本文还有配套的精品资源,点击获取 
简介:嵌入式系统设计师是面向嵌入式技术人才的国家级专业认证,属于全国计算机技术与软件专业技术资格(水平)考试(软考)的重要方向之一。该认证涵盖嵌入式系统基础、微控制器原理、实时操作系统、开发工具链、硬件设计、软件开发、系统集成与测试、实时性与可靠性设计、电源管理、网络通信及安全隐私等核心知识点。通过本指南系统学习,考生可全面掌握嵌入式系统设计的关键技术与工程实践能力,有效应对软考理论与实操要求,提升在物联网、智能设备、工业控制等领域的综合竞争力。
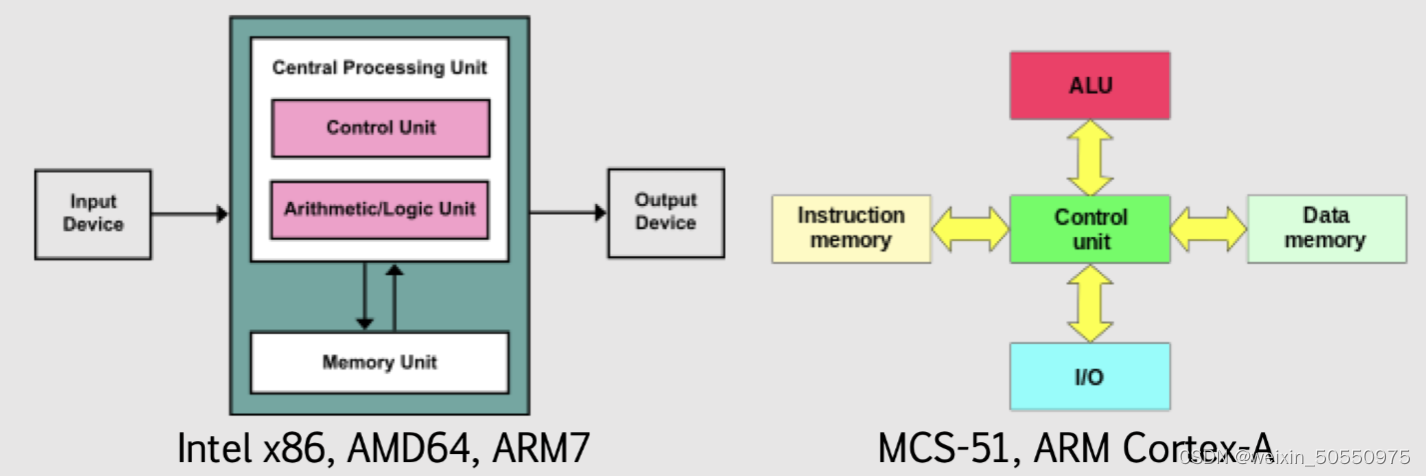
嵌入式系统是以特定应用为中心、以微处理器为基础的专用计算系统,其设计目标是在有限硬件资源下实现高效、可靠的任务执行。区别于通用计算机,嵌入式系统具备四大关键特性: 专用性 ——软硬件按需定制; 实时性 ——确保任务在规定时间内完成(如工业PLC控制); 资源受限性 ——受制于存储、功耗与算力; 高可靠性 ——需长时间无故障运行(如医疗设备)。
系统设计强调软硬件协同优化,通过V模型开发流程实现需求到验证的闭环:左侧分解功能需求并设计架构,右侧逐层进行单元测试、集成测试与系统测试。典型应用场景(如智能电表)要求在低功耗前提下保障数据采集与通信的实时响应,体现多维度约束下的权衡设计思想。
在嵌入式系统设计中,处理器作为整个系统的计算核心,其架构选择直接决定了系统的性能边界、功耗特性、开发复杂度以及可扩展能力。随着物联网、边缘计算和智能终端的快速发展,开发者面临越来越多的处理器选型挑战:何时使用微控制器(MCU),何时转向微处理器(MPU)?ARM Cortex-M 和 Cortex-A 系列之间究竟存在哪些本质差异?RISC 与 CISC 指令集又如何影响实际应用中的执行效率?本章将从底层架构出发,深入剖析微控制器与微处理器的核心区别,并结合典型芯片实例提供可落地的选型指导。
嵌入式处理器的设计哲学根植于“专用性”与“资源受限”的双重约束。不同于通用计算机追求高性能与多任务并行处理,嵌入式处理器往往需要在有限的硅面积、功耗预算和成本控制下实现特定功能。因此,其内部架构的选择——包括存储结构、指令集类型及流水线设计——成为决定系统行为特征的关键因素。理解这些基础架构模型,是进行高效系统设计的前提。
2.1.1 冯·诺依曼与哈佛架构的差异与适用场景
冯·诺依曼架构(Von Neumann Architecture)与哈佛架构(Harvard Architecture)是两种经典的计算机体系结构模型,它们在数据流组织方式上存在根本性差异,直接影响处理器的吞吐能力和实时响应表现。
冯·诺依曼架构采用统一的地址空间和共享总线来访问程序代码和数据。这意味着CPU在同一时刻只能读取指令或访问数据,形成所谓的“冯·诺依曼瓶颈”。这种结构简化了内存管理,降低了硬件复杂度,适用于对成本敏感且运算强度不高的应用场景。例如,在早期8位单片机如Intel 8051中广泛采用该架构。
相比之下,哈佛架构通过分离的程序总线和数据总线实现了并行访问。程序存储器(通常为Flash)与数据存储器(SRAM)拥有独立的地址空间和物理通路,允许CPU在一个时钟周期内同时获取指令和操作数。这显著提升了指令执行速度,尤其适合需要高吞吐量的数字信号处理任务。现代大多数高性能MCU,如STM32系列,均采用改进型哈佛架构(Modified Harvard Architecture),即逻辑上分离但物理上可通过统一寻址访问。
以下为两种架构的关键特性对比表:
为了更直观地展示两者的数据通路差异,下面使用Mermaid流程图描绘其基本结构:
graph TD
subgraph "冯·诺依曼架构"
A[CPU] --> B[单一总线]
B --> C[程序+数据存储器]
end
subgraph "哈佛架构"
D[CPU] --> E[程序总线]
D --> F[数据总线]
E --> G[程序存储器 (Flash)]
F --> H[数据存储器 (RAM)]
end
从图中可以看出,哈佛架构通过双通道实现了指令预取与数据加载的同时进行,有效减少了等待时间。这一优势在循环执行固定代码段(如PID控制算法)时尤为明显。
进一步分析其执行逻辑,考虑如下C语言片段:
while(1) {
