步精度要求较低的一般电信网络。
- B类:时间误差≤20ns,适用于更严格的时间同步场景,如5G基站同步。
- C类:时间误差≤10ns,主要用于对同步精度要求极高的场景,例如5G前传。
深入研究上述原理和机制后,我们发现 SONiC 开放架构不但能够灵活地满足各种时间同步要求,还能为广大客户提供自由选择,消除供应商锁定。
早在2024年上半年,星融元就引领社区开始着手在 SONiC 中实现 PTP ,并优化其在企业级 SONiC 发行版 AsterNOS 上的性能。
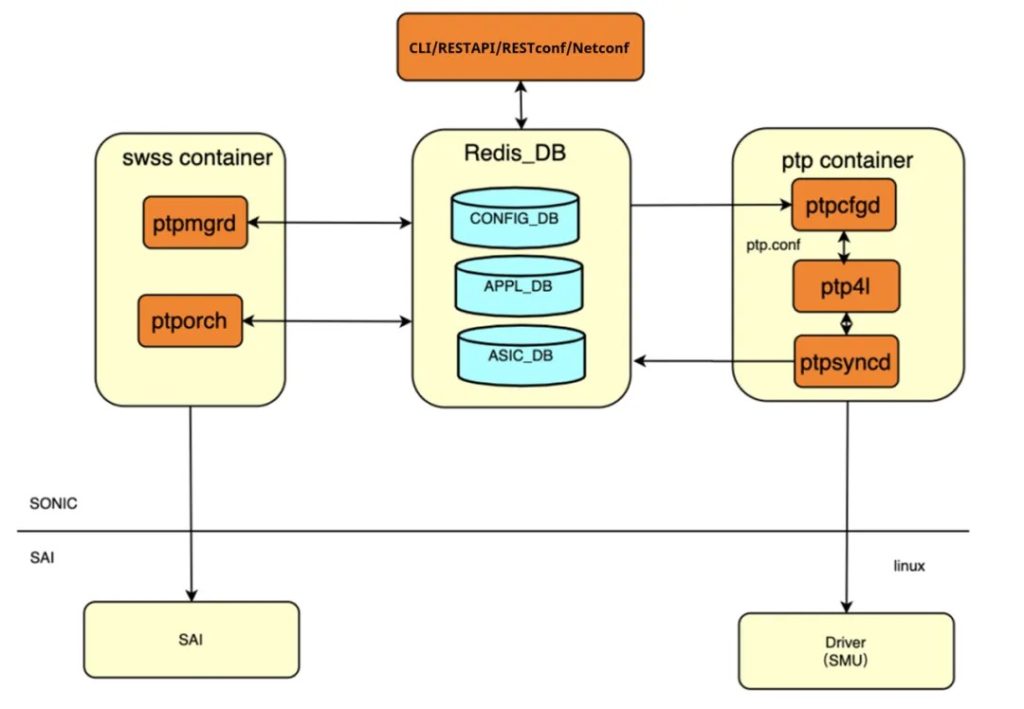
下图是 AsterNOS 内的 PTP 子系统示意图,包含一个运行 Linux PTP / ptp4l 并与 RedistDB 和底层硬件驱动程序交互的 PTP 容器。此外这套系统还支持多种网络管理协议,例如 RESTful API、RESTconf 和 Netconf,给到更优的系统集成和互操作性。
