梯度下降(Gradient Descent)是人工智能,机器学习和深度学习的核心优化算法,几乎是所有的参数学习模型(线性回归、神经网络、CNN等)依赖最小化损失函数找到最优参数。
本质原理:沿着损失函数的下坡方向逐步迭代,最终找到最低点(最优解),全局极小值。
本质:梯度就是函数对它的各个自变量求偏导后,由偏导数组成的一个向量。
我们可以通过向量中每个自变量的正负值来表示方向,如果导数的值是正数,那么就代表X轴的“正方向”。如果导数的值是负数,那么就代表是X轴的“负方向”。(所谓的正负方向就是在极小值点的右边/左边)。
梯度下降原理:就是如果我们在极小值的正方向即导数大于0,则我们需要“下楼梯”下一次运动方向需要朝导数方向的反方向运动,如果导数小于0,我们就需要接着“下楼梯”顺着导数的方向运动,方向确定了,每次走的步幅多大呢,我们引入了学习率eta,通过(eta*偏导数)的值算出下一步我们走的步幅,再通过原本的所在位置坐标x1对步幅进行加减操作,来确定下一次我们到达的位置x2,加减操作取决于偏导数的正负。
梯度下降的公式:
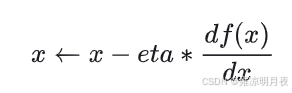
案例:
将上述梯度下降算法运用到python中的代码如下
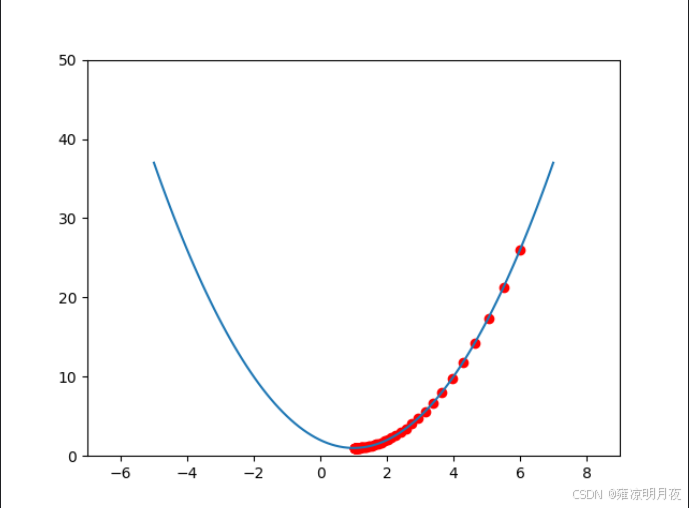
import matplotlib.pyplot as plt import numpy as np # 初始化参数 x = 6 learning_rate = 0.05 iterations = 50 # 存储迭代过程中的坐标 x_history = [x] y_history = [(x - 1)**2 + 1] # 梯度下降迭代 for _ in range(iterations): gradient = 2 * x - 2 x = x - learning_rate * gradient y = (x - 1)**2 + 1 x_history.append(x) y_history.append(y) # 绘制函数曲线 func_x = np.linspace(-5, 7, 100) func_y = (func_x - 1)**2 + 1 plt.plot(func_x, func_y) # 绘制迭代轨迹 plt.scatter(np.array(x_history), np.array(y_history), color='red') plt.axis([-7, 9, 0, 50]) plt.show()其产生的最终图像如下:
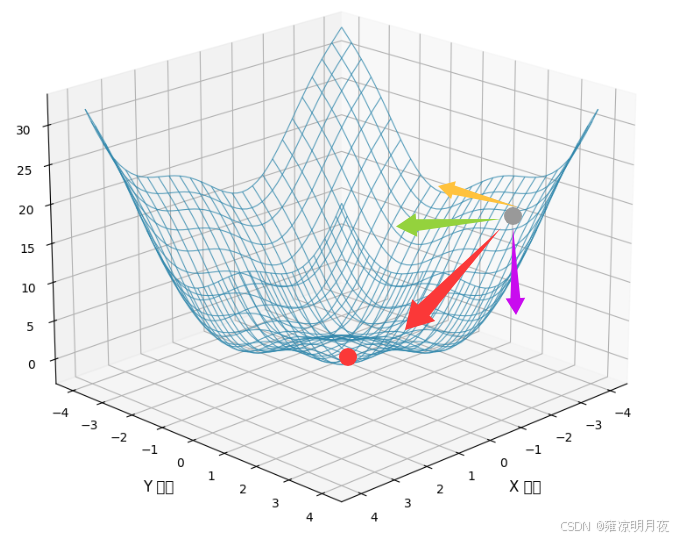
上述是2维情况下的例子仅有一个自变量,我们继续推广为3D情况,请看下图在曲面上的任意一点(灰点)要想去该曲面的极小值点(红点)则需要采用梯度下降的方法,在x轴方向,y轴方向,z轴方向都要下降相应的梯度,其n个方向受力的合力(红色箭头)代表该点最终的前进方向。
我们根据一维的平面计算其前进轨迹可以发散一下思维,在这个三位平面上我们有三个自变量[x,y,z],那么在每一个轴上的前进距离我们用[x1,x2,x3]代替,其每个轴上的计算方法可以为(此处仅列举两个轴上的运动距离)
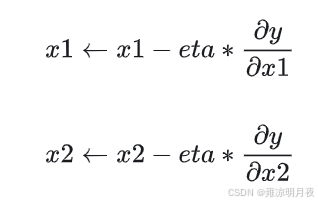
也可以写成向量形式
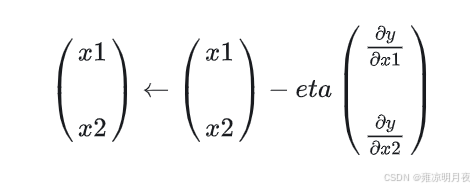
我们又将其前两个自变量的偏导数组成一个【向量】: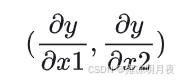
我们可以很容易的从该点的向量值(正负)判断当前位置在不同维度时,朝向哪个方向变化可以使得函数值 y 减小。
我们再发散一下思维,如果将在n维形状上运动寻找极值点,那么我们就可以将物体最终运动的合力拆解为n个分力,每个分力运动方向可以为一个轴的梯度下降,这样我们就可以计算n个x偏导组成的向量也进一步计算n个轴上的运动距离,如下
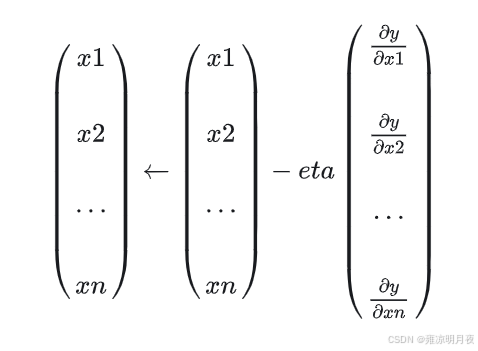
1.本质:
用于求解机器学习模型参数(如线性回归的权重w,逻辑回归的系数等)优化算法,核心目标是最小化模型的【损失函数】(MSE,交叉熵)