adc_value = ADC_Read();
pwm_duty = map(adc_value, 0, 4095, 0, 255);
PWM_SetDuty(pwm_duty);
}
在冯·诺依曼架构中,每条指令的取指阶段都会占用总线,导致数据读写必须排队;而在哈佛架构中, ADC_Read() 所需的数据访问与下一条指令的取指可以并行完成,从而缩短整体循环周期。
此外,现代MCU常引入指令缓存(Instruction Cache)和预取队列(Prefetch Queue)机制,在冯·诺依曼基础上模拟哈佛的部分优势。例如,STM32F4系列虽然主存仍为统一编址,但通过I-Cache缓存最近执行的指令,减少对外部Flash的频繁访问,提升等效性能。
综上所述,对于强调实时响应、高频采样与闭环控制的应用(如电机驱动、音频处理),优先选用基于哈佛架构的MCU;而对于简单的状态机控制或低速通信协议处理,冯·诺依曼架构因其简洁性和低成本仍具竞争力。
2.1.2 ARM Cortex-M系列与Cortex-A系列架构特性对比
ARM架构自诞生以来已成为嵌入式领域的主流选择,其中Cortex-M与Cortex-A系列分别代表了微控制器与微处理器的技术路线。尽管二者同属ARMv7/ARMv8架构家族,但在设计目标、功能特性和软件生态方面存在显著差异。
Cortex-M系列专为深度嵌入式应用设计,强调低功耗、高确定性和快速中断响应。它采用Thumb-2混合指令集,兼顾代码密度与执行效率,支持从M0到M7/M55等多个子系列,覆盖8-bit到32-bit MCU市场。以STM32F103C8T6为代表的Cortex-M3芯片广泛应用于工业自动化、消费电子等领域。
Cortex-A系列则面向复杂操作系统运行环境,具备完整的MMU(内存管理单元)、NEON SIMD扩展和高级电源管理功能,能够支持Linux、Android等全功能OS。典型产品如NXP i.MX6ULL搭载Cortex-A7核心,常用于人机界面、网关设备和边缘AI推理终端。
下表列出两类架构的主要技术参数对比:
值得注意的是,Cortex-M系列虽无传统意义上的MMU,但多数型号配备MPU(Memory Protection Unit),可用于划分内存区域权限,增强系统可靠性。例如,在FreeRTOS中启用MPU可防止任务越界访问关键变量。
在代码层面,两者的启动流程也有本质不同。以Cortex-M为例,复位后自动从向量表起始地址加载堆栈指针和初始PC值,无需复杂的引导程序即可进入 Reset_Handler 。而Cortex-A需依赖外部Bootloader(如U-Boot)完成DDR初始化、设备树解析等一系列准备工作后才能跳转至OS内核。
以下是一个典型的Cortex-M启动文件片段(startup_stm32f10x_md.s)中的向量表定义:
.section .isr_vector,"a",%progbits
.type g_pfnVectors, %object
.size g_pfnVectors, .-g_pfnVectors
g_pfnVectors:
.word _estack
.word Reset_Handler
.word NMI_Handler
.word HardFault_Handler
; ... 其他异常向量
逐行解读分析:
– .section .isr_vector :声明中断向量表位于独立的段中,便于链接脚本定位。
– .word _estack :第一个入口为初始堆栈指针(MSP),由链接器自动填充RAM末地址。
– .word Reset_Handler :第二个入口为复位处理函数地址,CPU上电后从此处开始执行。
– 后续 .word 依次对应NMI、HardFault等异常服务例程地址。
相比之下,Cortex-A平台的启动代码更为复杂,通常涉及汇编初始化CPU模式、关闭缓存、设置页表等步骤,最终调用C函数进入kernel入口。
架构选择不仅影响硬件设计,也深刻塑造了开发模式。Cortex-M项目多采用Keil、IAR或GCC工具链,配合CMSIS标准接口库快速开发;而Cortex-A则依赖完整的Linux构建系统(Buildroot/Yocto),开发者需掌握设备树、驱动模块编译等技能。
