🌞欢迎来到人工智能的世界
🌈博客主页:💌欢迎关注🎉点赞👍收藏⭐️留言📝
🌟本文由卿云阁原创!
🌠本阶段属于练气阶段,希望各位仙友顺利完成突破
📆首发时间:🌹2025年5月15日🌹
✉️希望可以和大家一起完成进阶之路!
🙏作者水平很有限,如果发现错误,请留言轰炸哦!万分感谢!

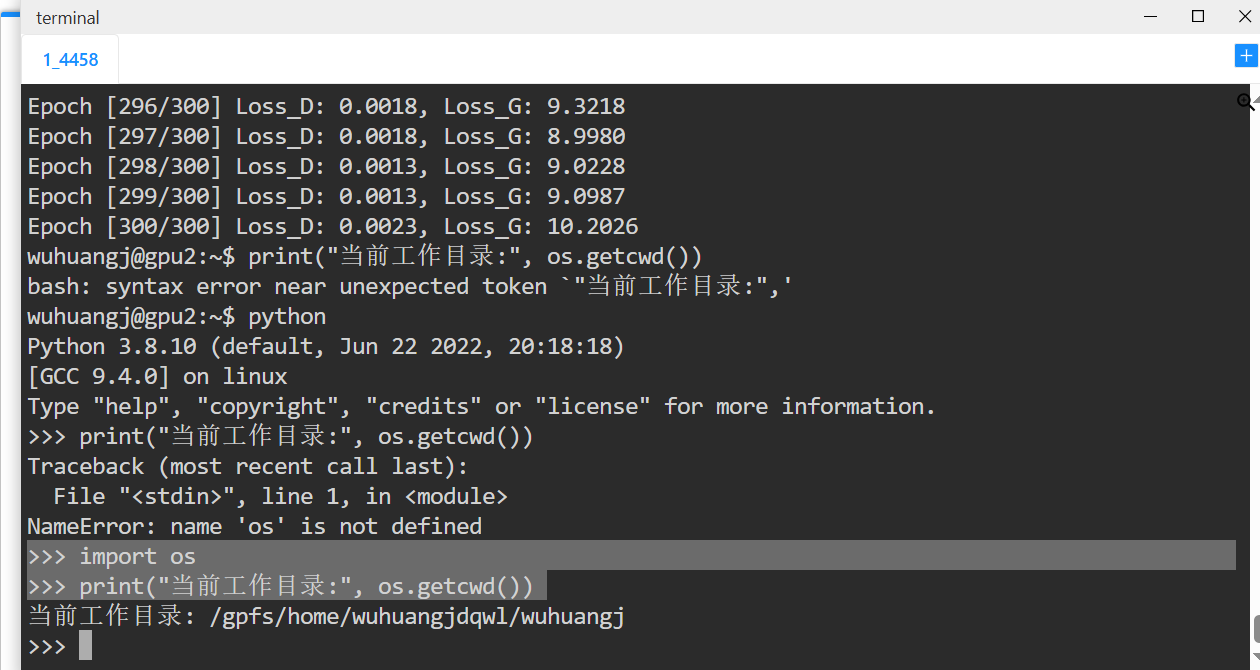
运行结果可能保存在哪里?
>>> import os
>>> print("当前工作目录:", os.getcwd())在命令行中运行这个代码得到运行结果保存的位置:
如何运行程序?
【注意点1】:有的项目很多都是很保密的,管理员是不允许用自己电脑连接的所以所以必须使
用,这个时候整个项目的运行必须在命令行运行。(不要再努力啦,哈哈,博主就用了很长时间在
这个上面)
【注意点2】:运行的时候必须准确找到文件的路径,由于保密的限制我们可能只能使用某个路径。
PYTHONPATH=$PYTHONPATH:HAT-main python HAT-main/hat/train.py -opt HAT-main/options/train/train_HAT_SRx2_from_scratch.yml如果要使用多卡训练的话
CUDA_VISIBLE_DEVICES=0 python -m torch.distributed.launch --nproc_per_node=1 --master_port=4321 hat/train.py -opt options/train/train_HAT_SRx2_from_scratch.yml --launcher pytorch【注意点3】:由于我们的服务器是没有连接网络的,如果缺少什么包的话。
使用.whl文件
- 下载".whl"文件,网址:PyPI · The Python Package Index
- 进入下载路径,在cmd中输入"pip install xxx.whl"
- pip3 install –user –no-index /gpfs/home/wuhuangjdqwl/wuhuangj/packages/antlr4_python3_runtime-4.13.2-py3-none-any.whl