与传统 “批量梯度下降(BGD)” 的核心区别:
- BGD:每次迭代用「全部训练数据」计算损失的梯度,更新一次参数。问题:数据量大时(如百万样本),计算量爆炸,训练速度极慢。
- SGD:每次迭代只用「1 个随机样本」计算梯度,更新一次参数。核心思想:用单个样本的 “局部梯度” 近似全局梯度,以 “牺牲一点点精度” 换 “极致的速度和内存效率”。
假设模型参数为 θ,损失函数为 L (θ),学习率为 η:
- BGD 的参数更新:θ = θ – η × ∇L (θ)(∇是全局梯度,用所有样本计算)
- SGD 的参数更新:θ = θ – η × ∇L (θ; x_i, y_i)(∇是单个样本 (x_i,y_i) 的局部梯度)
2.适用场景:
1.大模型数据集:
样本数>10W,甚至百万千万等,SGD 每次只处理 1 个样本,内存占用恒定(与数据量无关),迭代速度快,能快速看到模型收敛趋势。
2.在线学习(实时更新模型):
实时推荐,例如常见的股票预测,抖音推荐等。
3.模型简单,数据噪声不敏感:
模型是线性模型(线性回归、逻辑回归、SVM)或简单神经网络。
4.内存资源有限的场景:
嵌入式设备上做简单的温度预测(用线性回归 + SGD,实时处理传感器数据)
3.SGD优缺点:
优点:
- 训练速度快,迭代效率高:每次仅用 1 个样本,无需等待全量数据计算,大数据集下比 BGD 快几个数量级。
- 内存占用极低:与样本量无关,仅需存储单个样本和模型参数,适配大数据和边缘设备。
- 支持在线学习:可实时处理新数据,动态更新模型,适合流式数据场景。
- 容易逃离局部最优解:梯度的随机波动可能帮助模型跳出局部最小值(尤其是损失函数非凸时,如神经网络)。
缺点:
- 学习率难以选择:
- 学习率太大:收敛曲线震荡更严重,甚至不收敛;
- 学习率太小:收敛速度极慢,且可能陷入局部最优;纯 SGD 通常需要 “衰减学习率”(如随迭代次数线性衰减、指数衰减),但调参成本高。
- 对异常值敏感:单个异常样本的梯度可能严重偏离全局梯度,导致参数更新 “跑偏”(BGD 用全量数据平均,能抵消异常值影响)。
- 不适合复杂模型:复杂模型(如深度学习、决策树集成)的损失函数曲面更复杂,SGD 的随机波动容易导致模型发散,需要更稳定的梯度估计。
- 梯度波动大,收敛路径崎岖:单个样本的梯度是全局梯度的 “噪声近似”,导致参数更新忽大忽小,收敛曲线震荡剧烈(如下图),需要更长时间才能稳定到最优解附近。
4.使用关键:
1.数据预处理
SGD 对数据尺度敏感(因为梯度更新与特征值大小相关),必须先做 标准化 / 归一化:
- 标准化:将特征转换为均值 = 0、方差 = 1(
sklearn.preprocessing.StandardScaler); - 归一化:将特征缩放到 [0,1] 或 [-1,1](
sklearn.preprocessing.MinMaxScaler)。 - 原因:如果特征尺度不一致(如 “年龄” 是 0-100,“收入” 是 0-100 万),梯度会被大尺度特征主导,导致参数更新失衡。
2. 学习率调度
- 常用策略:
- 指数衰减:η = η0 × decay_rate^(epoch)(epoch 是迭代次数);
- 步长衰减:每过 k 个 epoch,η = η0 × 0.1;
- 自适应衰减:根据梯度幅度调整(如
torch.optim.lr_scheduler.ReduceLROnPlateau,当验证集损失不再下降时衰减)。
- 经验值:初始学习率 η0 通常设为 0.01、0.001(需根据数据和模型调整,可先用网格搜索)。
3. 避免异常值影响
- 预处理时用 IQR 或 Z-score 剔除异常值;
- 用 “梯度裁剪”(Gradient Clipping):限制单次梯度的最大幅度(如
torch.nn.utils.clip_grad_norm_),避免异常样本导致梯度爆炸。
5.简单案例:
用sgd做简单的线性回归
'''
1. 生成模拟数据
2. 数据预处理(标准化)
3. 划分训练/测试集
4. 初始化SGD模型
5. 训练模型
6. 评估模型
'''
#导入代码库
import numpy as np
#sklearn 库中封装好的 “SGD 回归器”—— 核心工具