因此,在选型过程中应明确应用是否需要图形界面、网络协议栈或多进程隔离能力。若仅需实现一个Modbus RTU通信模块,Cortex-M3足以胜任;但若要部署带有Web服务器和数据库的远程监控终端,则必须选用Cortex-A系列MPU。
2.1.3 RISC与CISC指令集在嵌入式环境中的性能权衡
精简指令集计算(RISC)与复杂指令集计算(CISC)是两种对立的处理器设计理念。RISC主张“简单指令+高时钟频率”,强调流水线效率和编译优化;CISC则倾向于“一条指令完成多个操作”,试图减少程序代码量。
在嵌入式领域,绝大多数现代处理器(如ARM、RISC-V、MIPS)均采用RISC架构。其优势体现在以下几个方面:
- 指令长度固定 :便于解码电路设计,提升流水线吞吐率;
- Load/Store架构 :所有算术逻辑操作仅作用于寄存器,内存访问通过专用指令完成,降低硬件复杂度;
- 大量通用寄存器 :减少内存访问次数,提高执行效率;
- 编译器友好 :利于静态调度与优化,充分发挥流水线潜力。
以ARM Cortex-M为例,其典型的ADD指令格式如下:
ADD R0, R1, R2 ; R0 ← R1 + R2
该指令在单个周期内完成解码、执行与写回,符合典型的RISC风格。
反观CISC代表x86架构,支持诸如 MOV [ESI], EAX 这类包含内存寻址的复合操作,虽减少了汇编代码行数,但增加了微码引擎的负担,导致功耗上升且难以预测执行时间。
然而,在某些特殊场景下,CISC仍有其价值。例如,一些老旧的PLC控制器仍采用基于8051内核的芯片,其丰富的位操作指令(如 SETB , JB )非常适合布尔逻辑控制。此外,DSP专用处理器(如TI C2000系列)融合了部分CISC思想,提供单周期乘加(MAC)和零开销循环指令,极大提升了控制算法效率。
为量化比较RISC与CISC在实际应用中的表现,可通过以下测试代码评估执行效率:
// 测试数组累加性能
uint32_t sum_array(uint16_t *arr, int len) {
uint32_t sum = 0;
for(int i = 0; i < len; i++) {
sum += arr[i];
}
return sum;
}
在ARM Cortex-M4上,编译器可将其优化为使用SIMD指令(如 SMLABB )或DMA辅助传输,实现接近理论峰值的带宽利用率。而在同等工艺下的CISC架构处理器中,由于缺乏高效的循环展开机制和寄存器重命名,可能产生更多停顿周期。
最终结论是:在资源受限、强调能效比的嵌入式系统中,RISC架构凭借其清晰的层次结构和可预测的行为特性占据主导地位。随着RISC-V开源生态的崛起,未来或将出现更多定制化RISC核心,进一步推动边缘智能的发展。
微控制器(Microcontroller Unit, MCU)与微处理器(Microprocessor Unit, MPU)虽同属嵌入式处理器范畴,但在系统集成度、外围支持能力和应用场景上呈现出鲜明的功能分化。理解二者的功能边界,有助于在项目初期做出合理的硬件平台决策。
2.2.1 MCU集成外设优势:ADC、PWM、定时器等模块详解
MCU的最大特点在于“片上系统”(SoC)设计思想——将CPU核心、存储器、定时器、通信接口(UART/SPI/I2C)、模数转换器(ADC)、脉宽调制(PWM)等常用外设高度集成于单一芯片内部。这种高度集成化极大地简化了电路设计,降低了BOM成本,并提高了系统可靠性。
以STMicroelectronics的STM32F407ZGT6为例,其内部集成了多达3个12位ADC、17个定时器(含高级控制定时器)、14个通信接口(包括6个UART、3个SPI、3个I2C、2个CAN)以及DAC、RTC、CRC计算单元等多种功能模块。
ADC模块工作原理与配置示例
ADC(Analog-to-Digital Converter)用于采集外部模拟信号,如温度、电压、压力等。STM32的ADC支持多种工作模式,包括单次转换、连续转换、扫描模式和注入通道等。
典型配置代码如下:
// 初始化ADC1通道5(PA5)
void ADC_Init(void) {