- pip3 install –user –no-index /gpfs/home/wuhuangjdqwl/wuhuangj/packages/pytorch_lightning-2.5.1.post0-py3-none-any.whl
如果所在的包没有.whl文件的话,可以下载整个包放在项目里
【注意点4】在服务器上可能要激活环境
export PATH="/root/anaconda3/bin:$PATH"
eval "$(conda shell.bash hook)"
conda activate base【注意点5】:一定一定要注意路径问题,整个的训练过程中不能断网
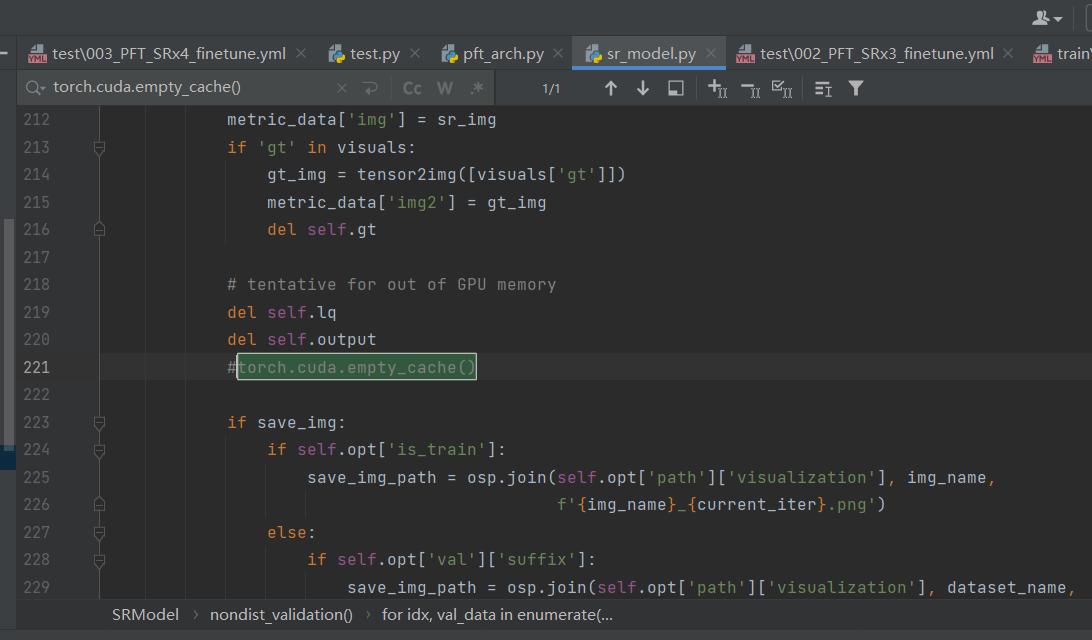
[注意点6]:结束程序的时候
不能简单的关闭命令行窗口,而是需要通过下面这个命令
使用以下命令可以结束所有 Python 程序的运行:
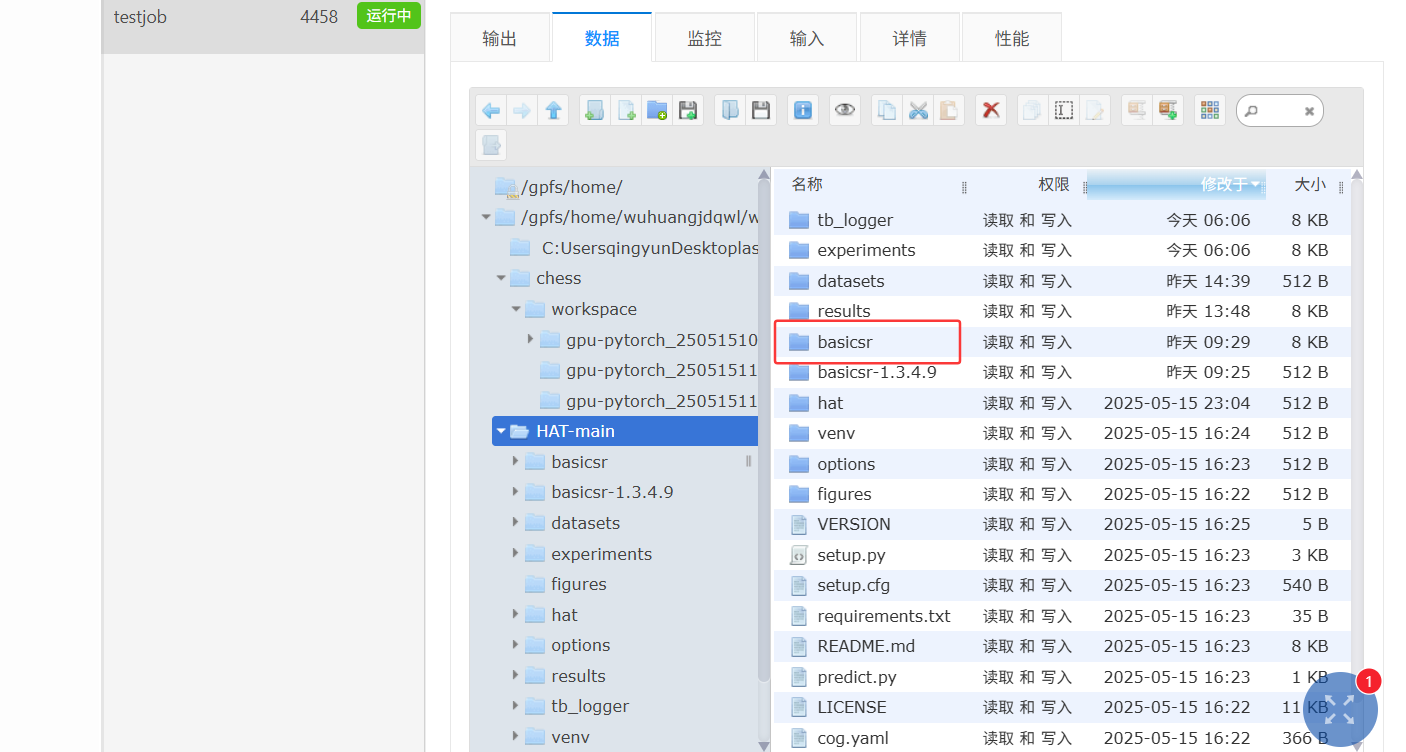
ps -ef | grep python | grep -v grep | awk '{print $2}' | xargs kill -9HAT
(1)下载对应的预训练模型放到指定的文件夹中
因为测试的时候需要用到的
(2)数据集的格式整理,注意根据yaml下的路径整理
用到下面那行代码我是注释掉的,因为我人为的让训练集和测试的命名一样且相互对应的。
不一样的话,可以自己写脚本去改变。
import os
# 设置目录路径
dir_path = r"C:UsersqingyunDesktoplastDF2KDF2K_bicx2_sub"
# 遍历目录中的所有文件
for filename in os.listdir(dir_path):
if "x2" in filename:
# 构造新文件名(删除x2)
new_filename = filename.replace("x2", "")
# 重命名文件
os.rename(
os.path.join(dir_path, filename),
os.path.join(dir_path, new_filename)