from sklearn.linear_model import SGDRegressor
#数据 “标准化” 工具 ——SGD 算法的关键预处理步骤
from sklearn.preprocessing import StandardScaler
#拆分数据集的工具 —— 把数据分成 “训练集”(教模型学习)和 “测试集”
from sklearn.model_selection import train_test_split
#生成一个模拟数据
# 10万样本,5个特征(特征矩阵X:形状是 (100000, 5))
X = np.random.randn(100000, 5)
# 真实模型:y = 3*X1 + 2*X2 -5*X3 + 噪声(标签y:形状是 (100000,))
y = 3*X[:,0] + 2*X[:,1] - 5*X[:,2] + np.random.randn(100000)
#数据预处理
scaler = StandardScaler() # 初始化标准化工具
X_scaled = scaler.fit_transform(X) # 对X做标准化
#划分训练集测试集
X_train, X_test, y_train, y_test = train_test_split(
X_scaled, y, test_size=0.2, random_state=42
)
#初始化SGD回归模型,制定学习规则
sgd_reg = SGDRegressor(
loss='squared_error', # 损失函数:均方误差(MSE)
learning_rate='adaptive', # 学习率策略:自适应
eta0=0.01, # 初始学习率:0.01
max_iter=1000, # 最大迭代次数:1000次
random_state=42 # 固定随机种子,复现结果
)
#训练模型
sgd_reg.fit(X_train, y_train)
#评估模型
print("模型参数(权重w):", sgd_reg.coef_) # 接近真实值 [3,2,-5,0,0]
print("模型截距(b):", sgd_reg.intercept_)
print("测试集R²分数:", sgd_reg.score(X_test, y_test)) # 通常>0.81.本质:
在SGD算法的基础上添加了“动量”,积累了历史梯度的“惯性”,抵消当前梯度的噪音,让参数更新更平稳、更快。
SGD的基础算法:

SGD 的 3 个关键问题:
- 收敛慢:每次只看单个样本的梯度,梯度方向波动大(“噪声大”),无法稳定朝着最优解方向前进;
- 易陷入局部最优 / 鞍点:在平缓区域或鞍点(梯度接近 0),SGD 会因梯度太小而停滞;
- 学习率难调:学习率太大容易震荡不收敛,太小则收敛速度极慢。
2.基于SGD优化点
基于上述SGD的短板,Momentum的核心思想就是给SGD加“惯性”
想象参数更新是 “小球下山”:
- SGD 像一个 “没惯性的小球”,每次只顺着当前坡度(梯度)走,遇到小坑洼(梯度噪声)就会来回晃动,下山很慢;
- Momentum 像一个 “有惯性的小球”,下山时会积累速度(历史梯度的加权和),小坑洼无法改变它的前进方向,还能借助惯性冲过平缓区域(梯度小的地方),更快到达山脚(最优解)。
Momentum相比于SGD其就是在SGD的基础上添加了【动量项】v,更新逻辑
1.计算动量项v(积累历史梯度)

2.动量项更新参数(代替 SGD 的直接梯度更新)
![]()
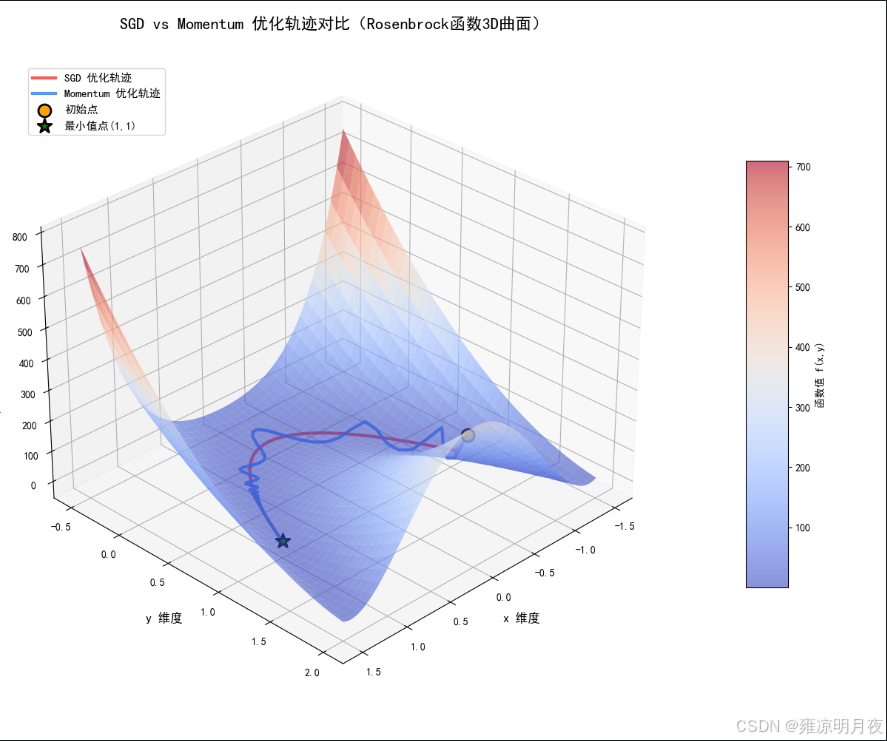
3.Momentum vs SGD
SGD和Momentum对比
abla L( heta))
案例:我们为了更清楚的对比两种梯度下降算法的差异我用AI生成了一个香蕉函数的3D图供大家,更好的查看两种算法的差异性
1.本质:
NAG是Momentum算法的改进版,核心是“先根据历史动量走一步,再计算梯度”,以此减少梯度估计的滞后性,让收敛更加精确。

直观理解:NAG 是 “有预判的 Momentum”
- Momentum 像 “蒙眼推车”:根据当前位置的梯度,结合历史速度前进;