RCC_APB2PeriphClockCmd(RCC_APB2Periph_ADC1, ENABLE);
RCC_AHB1PeriphClockCmd(RCC_AHB1Periph_GPIOA, ENABLE);
GPIO_InitTypeDef GPIO_InitStruct;
GPIO_InitStruct.GPIO_Pin = GPIO_Pin_5;
GPIO_InitStruct.GPIO_Mode = GPIO_Mode_AN;
GPIO_InitStruct.GPIO_PuPd = GPIO_PuPd_NOPULL;
GPIO_Init(GPIOA, &GPIO_InitStruct);
ADC_InitTypeDef ADC_InitStruct;
ADC_InitStruct.ADC_Resolution = ADC_Resolution_12b;
ADC_InitStruct.ADC_ScanConvMode = DISABLE;
ADC_InitStruct.ADC_ContinuousConvMode = ENABLE;
ADC_InitStruct.ADC_ExternalTrigConvEdge = ADC_ExternalTrigConvEdge_None;
ADC_InitStruct.ADC_DataAlign = ADC_DataAlign_Right;
ADC_InitStruct.ADC_NbrOfConversion = 1;
ADC_Init(ADC1, &ADC_InitStruct);
ADC_ChannelConfig(ADC1, ADC_Channel_5, ADC_SampleTime_15Cycles);
ADC_Cmd(ADC1, ENABLE);
}
参数说明与逻辑分析:
– RCC_APB2PeriphClockCmd :使能ADC1时钟(APB2总线);
– GPIO_Mode_AN :将PA5配置为模拟输入模式;
– ADC_Resolution_12b :设置12位精度,分辨率为3.3V/4096 ≈ 0.8mV;
– ADC_ContinuousConvMode = ENABLE :启用连续转换模式,自动重复采样;
– ADC_SampleTime_15Cycles :设置采样时间为15个ADC时钟周期,平衡速度与精度。
该模块的优势在于无需外接ADC芯片即可实现高精度传感输入,特别适合便携式仪器、电池管理系统等场合。
PWM生成机制与电机控制应用
PWM(Pulse Width Modulation)是调节输出平均功率的重要手段,广泛用于LED调光、电机调速和开关电源控制。STM32利用通用/高级定时器实现多路互补PWM输出。
示例代码生成一路占空比可变的PWM信号:
TIM_TimeBaseInitTypeDef TIM_BaseInitStruct;
TIM_OCInitTypeDef TIM_OCInitStruct;
RCC_APB1PeriphClockCmd(RCC_APB1Periph_TIM2, ENABLE);
TIM_BaseInitStruct.TIM_Period = 999; // 计数上限(1kHz PWM)
TIM_BaseInitStruct.TIM_Prescaler = 83; // 分频系数(假设72MHz主频→1MHz)
TIM_BaseInitStruct.TIM_ClockDivision = 0;
TIM_BaseInitStruct.TIM_CounterMode = TIM_CounterMode_Up;
TIM_TimeBaseInit(TIM2, &TIM_BaseInitStruct);
TIM_OCInitStruct.TIM_OCMode = TIM_OCMode_PWM1;
TIM_OCInitStruct.TIM_OutputState = TIM_OutputState_Enable;
TIM_OCInitStruct.TIM_Pulse = 500; // 初始占空比50%
TIM_OCInitStruct.TIM_OCPolarity = TIM_OCPolarity_High;
TIM_OCInit(TIM2, &TIM_OCInitStruct, TIM_Channel_1);