通过硬件加速和软件算法优化的星融元 PTP 交换机的时间同步精度分布在 20ns 以内,并且不同延迟测量模式获得的偏差结果几乎相同。
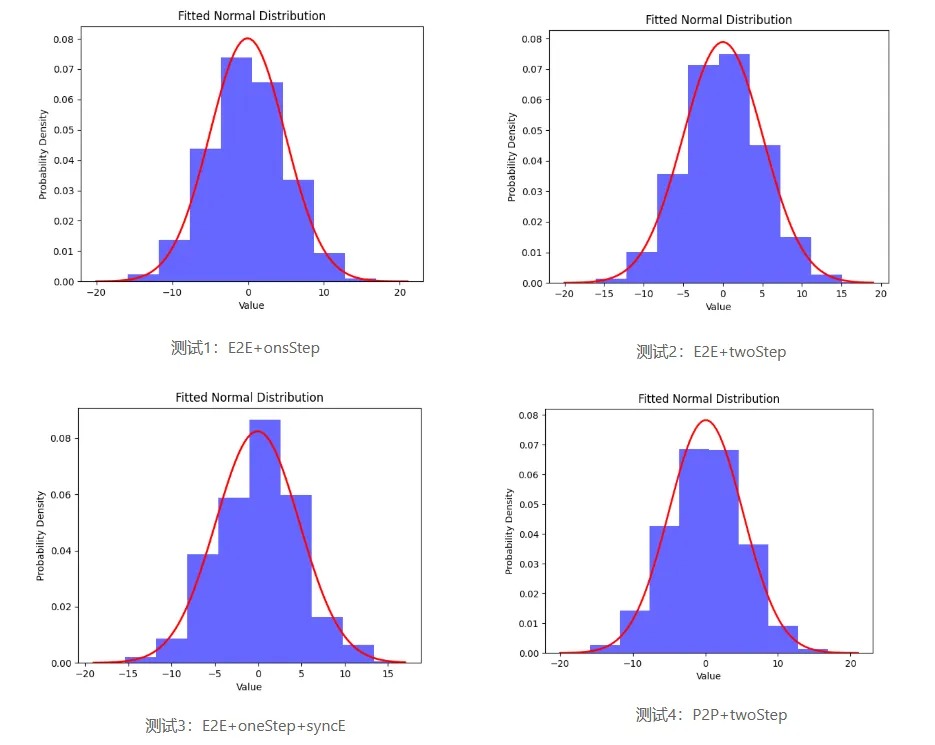
- one-step:Sync 报文带报文发送时刻的时间戳
- two-step:Sync 报文不带报文发送时刻的时间戳,只记录本报文发送时的时间,由Follow_Up报文带上该报文发送时刻的时间戳。
目前,星融元 CX-M 交换机产品已经系列化地支持了 PTP ,兼容 E2E 和 P2P 模式和多种配置文件。
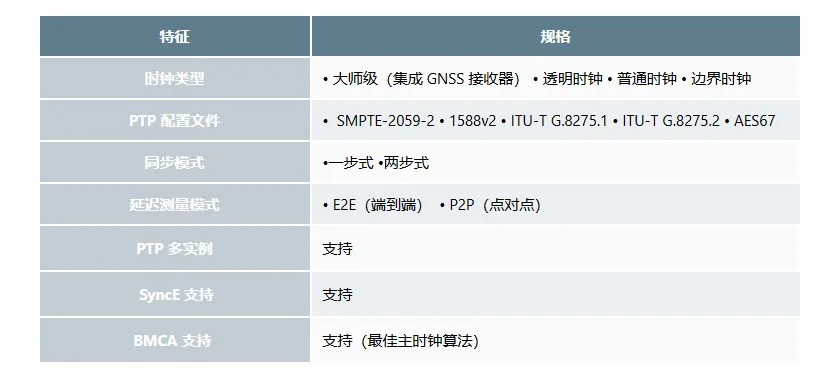

可在设备模拟器体验 PTP 功能特性 👉
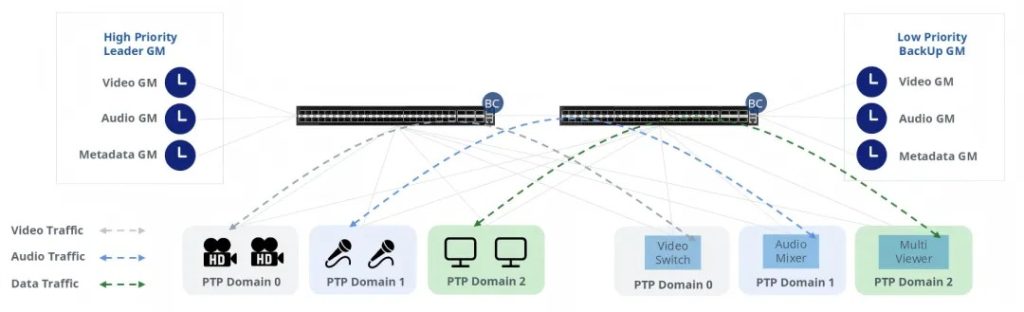
该图展示了一个典型广播和媒体网络拓扑,采用星融元的 PTP 交换机提供多个 PTP 域和冗余时钟源(主备切换),为音频和视频分配单独的域号,在网络中实现 20ns 时间同步精度,确保音频、视频和其他数据流量的无缝对齐。