- NAG 像 “睁眼推车”:先根据历史速度 “预判” 下一步要到的位置,再在这个 “预判位置” 看梯度,调整前进方向。
2.基于Momentum的优化
NAG针对Momentum的“梯度滞后性”做了一些优化
- Momentum 的梯度是基于当前位置计算的,但参数更新是基于历史动量,两者存在 “时间差”,导致梯度估计滞后;
- NAG 先 “预判” 下一步位置,再在该位置计算梯度,让梯度估计更 “超前”,从而减少震荡、加速收敛。
NAG 是 Momentum 的改进版,适用场景与 Momentum 高度重叠,但在梯度波动大、收敛路径崎岖的场景下表现更优:
- 非凸损失函数的模型(如深度神经网络):这类模型的损失曲面复杂(有很多局部最优和震荡区域),NAG 的 “预判梯度” 能更精准地导航,避免在震荡中浪费迭代次数。
- 需要快速收敛的场景(如大规模数据训练):NAG 的收敛速度比 Momentum 更快,尤其在训练后期(接近最优解时),震荡更小。
- 替代 Momentum 的通用场景:只要你原本考虑用 Momentum,都可以尝试 NAG—— 它几乎在所有 Momentum 适用的场景下都能表现得更好(或至少持平)。
3.NAG的优缺点
优点
- 收敛更快、震荡更小:通过 “预判梯度” 减少了 Momentum 的滞后性,在复杂损失曲面上收敛更稳定。
- 继承 Momentum 的所有优点:如加速收敛、处理小批量梯度噪声等。
- 超参数少且易调:仅需调整动量系数γ(通常设 0.9)和学习率η ,调参成本低。
缺点
- 计算成本略高:每次迭代需要多一次 “预判位置” 的计算(但实际中这个开销可以忽略)。
- 对学习率仍敏感:虽然比纯 SGD 鲁棒,但学习率设置不当仍会导致收敛问题(需配合学习率衰减策略)。
4.SGD VS Momentum VS NAG
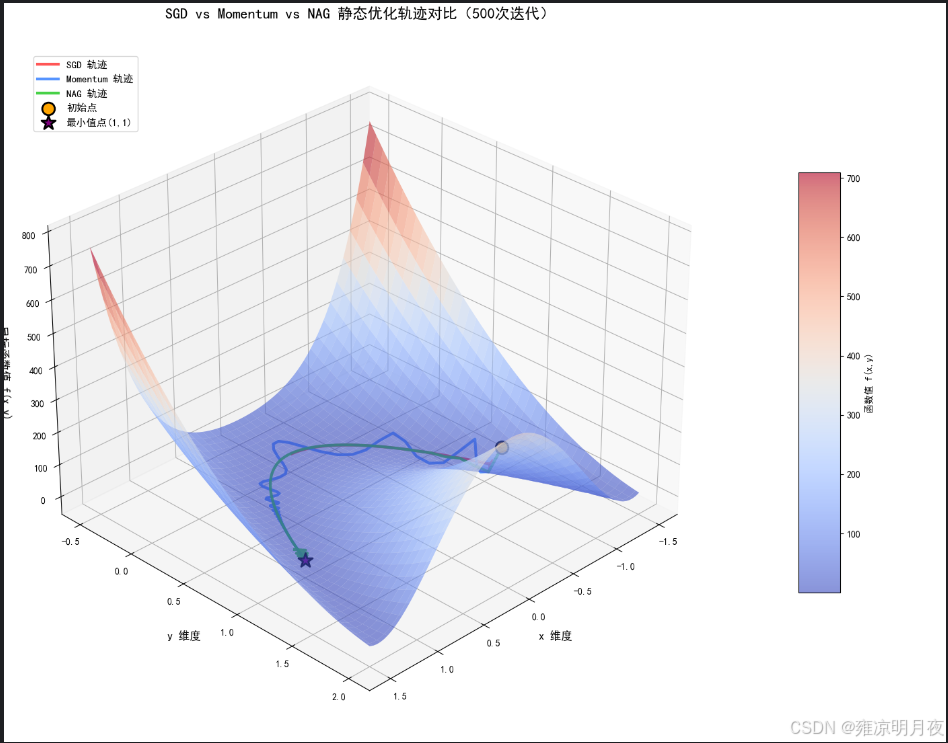
1.本质:
Adagrad 是自适应学习率优化器的开山之作,核心思想是 “对不同特征(或参数)使用不同的学习率”—— 在训练过程中,对出现频率低的特征采用大学习率,对出现频率高的特征采用小学习率。
 其本质就是通过每个特征的频率更新其累计梯度平方和,从而进一步调节学习率,实现自适应学习率的作用。
其本质就是通过每个特征的频率更新其累计梯度平方和,从而进一步调节学习率,实现自适应学习率的作用。

2.使用场景
1. 稀疏数据场景(如文本、推荐系统)
- 场景特征:数据中大量特征出现频率极低(如用户行为数据中的 “小众商品点击”、文本中的 “生僻词”)。
- 为什么适配?稀疏数据中,低频特征的梯度更新少,Adagrad 会给它们分配大学习率,确保这些特征能被模型学到;而高频特征的学习率被压制,避免过拟合。
- 例子:用逻辑回归做文本分类(如新闻分类)、推荐系统的点击率预测(用户对小众商品的点击行为)。
2. 特征尺度差异大的场景
- 场景特征:特征间数值范围差异极大(如 “年龄(0-100)” 和 “收入(0-100 万)”)。
- 为什么适配?Adagrad 对每个特征的学习率单独调整,自动抵消特征尺度差异的影响,无需手动标准化(但仍建议做标准化,效果更稳定)。
- 反例:纯 SGD 或 Momentum 需严格标准化,否则会因特征尺度差异导致收敛困难。
3. 不需要手动调学习率的场景
- 场景特征:对调参效率要求高,希望学习率 “自适应”。
- 为什么适配?Adagrad 只需设置初始学习率 η,后续学习率由梯度累积自动调整,减少调参成本。
3.优缺点
优点
- 自适应学习率:自动为不同特征分配合适的学习率,适配稀疏数据和多尺度特征。
- 无需手动调学习率:只需设置初始学习率,降低调参门槛。
- 收敛稳定:对稀疏数据的收敛性优于纯 SGD 和 Momentum。
缺点
- 学习率单调递减:G_t 是累积的梯度平方和,只会增大不会减小,导致学习率持续下降,后期可能完全停滞(无法继续收敛)。
- 对初始学习率敏感:初始学习率η过大,前期学习率会过高,导致模型震荡;η 过小,后期学习率会过早衰减。
- 内存占用高:需存储每个参数的梯度平方累积值 G_t,对于千万级参数的模型(如大型神经网络),内存压力较大。
4.四种优化器的对比
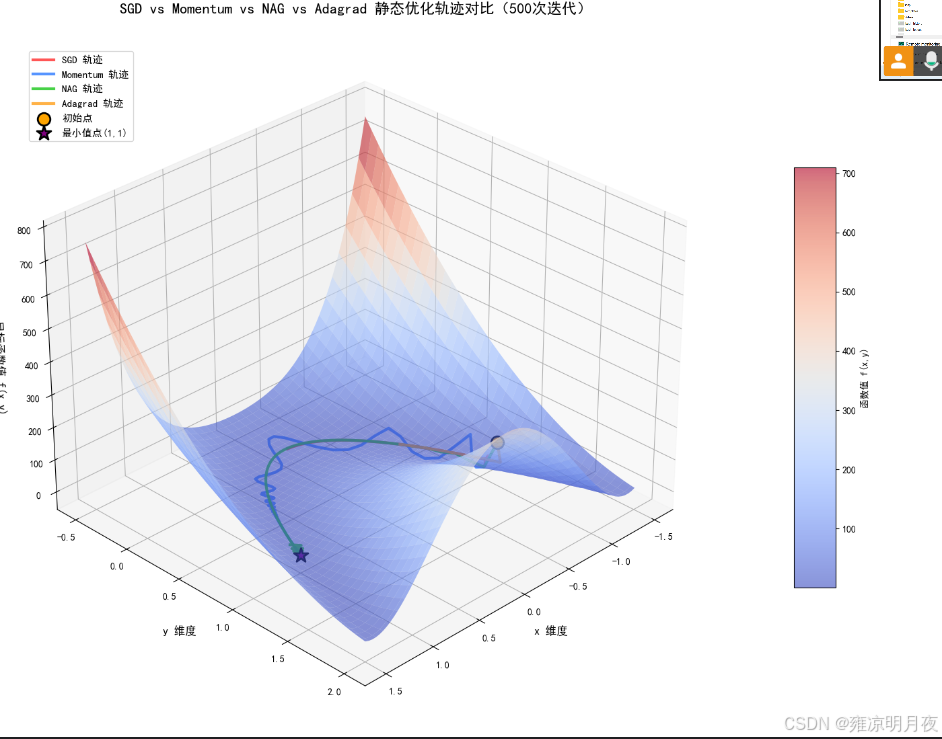