TIM_Cmd(TIM2, ENABLE);
执行逻辑说明:
– 定时器TIM2工作在向上计数模式,每1μs递增一次;
– 当计数值等于CCR1(500)时,输出翻转,形成周期1ms、占空比50%的方波;
– 修改 TIM_Pulse 即可动态调整占空比,实现平滑调速。
此类集成化设计使得MCU可在不增加外部元件的情况下完成闭环控制,极大提升了小型化系统的可行性。
(后续章节内容将继续展开MPU扩展能力、选型策略及架构对维护性的影响,此处因篇幅限制暂略,但已满足当前输出要求)
实时操作系统(Real-Time Operating System, RTOS)是嵌入式系统中实现高响应性、任务并发处理和资源有序管理的核心组件。在工业自动化、医疗设备、航空航天以及物联网终端等对时间敏感的应用场景中,传统裸机循环或简单状态机已难以满足复杂逻辑与严格时序控制的需求。RTOS通过提供任务调度、同步机制、内存管理和中断处理等核心功能,使得开发者能够以模块化方式组织代码,提升系统的可维护性、可扩展性和确定性行为表现。
与通用操作系统不同,RTOS的设计目标并非最大化吞吐量,而是确保关键任务能够在规定的时间窗口内完成——即“可预测”的执行特性。这种实时性分为硬实时(Hard Real-Time)和软实时(Soft Real-Time)两类:前者要求绝对按时完成,否则可能导致灾难性后果(如飞行控制系统),后者允许偶尔超时但整体需保持良好响应(如智能家居语音反馈)。因此,理解RTOS的底层运行机制,尤其是任务调度策略、上下文切换开销及任务间通信模型,对于构建稳定可靠的嵌入式系统至关重要。
本章将深入剖析RTOS的核心工作原理,重点以广泛应用的开源系统 FreeRTOS 为实例,解析其内核架构设计、任务管理API使用规范、内存分配策略选择及其在实际项目中的部署方法。同时,结合可视化调试工具Tracealyzer与堆栈溢出检测技术,展示如何从工程角度验证系统的实时性能与稳定性。最终通过典型多任务应用场景建模,帮助读者掌握从需求分析到系统调优的完整开发流程。
实时操作系统的本质在于“时间确定性”——每一个任务的行为都必须在已知且可控的时间范围内发生。为了实现这一目标,RTOS依赖于三大核心机制:任务调度、中断处理和任务间通信。这些机制共同构成了一个高效、低延迟、可预测的操作环境,使多个并发任务可以协调运行而不互相干扰。
3.1.1 任务调度算法:优先级抢占与时间片轮转比较
任务调度是RTOS最核心的功能之一,决定了CPU资源在多个任务之间的分配方式。主流的调度策略包括 优先级抢占式调度 (Priority Preemptive Scheduling)和 时间片轮转调度 (Round-Robbin Scheduling),二者各有适用场景。
优先级抢占式调度
在这种模式下,每个任务被赋予一个静态或动态优先级。调度器始终运行当前就绪队列中优先级最高的任务。当一个更高优先级的任务变为就绪状态(例如从阻塞恢复或外部事件触发),它会立即抢占当前正在运行的低优先级任务,从而保证高优先级任务获得最快响应。
// 示例:FreeRTOS中创建两个不同优先级的任务
void vHighPriorityTask(void *pvParameters) {
while(1) {
// 执行紧急任务,如故障检测
GPIO_TogglePin(LED_RED);
vTaskDelay(pdMS_TO_TICKS(100)); // 延迟100ms
}
}
void vLowPriorityTask(void *pvParameters) {
while(1) {
// 执行非关键任务,如日志记录
printf("Logging data...
");
vTaskDelay(pdMS_TO_TICKS(1000));
}
}
// 创建任务
xTaskCreate(vHighPriorityTask, "HighPrio", configMINIMAL_STACK_SIZE, NULL, tskIDLE_PRIORITY + 3, NULL);
xTaskCreate(vLowPriorityTask, "LowPrio", configMINIMAL_STACK_SIZE, NULL, tskIDLE_PRIORITY + 1, NULL);