)
print(f"Renamed: {filename} -> {new_filename}")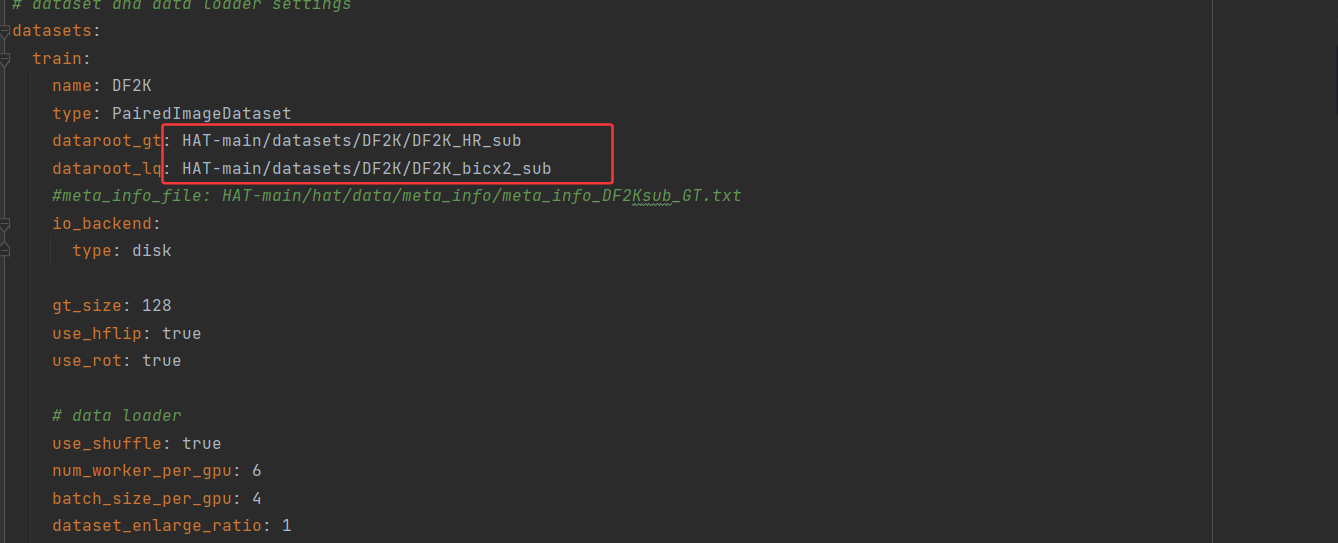
训练
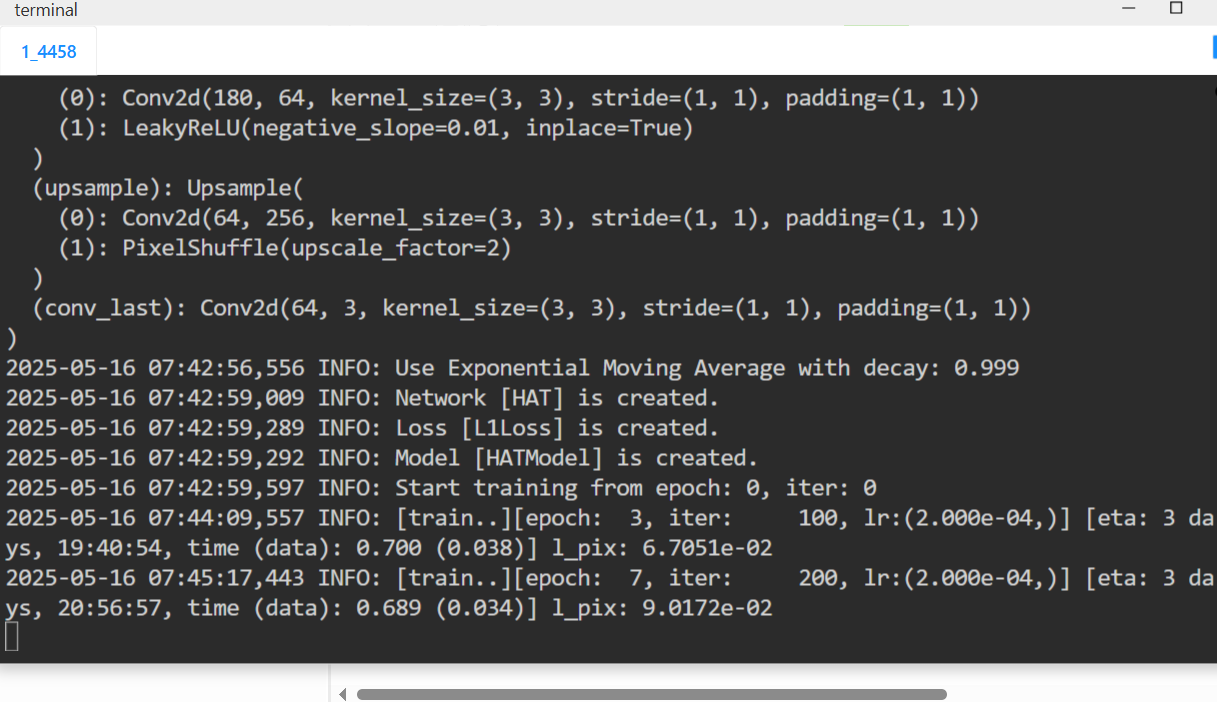
测试
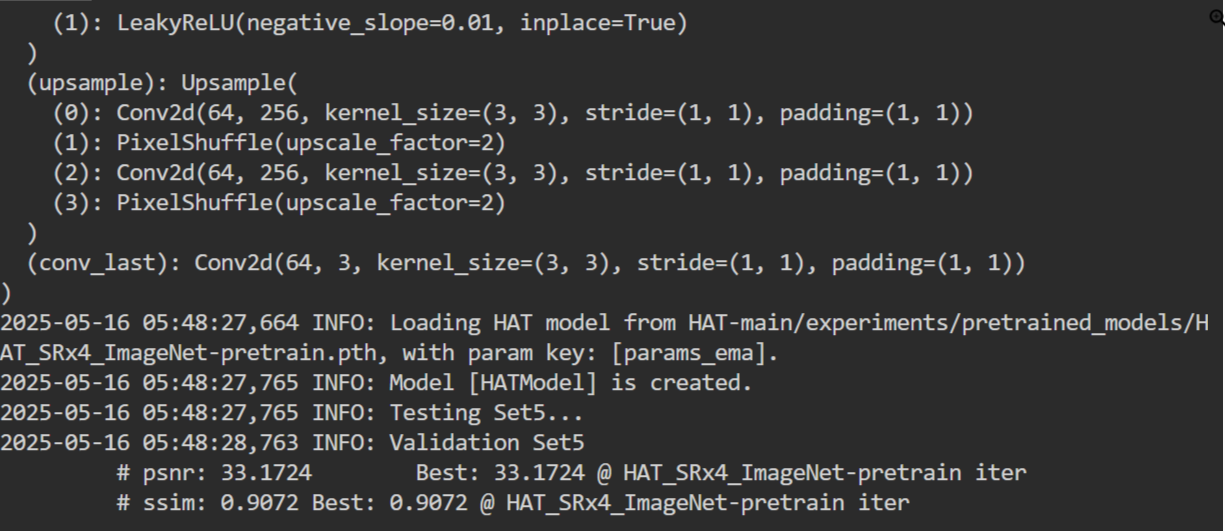
对一张图片进行测试
PYTHONPATH=$PYTHONPATH:HAT-main python HAT-main/hat/test.py -opt HAT-main/options/test/HAT_SRx4_ImageNet-LR.yml结果会保存在下面这个路径下
results/HAT_SRx4_ImageNet-LR/visualization/custom/
HAT训练时间(Total epochs: 20000; iters: 500000.)
(1)使用DF2K小型数据集(大概100张照片)文件大小是541 MB
(2)训练时间从大概需要50个小时
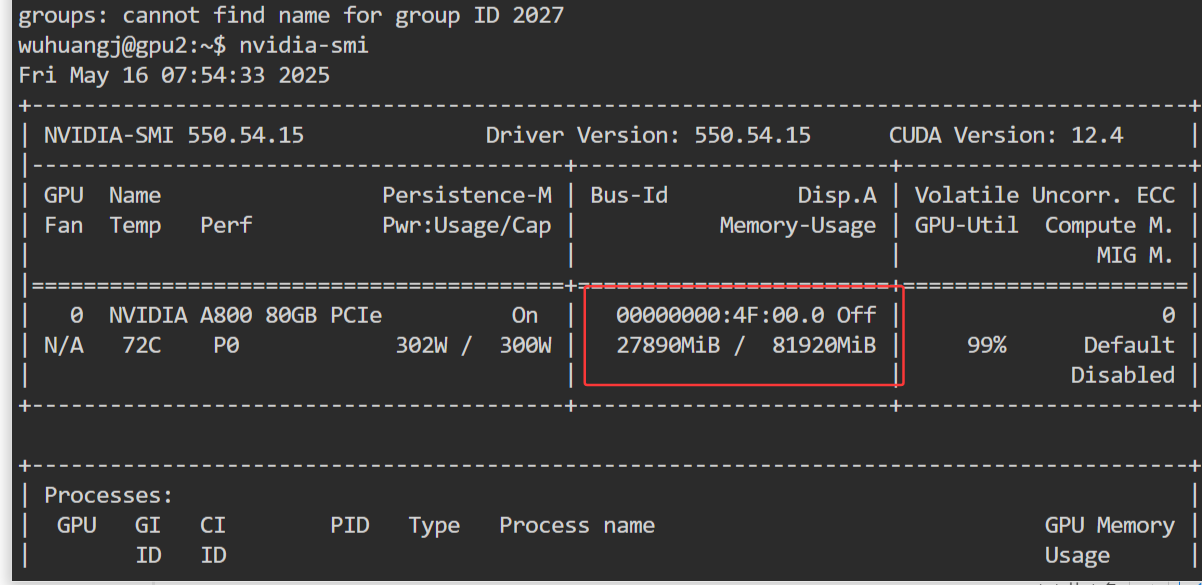
资源占用(可以新开一个命令行窗口)
nvidia-smi
PFT-SR
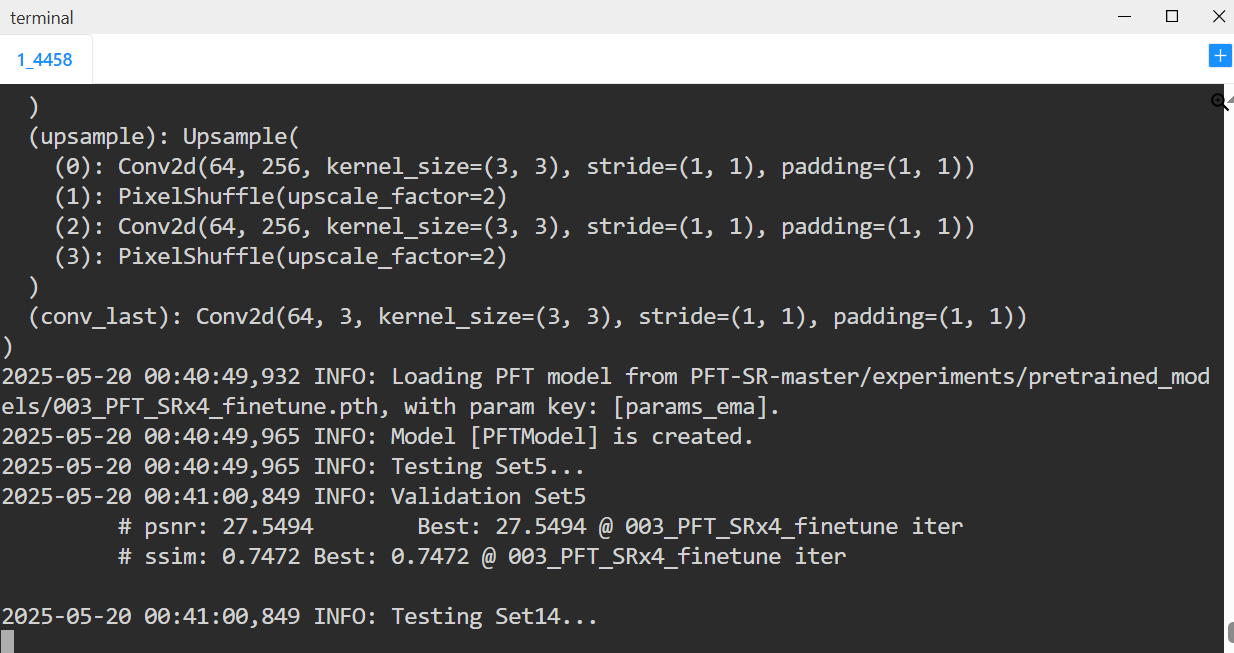
测试一张图片
PYTHONPATH=$PYTHONPATH:PFT-SR-master python inference.py -i inference_image.png -o results/test/ --scale 4 --task classical训练
PYTHONPATH=$PYTHONPATH:PFT-SR-master python -m PFT-SR-master/basicsr/train.py -opt PFT-SR-master/options/train/003_PFT_SRx4_finetune.yml 
测试的命令
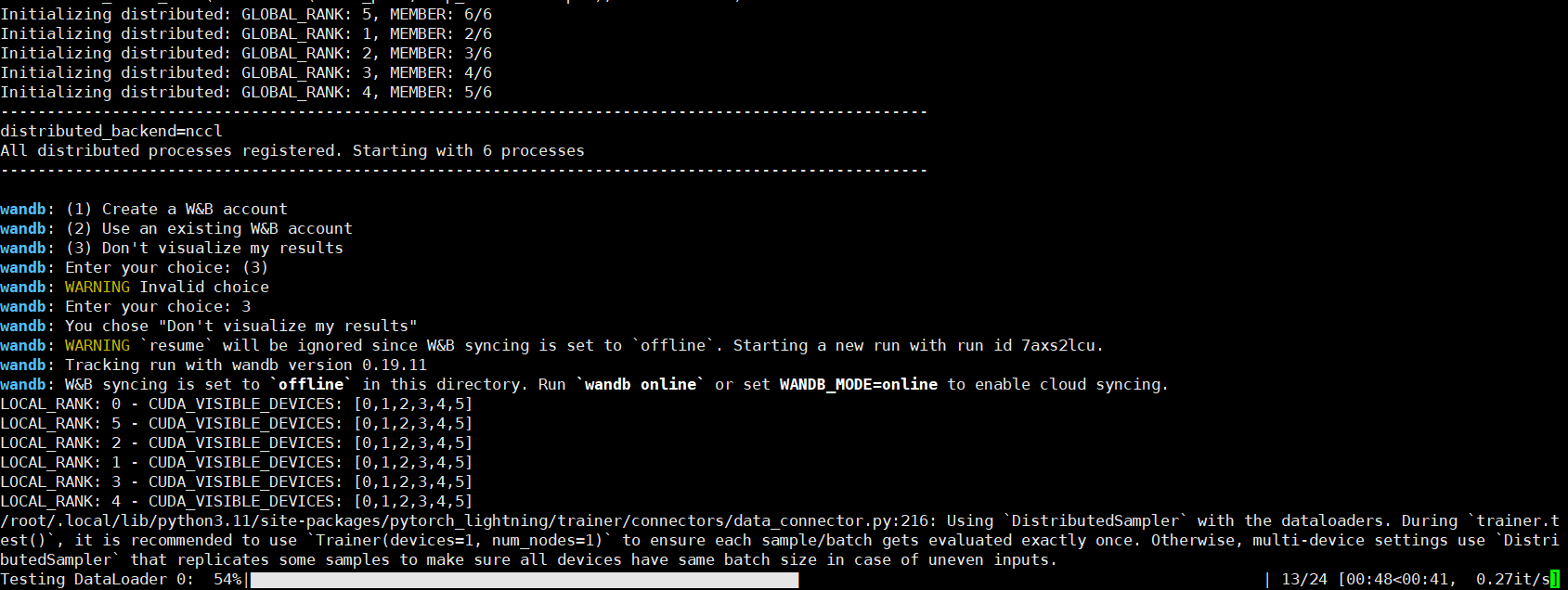