- 核心优势:每个算法的 “不可替代点”——SGD 胜在简单,Momentum 胜在抵消震荡,NAG 胜在前瞻加速,Adagrad 胜在自适应学习率。
1.本质:
RMSProp原理:在Adagrad的基础上把「累积梯度平方」改成「梯度平方的指数移动平均」(相当于 “只关注近期梯度,遗忘远期梯度”)

2.基于Adagrad的优化点
RmsProp算法是Adagrad算法的改进版本,其核心目标是修复Adagrad【学习率单调递减,后期收敛停滞不前】的问题——通过【指数移动平均】替代Adagrad的【梯度平方累积】,让学习率可升可降。
Adagrad 用![]() 累积梯度平方,导致 Gt只会越来越大,学习率
累积梯度平方,导致 Gt只会越来越大,学习率![]() 持续衰减,后期几乎无法更新参数。
持续衰减,后期几乎无法更新参数。
- Adagrad 像 “记仇的法官”:只要参数有过大幅更新(历史梯度大),就一直压低它的学习率;
- RMSProp 像 “灵活的教练”:只看参数「最近几次」的更新幅度(近期梯度),如果近期波动大就减速,近期波动小就加速,避免学习率 “一降到底”。
3.RMSProp 的核心优缺点 & 适用场景
优点
- 解决 Adagrad 停滞问题:指数移动平均让学习率 “可升可降”,后期仍能更新参数;
- 震荡极小:自适应学习率 + 近期梯度平滑,轨迹比 SGD、Momentum 更稳定;
- 适配非凸损失:对深度学习等复杂模型的非凸损失曲面,收敛效果远好于 Adagrad;
- 超参数易调:α = 0.9(默认值)几乎适配所有场景,只需微调初始学习率 η。
缺点
- 仍需手动设初始学习率:不像 Adagrad 完全不用调学习率,(eta) 太大仍会震荡;
- 稀疏数据表现略逊 Adagrad:Adagrad 对低频特征的 “大学习率” 分配更激进,稀疏数据(如文本)中 Adagrad 可能初期收敛更快;
- 无动量机制:收敛速度略逊于 NAG、Adam(缺少动量的加速效果)。
适用场景
- 深度学习模型:CNN、MLP、RNN 等非凸损失函数模型(替代 Adagrad 的首选);
- 非稀疏数据:图像、语音等特征密集的数据(Adagrad 后期停滞,RMSProp 更稳定);
- 需要稳定收敛的场景:对震荡敏感、追求后期持续优化的任务(如推荐系统的精排模型)。
4.五种优化器的对比
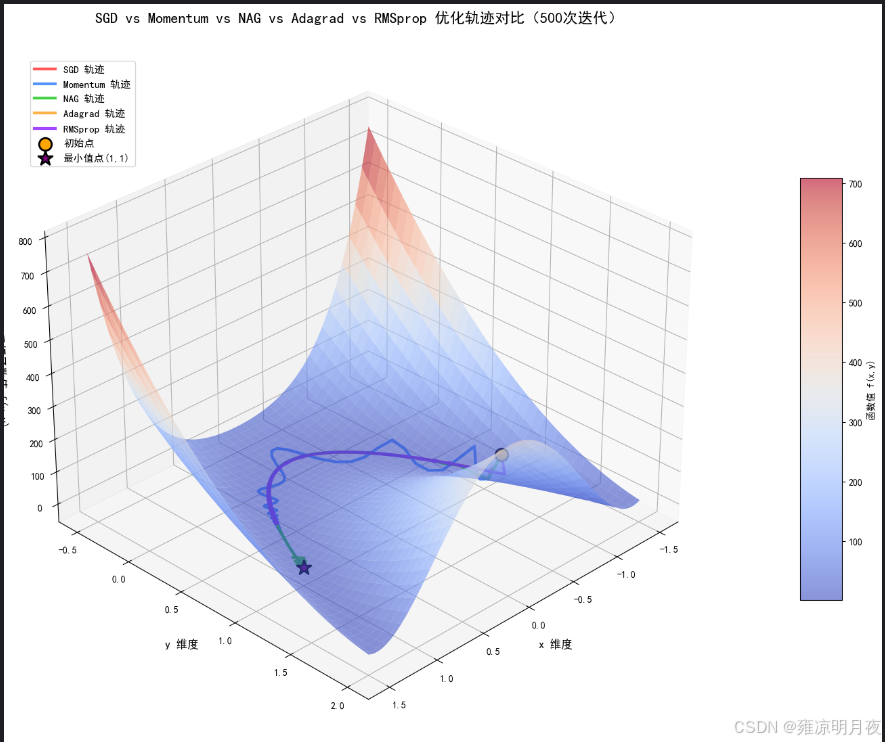
1.本质:
Adam 是当前机器学习最常用的优化器,核心是 “RMSProp 的自适应学习率 + Momentum 的动量加速”—— 可以理解为 “集大成者”,直接复用 RMSProp 和 Momentum 的代码逻辑。
Adam 核心定位:RMSProp + Momentum 的结合体
- 解决的问题:RMSProp 缺少动量(收敛速度略慢),Momentum 缺少自适应学习率(对特征尺度敏感);
- 核心思想:同时引入「动量的梯度累积」和「RMSProp 的自适应学习率」,兼顾 “加速收敛” 和 “稳定震荡”。


2.Adam优缺点&适用场景
1.本质:
Adadelta 是 Adagrad 的另一改进版,核心是 “解决 Adagrad 学习率停滞 + 无需手动设置初始学习率”—— 和 Adagrad 关联性强,但和你最近学的 RMSProp/Adam 关联性较弱,所以放在后面。
1. Adadelta 核心定位:Adagrad 的 “无学习率” 版本
- 解决的问题:Adagrad 学习率单调递减 + 依赖初始学习率;
- 核心思想:
- 用「指数移动平均」替代 Adagrad 的「梯度平方累积」(和 RMSProp 思路一致);
- 用「参数更新量的平方和」替代初始学习率 η,彻底无需手动设置学习率。

2.Adagrad/RMSProp差异
3.Adadelta优缺点
- 损失曲线:Adadelta 收敛速度略慢于 Adam/RMSProp,但远快于 Adagrad,且全程无停滞;
- R² 分数:Adadelta ≈ 0.97,接近 RMSProp,略逊于 Adam;
- 核心亮点:无需设置学习率,调参成本极低,适合不想纠结学习率的场景。
1.多种算法的对比