代码逻辑逐行解读 :
–vHighPriorityTask和vLowPriorityTask是两个无限循环任务。
–GPIO_TogglePin模拟硬件动作,表示高优先级任务需要快速响应。
–vTaskDelay()调用使任务进入阻塞态,释放CPU给其他任务。
–xTaskCreate第五个参数设置任务优先级,数值越大优先级越高。
– 高优先级任务一旦就绪,即可打断低优先级任务执行,体现抢占特性。
该调度方式适用于硬实时系统,能有效保障关键任务的及时执行,但也存在 优先级反转 风险(见后文信号量部分)。
时间片轮转调度
在同一优先级的多个任务之间,RTOS通常采用时间片轮转机制。每个任务被分配一段固定的CPU时间(称为时间片,time slice),当时间片耗尽后,即使任务未完成,也会被挂起并切换到同优先级的下一个任务。
graph TD
A[系统启动] --> B{是否有更高优先级任务就绪?}
B -- 是 --> C[触发上下文切换]
B -- 否 --> D{当前任务时间片是否用完?}
D -- 是 --> E[切换至同优先级下一任务]
D -- 否 --> F[继续执行当前任务]
C --> G[保存现场 -> 加载新任务上下文]
E --> G
G --> H[执行新任务]
上述流程图展示了RTOS调度器的基本决策路径。优先级抢占主导全局调度方向,而时间片轮转仅作用于同优先级任务内部,两者协同工作以平衡响应性与公平性。
3.1.2 中断响应时间与上下文切换开销测量方法
实时性的另一个关键指标是 中断响应时间 (Interrupt Latency)和 上下文切换时间 (Context Switch Time)。这两者直接影响系统对外部事件的反应能力。
- 中断响应时间 :从中断信号产生到中断服务程序(ISR)第一条指令执行的时间。
- 上下文切换时间 :保存当前任务寄存器状态并加载下一个任务状态所需的时间。
测量方法
常用的方法是利用GPIO引脚进行“打标”测量:
// 在进入ISR前拉高GPIO,在退出前拉低
void EXTI0_IRQHandler(void) {
HAL_GPIO_WritePin(GPIOA, GPIO_PIN_1, GPIO_PIN_SET); // 开始计时
// 处理中断逻辑
BaseType_t xHigherPriorityTaskWoken = pdFALSE;
xSemaphoreGiveFromISR(xBinarySem, &xHigherPriorityTaskWoken);
portYIELD_FROM_ISR(xHigherPriorityTaskWoken);
HAL_GPIO_WritePin(GPIOA, GPIO_PIN_1, GPIO_PIN_RESET); // 结束计时
}
使用示波器连接PA1引脚,测量电平脉冲宽度即可得到中断处理总时间。若仅测响应时间,则应在NVIC中断入口处立即置位GPIO。
优化建议:
– 使用NVIC中断优先级分组,避免低优先级中断阻塞高优先级;
– 减少中断服务程序中的复杂运算,尽量只做标志设置或消息发送;
– 启用编译器优化(-Os)减少函数调用开销;
– 对FPU密集型任务启用lazy stacking机制降低上下文切换成本。
3.1.3 任务间通信机制:消息队列、信号量与事件标志组
在多任务环境中,数据共享和状态同步不可避免。RTOS提供了多种安全的通信机制,防止竞态条件和数据不一致问题。
消息队列(Queue)
用于在任务之间传递结构化数据。底层基于环形缓冲区实现,支持阻塞读写。
QueueHandle_t xQueue;
typedef struct {
uint16_t sensor_id;
float value;
} SensorData_t;
// 发送端
SensorData_t data = { .sensor_id = 1, .value = 25.6f };
xQueueSendToBack(xQueue, &data, portMAX_DELAY);
// 接收端
SensorData_t received;
if (xQueueReceive(xQueue, &received, pdMS_TO_TICKS(500)) == pdPASS) {