CUDA_VISIBLE_DEVICES=0,1,2,3,4 torchrun --nproc_per_node=5 --master_port=4321 PFT-SR-master/basicsr/train.py -opt PFT-SR-master/options/train/001_PFT_SRx2_scratch.yml --launcher pytorch如果出现这种错误
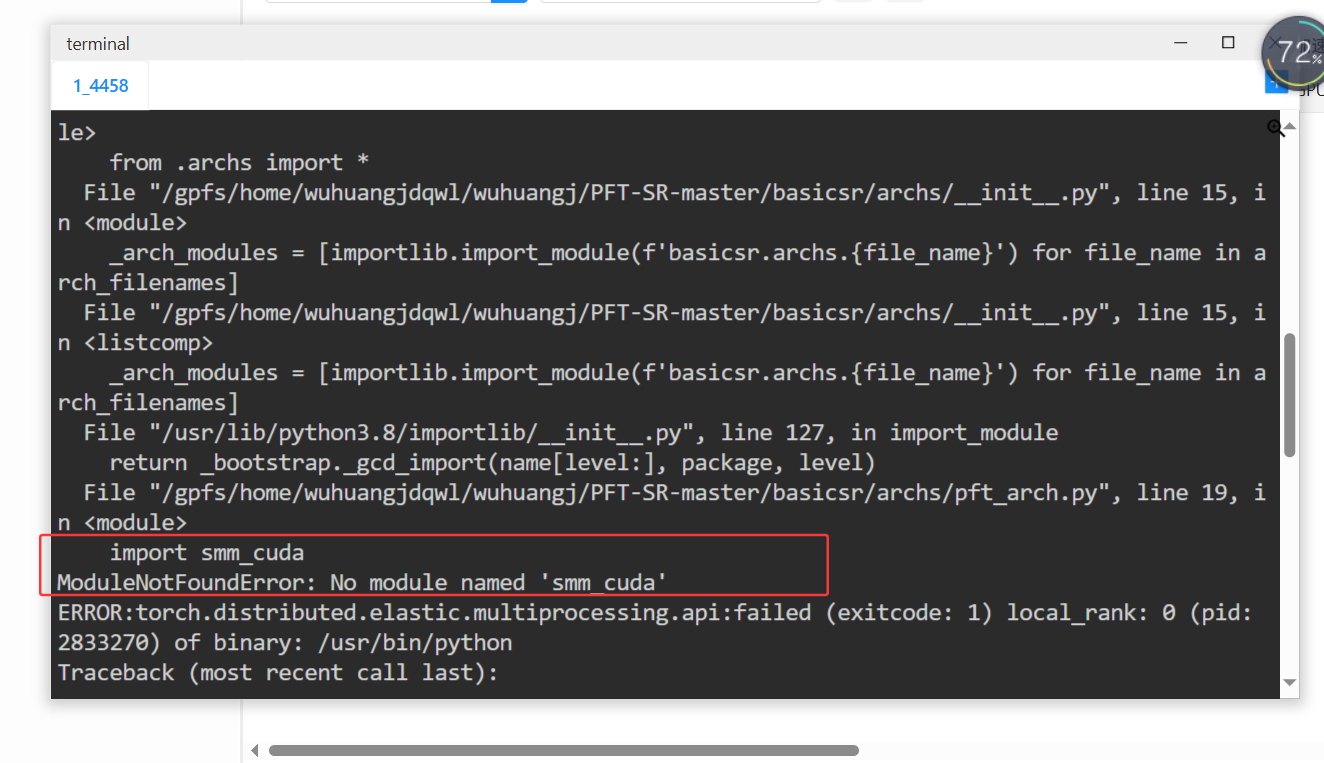
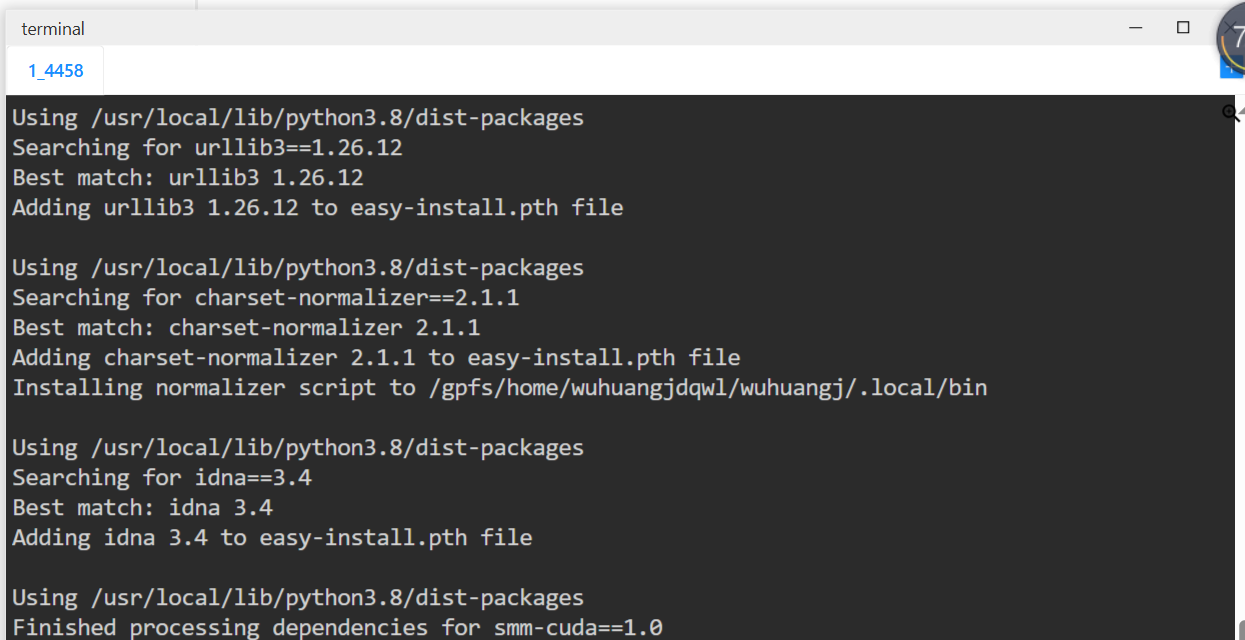
cd PFT-SR-master/ops_smm
bash make.sh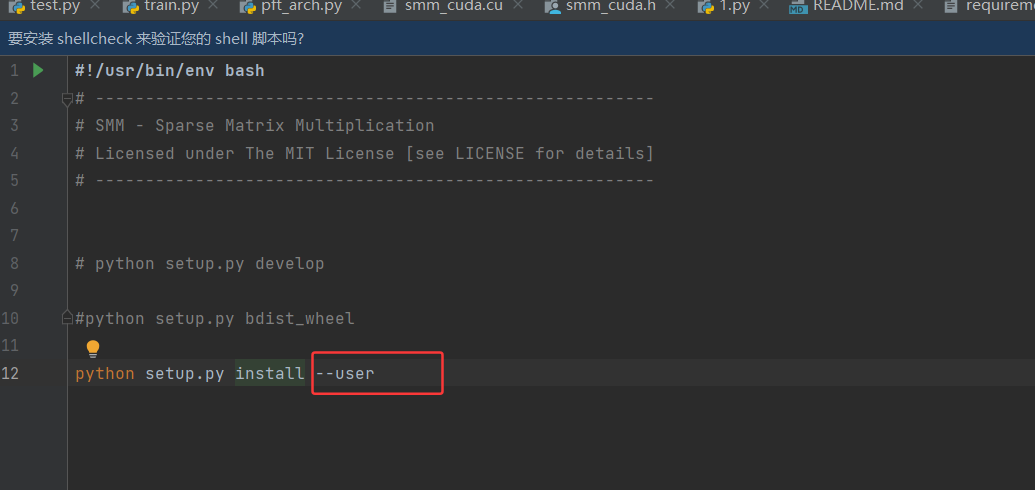
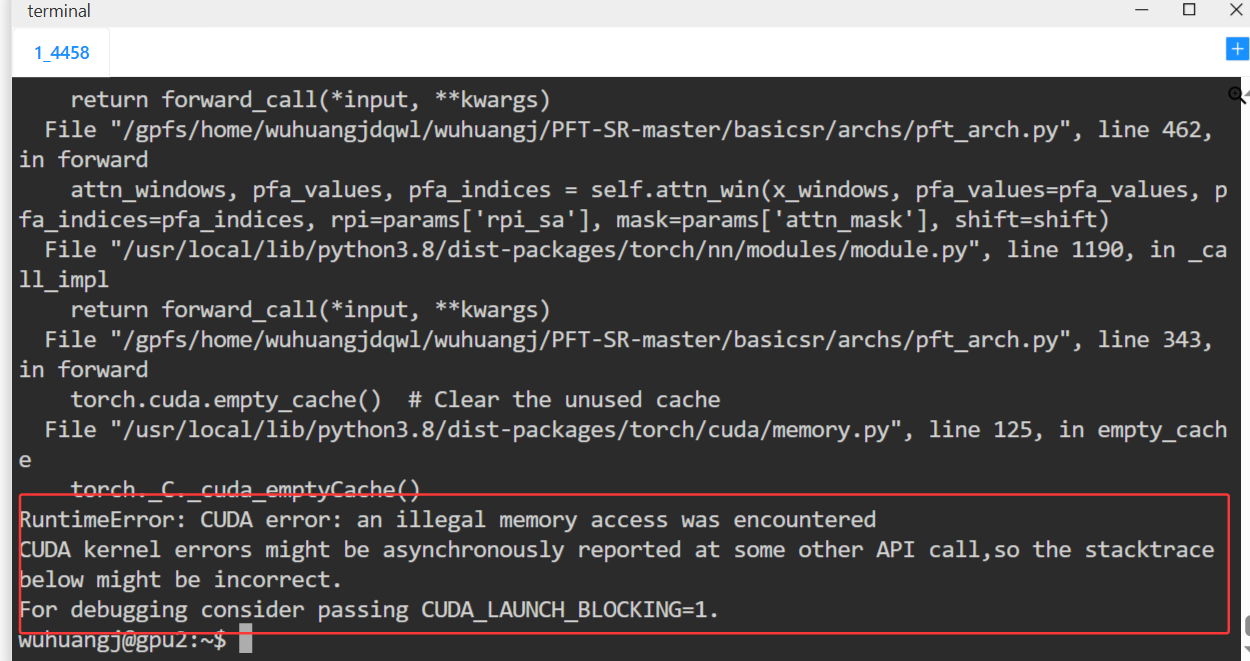
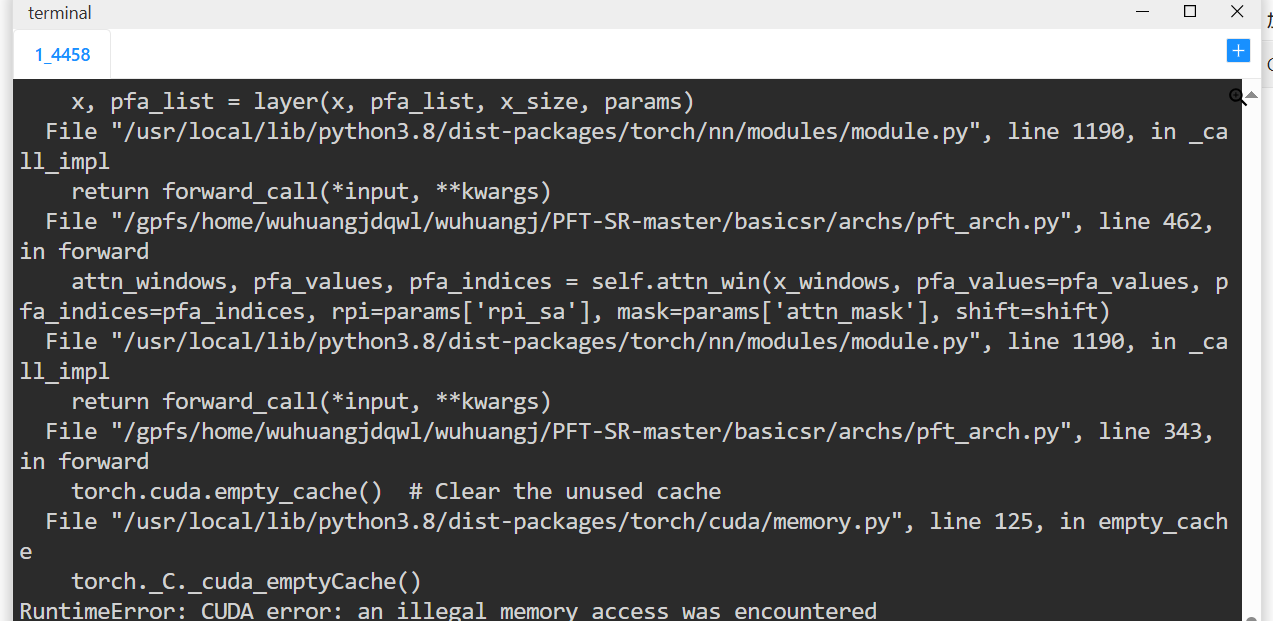
出现了新的问题
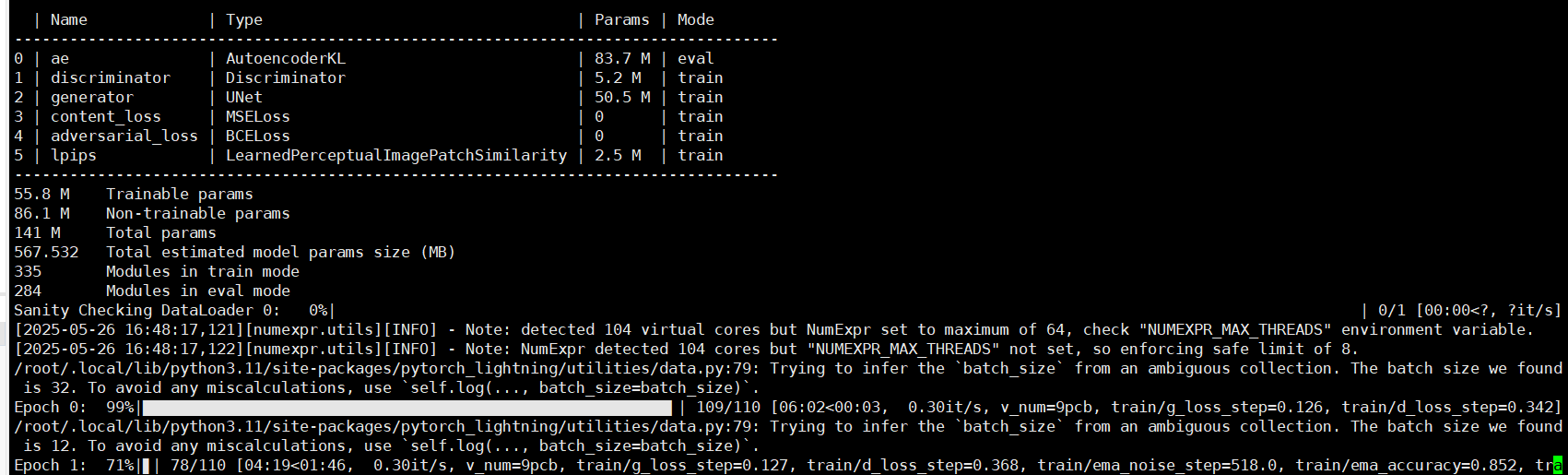
SupResDiffGAN
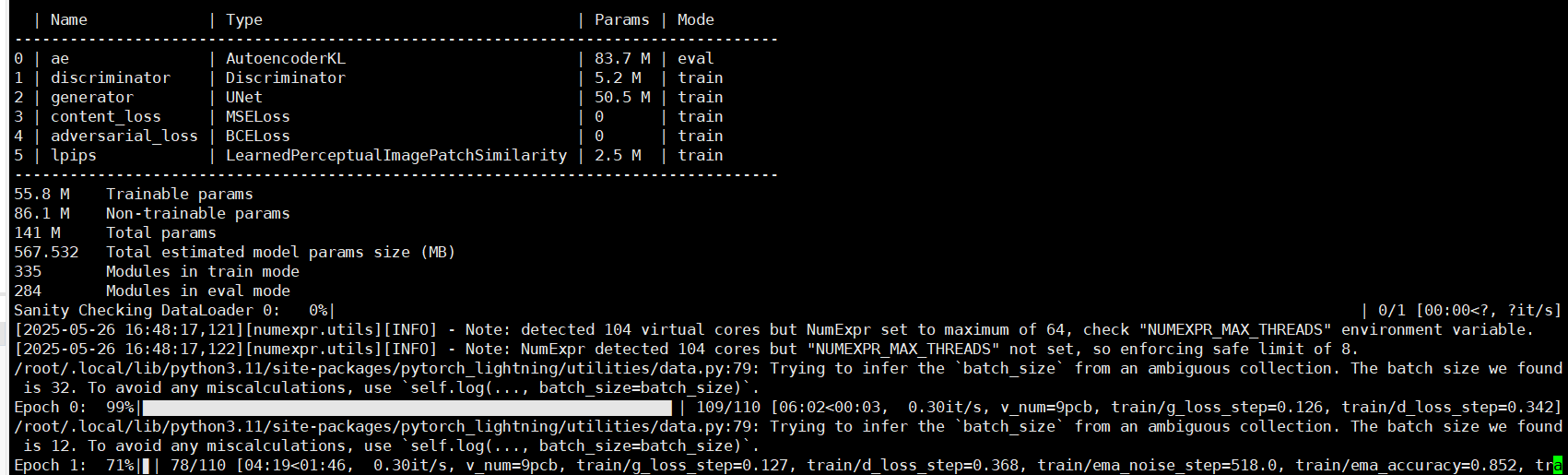
训练

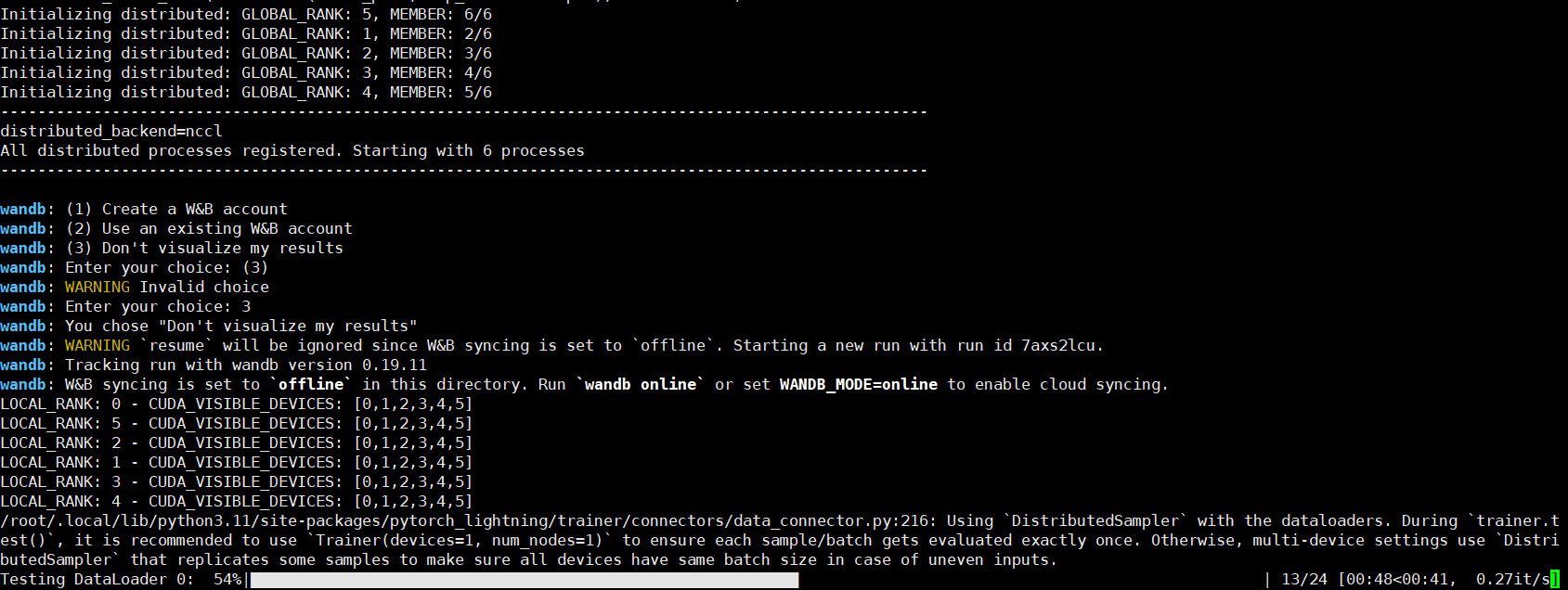
测试
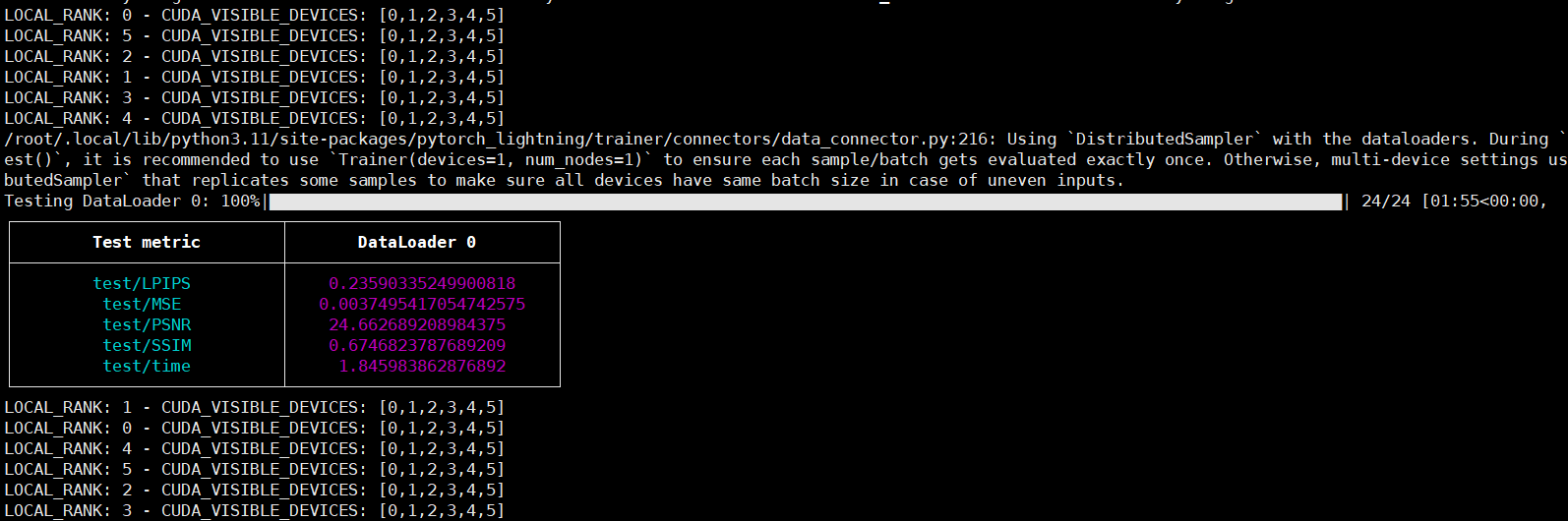
对一张图片测试
import torch
import torch.nn.functional as F
from torchvision import transforms
from PIL import Image
from types import SimpleNamespace
from scripts.model_config import model_selection
# ======= 配置 =======
class Config:
def __init__(self):
# 模型 checkpoint
self.ckpt = "/root/SupResDiffGAN-master/SupResDiffGAN-imagenet.ckpt"