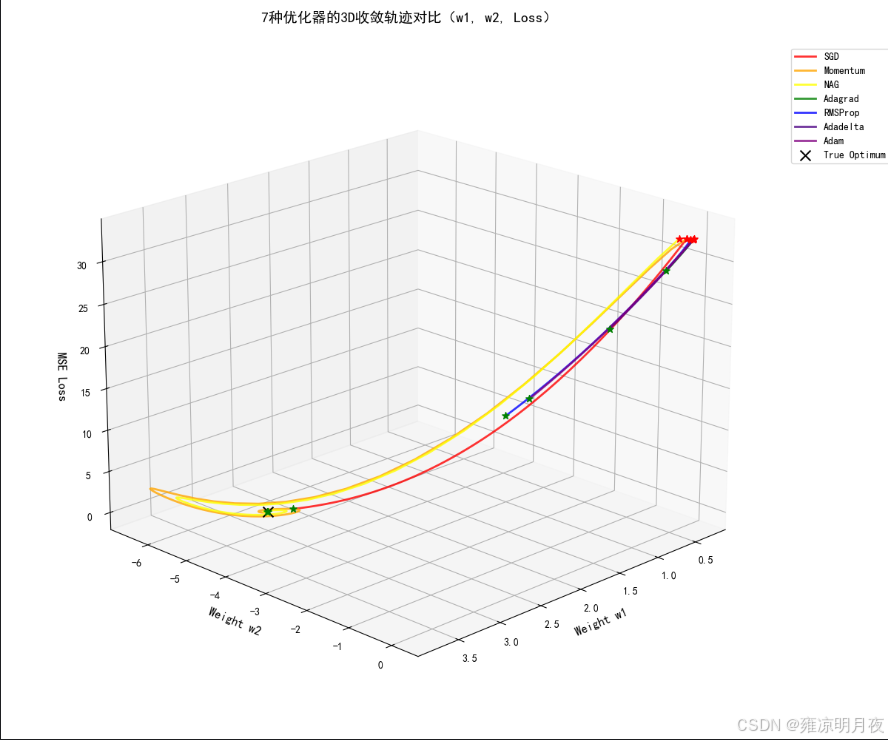
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import os
from mpl_toolkits.mplot3d import Axes3D
import numpy as np
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
plt.rcParams['font.sans-serif'] = ['SimHei'] # Windows系统默认中文字体(黑体)
plt.rcParams['axes.unicode_minus'] = False
# --------------------- 1. 生成2特征模拟数据(适配3D可视化) ---------------------
torch.manual_seed(42)
n_samples = 1000
X = torch.randn(n_samples, 2) # 仅2个特征(x1, x2),方便3D可视化
w_true = torch.tensor([3.0, -5.0]) # 真实权重(w1=3, w2=-5)
y = X @ w_true + torch.randn(n_samples) * 0.5 # 线性关系+噪声
# 划分训练集(无需测试集,重点看轨迹)
X_train, y_train = X, y
# --------------------- 2. 定义简单线性模型(仅2个权重参数) ---------------------
class LinearModel2D(nn.Module):
def __init__(self):
super().__init__()
# 仅2个权重(w1, w2)+ 1个偏置(b),偏置不参与3D轨迹(重点看w1, w2)
self.linear = nn.Linear(2, 1)
def forward(self, x):
return self.linear(x)
# --------------------- 3. 初始化7个模型(参数完全一致,保证公平对比) ---------------------
model_sgd = LinearModel2D()
model_momentum = LinearModel2D()
model_nag = LinearModel2D()
model_adagrad = LinearModel2D()
model_rmsprop = LinearModel2D()
model_adadelta = LinearModel2D()
model_adam = LinearModel2D()
# 统一初始化参数(所有模型初始权重相同)
torch.manual_seed(42)
init_w = torch.randn_like(model_sgd.linear.weight.data) # 初始权重(w1, w2)
init_b = torch.randn_like(model_sgd.linear.bias.data) # 初始偏置
models = [model_sgd, model_momentum, model_nag, model_adagrad, model_rmsprop, model_adadelta, model_adam]
for model in models:
model.linear.weight.data = init_w.clone()
model.linear.bias.data = init_b.clone()
# --------------------- 4. 定义损失函数和7种优化器 ---------------------
criterion = nn.MSELoss()
# 优化器配置(沿用之前的最优超参数)
optimizers = [
torch.optim.SGD(model_sgd.parameters(), lr=0.01), # 不变
torch.optim.SGD(model_momentum.parameters(), lr=0.01, momentum=0.9), # 不变