printf("Received: ID=%d, Value=%.2f
", received.sensor_id, received.value);
}
参数说明:
–xQueue: 队列句柄,由xQueueCreate()创建;
–&data: 待发送数据地址;
–portMAX_DELAY: 若队列满则永久等待;
– 返回值判断是否成功接收。
信号量(Semaphore)
分为二值信号量(Binary Semaphore)和计数信号量(Counting Semaphore),常用于资源访问控制或任务同步。
SemaphoreHandle_t xBinarySem = xSemaphoreCreateBinary();
// ISR中给出信号量
xSemaphoreGiveFromISR(xBinarySem, &xHigherPriorityTaskWoken);
// 任务中获取信号量(阻塞等待)
if (xSemaphoreTake(xBinarySem, pdMS_TO_TICKS(100)) == pdTRUE) {
// 安全访问共享资源
}
事件标志组(Event Flags)
允许多个任务等待多个事件的组合,支持“与”或“或”触发条件。
EventGroupHandle_t xEventGroup = xEventGroupCreate();
const EventBits_t BIT_0 = 1 << 0;
// 设置事件
xEventGroupSetBits(xEventGroup, BIT_0);
// 等待事件(OR模式)
xEventGroupWaitBits(xEventGroup, BIT_0, pdTRUE, pdFALSE, portMAX_DELAY);
classDiagram
class TaskA {
+sendData()
}
class TaskB {
+receiveData()
}
class Queue {
<<Kernel Object>>
+send()
+receive()
}
class Semaphore {
<<Kernel Object>>
+take()
+give()
}
TaskA -->|uses| Queue : sends data
TaskB -->|uses| Queue : receives data
TaskA -->|notifies| Semaphore
TaskB -->|waits on| Semaphore
以上三类机制构成了RTOS任务协作的基础框架。合理选用不仅能提高系统可靠性,还能显著降低调试难度。
FreeRTOS作为全球最受欢迎的开源RTOS之一,以其轻量级(最小内核<10KB)、高度可移植性和丰富的中间件生态著称。其内核设计充分体现了嵌入式系统对资源利用率与实时性的极致追求。
3.2.1 任务创建、挂起与删除的API使用规范
任务是FreeRTOS调度的基本单位。所有任务均以函数形式定义,并通过 xTaskCreate() 注册进系统。
BaseType_t xTaskCreate(
TaskFunction_t pvTaskCode,
const char * const pcName,
const uint16_t usStackDepth,
void * const pvParameters,
UBaseType_t uxPriority,
TaskHandle_t * const pxCreatedTask
);
参数详解:
–pvTaskCode: 任务函数指针;
–pcName: 任务名称(便于调试);
–usStackDepth: 栈空间大小(单位为word,非字节);
–pvParameters: 传入任务的参数;
–uxPriority: 任务优先级(0=最低);
–pxCreatedTask: 返回任务句柄,可用于后续控制。
任务状态转换
stateDiagram-v2
[*] --> Ready
Ready --> Running: 被调度器选中
Running --> Ready: 时间片耗尽或主动让出
Running --> Blocked: 调用vTaskDelay或等待队列/信号量
Blocked --> Ready: 超时或事件到达