# 低分辨率输入 & 输出路径
self.lr_path = "/root/SupResDiffGAN-master/inference_image.png"
self.out_path = "/root/SupResDiffGAN-master/inference_result.png"
# 放大倍数
self.scale = 4
# latent 下需被 UNet 下采样 4 次(16倍) 整除
self.latent_pad = 16
# 构造 model_selection 所需 cfg
self.cfg = SimpleNamespace(
mode="test",
model=SimpleNamespace(
name="SupResDiffGAN",
lr=1e-4,
alfa_perceptual=1e-3,
alfa_adv=1e-2,
use_perceptual_loss=False,
load_model=self.ckpt
),
use_perceptual_loss=False,
autoencoder="VAE",
feature_extractor=True,
unet=[64,96,128,512],
discriminator=SimpleNamespace(in_channels=6, channels=[64,128,256,512]),
diffusion=SimpleNamespace(
timesteps=1000, beta_type="cosine", posterior_type="ddpm",
validation_timesteps=1000, validation_posterior_type="ddpm"
),
dataset=SimpleNamespace(scale=self.scale),
checkpoint=SimpleNamespace(monitor="", dirpath="", save_top_k=1, mode=""),
trainer=SimpleNamespace(max_epochs=1, max_steps=1,
check_val_every_n_epoch=1, limit_val_batches=1, log_every_n_steps=1),
wandb_logger=SimpleNamespace(project="", entity="")
)
# ======= 工具函数 =======
def pad_latent(latent: torch.Tensor, mult: int):
"""
对 [B,C,H,W] latent 在右和下方做 zero-pad,
保证 H 和 W 均能被 mult 整除。
返回 padded_latent, pad_w, pad_h
"""
b, c, h, w = latent.shape
pad_h = (mult - h % mult) % mult
pad_w = (mult - w % mult) % mult
padded = F.pad(latent, (0, pad_w, 0, pad_h), mode="constant", value=0)
return padded, pad_w, pad_h
def load_lr_tensor(path: str):
"""
读取低分辨率图像,转 Tensor 并归一化到 [-1,1]。
返回 tensor([1,3,H_lr,W_lr]) 和原始尺寸 (w_lr,h_lr)
"""
img = Image.open(path).convert("RGB")
w, h = img.size
tf = transforms.Compose([
transforms.ToTensor(), # [0,1]
transforms.Lambda(lambda x: x*2 - 1) # ->[-1,1]
])
return tf(img).unsqueeze(0), (w, h)
def save_sr_image(sr_tensor: torch.Tensor, pad_w: int, pad_h: int,
lr_size: tuple, scale: int, out_path: str):
"""
sr_tensor: [1,3,H_lat_pad*8, W_lat_pad*8] in [-1,1]