torch.optim.SGD(model_nag.parameters(), lr=0.01, momentum=0.9, nesterov=True), # 不变
torch.optim.Adagrad(model_adagrad.parameters(), lr=0.01), # 不变(简单模型后期停滞不明显)
torch.optim.RMSprop(model_rmsprop.parameters(), lr=0.01, alpha=0.9), # lr从0.001→0.01
torch.optim.Adadelta(model_adadelta.parameters(), rho=0.95, lr=1.0), # 给Adadelta加默认lr=1.0(官方默认)
torch.optim.Adam(model_adam.parameters(), lr=0.01, betas=(0.9, 0.999)) # lr从0.001→0.01
]
optimizer_names = ["SGD", "Momentum", "NAG", "Adagrad", "RMSProp", "Adadelta", "Adam"]
# --------------------- 5. 训练并记录轨迹(w1, w2, loss) ---------------------
epochs = 150 # 迭代次数适中,保证轨迹完整且不冗余
trajectories = [] # 存储7种优化器的轨迹:每个元素是 (w1_list, w2_list, loss_list)
for idx, (model, optimizer) in enumerate(zip(models, optimizers)):
w1_list = [] # 记录每次迭代的w1
w2_list = [] # 记录每次迭代的w2
loss_list = [] # 记录每次迭代的损失值
for epoch in range(epochs):
model.train()
optimizer.zero_grad()
y_pred = model(X_train)
loss = criterion(y_pred, y_train.unsqueeze(1))
loss.backward()
optimizer.step()
# 记录当前参数和损失(detach()避免计算图占用内存)
w1 = model.linear.weight.data[0][0].detach().item()
w2 = model.linear.weight.data[0][1].detach().item()
loss_val = loss.item()
w1_list.append(w1)
w2_list.append(w2)
loss_list.append(loss_val)
trajectories.append((w1_list, w2_list, loss_list))
print(f"{optimizer_names[idx]} 训练完成,最终损失:{loss_val:.6f}")
# --------------------- 6. 绘制3D收敛轨迹图 ---------------------
fig = plt.figure(figsize=(12, 10))
ax = fig.add_subplot(111, projection='3d')
# 定义7种颜色(区分不同优化器)
colors = ['red', 'orange', 'yellow', 'green', 'blue', 'indigo', 'purple']
markers = ['o', 's', '^', 'D', 'v', '<', '>'] # 轨迹点标记(可选,增强区分度)
# 绘制每个优化器的3D轨迹
for idx, (traj, name, color, marker) in enumerate(zip(trajectories, optimizer_names, colors, markers)):
w1, w2, loss = traj