1) 去除 latent padding 对应的像素 pad部分 (pad_h*8, pad_w*8)
2) 映射回 [0,1]
3) resize 到 lr_size*scale
4) 保存
"""
# 去 pad
_, _, Hp, Wp = sr_tensor.shape
H = Hp - pad_h*8
W = Wp - pad_w*8
out = sr_tensor[..., :H, :W].squeeze(0).clamp(-1,1)
out = (out + 1)/2 # -> [0,1]
pil = transforms.ToPILImage()(out.cpu())
# resize 到 lr*scale
w_lr, h_lr = lr_size
pil = pil.resize((w_lr*scale, h_lr*scale), Image.BICUBIC)
pil.save(out_path)
# ======= 主流程 =======
def main():
cfg_all = Config()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 构建并加载模型
model = model_selection(cfg_all.cfg, device=device)
ckpt = torch.load(cfg_all.ckpt, map_location=device)
sd = ckpt.get("state_dict", ckpt)
model.load_state_dict(sd, strict=False)
model.to(device).eval()
print(f"[INFO] Loaded checkpoint: {cfg_all.ckpt}")
# 加载 LR Tensor
lr_t, lr_size = load_lr_tensor(cfg_all.lr_path)
lr_t = lr_t.to(device)
print(f"[INFO] Loaded LR tensor: {lr_t.shape}")
# 1) 编码到 latent
with torch.no_grad():
x_lat = model.ae.encode(lr_t).latent_dist.mode().detach() * model.ae.config.scaling_factor
print(f"[INFO] Latent shape: {x_lat.shape}")
# 2) 对 latent 做 padding (保证能被 16 整除)
x_lat_p, pad_w, pad_h = pad_latent(x_lat, cfg_all.latent_pad)
print(f"[INFO] Padded latent: {x_lat_p.shape}, pad_w={pad_w}, pad_h={pad_h}")
# 3) 扩散采样
model.diffusion.set_timesteps(cfg_all.cfg.diffusion.timesteps)
model.diffusion.set_posterior_type(cfg_all.cfg.diffusion.posterior_type)
with torch.no_grad():
x_sample = model.diffusion.sample(model.generator, x_lat_p, x_lat_p.shape)
# 4) 解码超分
with torch.no_grad():
x_out = model.ae.decode(x_sample / model.ae.config.scaling_factor).sample
x_out = torch.clamp(x_out, -1, 1)
print(f"[INFO] Decoded SR tensor: {x_out.shape}")
# 5) 去 pad 并保存
save_sr_image(x_out, pad_w, pad_h, lr_size, cfg_all.scale, cfg_all.out_path)
print(f"[INFO] Super-res image saved: {cfg_all.out_path}")
if __name__ == "__main__":
main()