# 绘制轨迹线(alpha=0.8:透明度,linewidth=2:线宽)
ax.plot(w1, w2, loss, color=color, label=name, linewidth=2, alpha=0.8)
# 绘制轨迹起点(红色标记,突出初始位置)
ax.scatter(w1[0], w2[0], loss[0], color='red', s=50, marker='*', zorder=10)
# 绘制轨迹终点(绿色标记,突出收敛位置)
ax.scatter(w1[-1], w2[-1], loss[-1], color='green', s=50, marker='*', zorder=10)
# 标记真实权重对应的“最优解点”(w1=3, w2=-5,loss≈0.25:噪声方差的平方)
ax.scatter(3.0, -5.0, 0.25, color='black', s=100, marker='x', label='True Optimum', zorder=15)
# 设置3D图标签和标题
ax.set_xlabel('Weight w1', fontsize=12)
ax.set_ylabel('Weight w2', fontsize=12)
ax.set_zlabel('MSE Loss', fontsize=12)
ax.set_title('7种优化器的3D收敛轨迹对比(w1, w2, Loss)', fontsize=14, pad=20)
# 添加图例(放在图外侧,避免遮挡轨迹)
ax.legend(loc='upper left', bbox_to_anchor=(1.05, 1), fontsize=10)
# 调整视角(让轨迹更清晰)
ax.view_init(elev=20, azim=45) # elev:仰角,azim:方位角
plt.tight_layout()
plt.show()
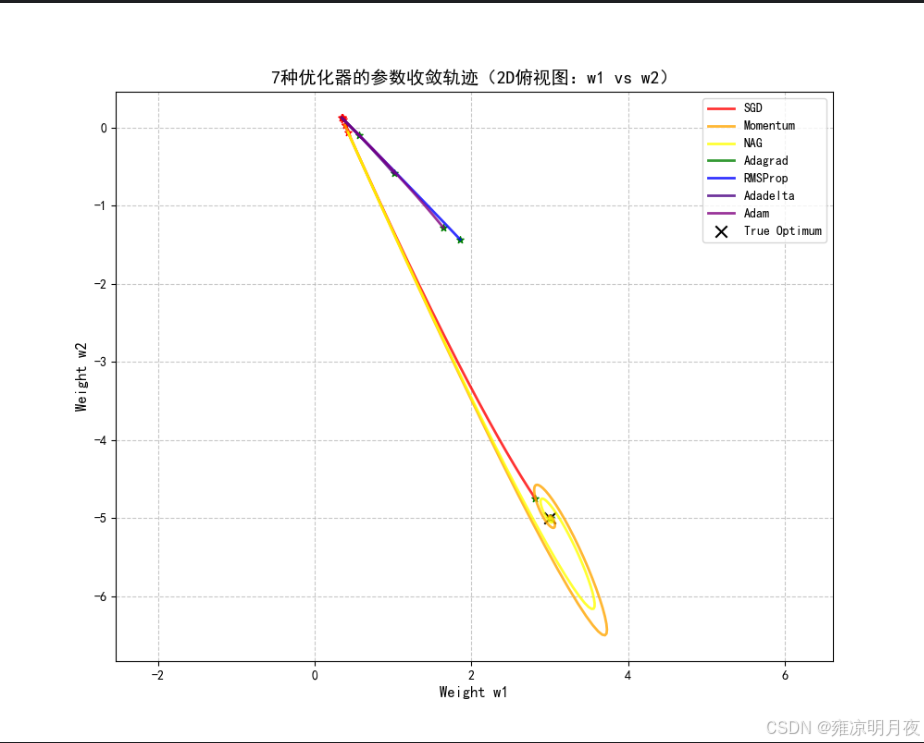
# --------------------- 7. 补充:2D俯视图(w1-w2平面,更易看参数收敛方向) ---------------------
plt.figure(figsize=(10, 8))
for idx, (traj, name, color) in enumerate(zip(trajectories, optimizer_names, colors)):
w1, w2, _ = traj
plt.plot(w1, w2, color=color, label=name, linewidth=2, alpha=0.8)
plt.scatter(w1[0], w2[0], color='red', s=30, marker='*') # 起点
plt.scatter(w1[-1], w2[-1], color='green', s=30, marker='*') # 终点
# 标记真实最优权重
plt.scatter(3.0, -5.0, color='black', s=80, marker='x', label='True Optimum')
plt.xlabel('Weight w1', fontsize=12)
plt.ylabel('Weight w2', fontsize=12)
plt.title('7种优化器的参数收敛轨迹(2D俯视图:w1 vs w2)', fontsize=14)
plt.legend()
plt.grid(True, linestyle='--', alpha=0.7)
plt.axis('equal') # 保证w1和w2轴刻度一致,轨迹无畸变
plt.show()2.实际使用选取
按模型复杂度
选取判断方式:
- 数据是否稀疏?→ 是→Adagrad,否→Adam/RMSProp;
- 模型是否复杂?→ 是→Adam/NAG,否→SGD/Adadelta;
- 能否接受调参?→ 否→Adadelta/Adam(默认),是→NAG/SGD(精细调参)。
3.小结
本文是笔者在学习梯度下降算法的时候,所整理这7种算法之间的联系和相应的区别,供自己学习和总结,希望能给大家带来帮助,更好的理解这些常见的梯度下降算法,后续有新的总结会持续更新,如果大家发现有问题或错误,欢迎大家指出!感谢!