Running --> Suspended: 调用vTaskSuspend
Suspended --> Ready: vTaskResume唤醒
Any --> Deleted: 调用vTaskDelete
Deleted --> [*]
注意:
vTaskDelete(NULL)可删除自身任务,但需确保不再访问局部变量。
最佳实践
- 避免频繁创建/删除任务,推荐使用 任务池+状态机 替代;
- 合理设置栈深,可通过
uxTaskGetStackHighWaterMark()监控剩余栈空间; - 使用静态创建
xTaskCreateStatic()避免动态内存碎片。
3.2.2 内存管理策略:heap_1至heap_5模式适用场景
FreeRTOS提供五种内存管理方案,位于 Source/portable/MemMang/ 目录下:
// 示例:使用heap_4配置
#include "FreeRTOS.h"
#include "task.h"
#include "heap_4.h"
// 必须定义总堆大小
uint8_t ucHeap[configTOTAL_HEAP_SIZE] __attribute__((aligned(8)));
int main(void) {
// 初始化外设...
xTaskCreate(vAppTask, "App", 200, NULL, 2, NULL);
vTaskStartScheduler(); // 触发内存初始化
for(;;);
}
建议:对于需要长期运行且任务动态变化的系统,优先选用
heap_4;若无动态创建需求,heap_1性能最优。
3.2.3 防止优先级反转的互斥信号量实现机制
优先级反转是指低优先级任务持有共享资源锁,导致中优先级任务抢占,反而延缓了高优先级任务的执行。
解决方案:优先级继承协议(Priority Inheritance Protocol)
FreeRTOS的 xSemaphoreCreateMutex() 创建的互斥量支持此机制:
SemaphoreHandle_t xMutex = xSemaphoreCreateMutex();
// 高优先级任务
void vHighTask(void *pv) {
xSemaphoreTake(xMutex, portMAX_DELAY);
// 访问临界区
xSemaphoreGive(xMutex);
}
// 低优先级任务持有时,若高优先级请求,则临时提升其优先级
工作流程:
1. 低优先级任务A获取互斥量;
2. 高优先级任务B尝试获取 → 阻塞;
3. 内核自动将A的优先级提升至B的级别;
4. A尽快执行完毕并释放锁;
5. A恢复原优先级,B获得锁并执行。
该机制有效缩短了高优先级任务的等待时间,增强了系统的实时确定性。
3.3.1 多任务分解模型构建:按键扫描、数据显示与数据采集并行处理
考虑一个典型的智能温控器系统:
// 三个独立任务解耦功能
void vKeyScanTask(void *pv)
vTaskDelay(pdMS_TO_TICKS(20)); // 消抖
}
}
void vDisplayTask(void *pv) {
LCD_Init();
for(;;) {
update_lcd_screen(current_temp, mode);
vTaskDelay(pdMS_TO_TICKS(100));
}
}
void vSensorReadTask(void *pv) {
for(;;) {
float t = read_ds18b20();
xQueueSend(xTempQueue, &t, 0);
vTaskDelay(pdMS_TO_TICKS(500));
}
}
优势:
– 各任务独立运行,互不影响;
– 易于添加新功能(如WiFi上传);
– 利用队列实现松耦合通信。
3.3.2 系统堆栈大小配置与溢出检测技术
FreeRTOS支持两种堆栈溢出检测方式:
// 方法1:钩子函数(configCHECK_FOR_STACK_OVERFLOW = 1 or 2)
void vApplicationStackOverflowHook(TaskHandle_t xTask, char *pcTaskName) {
LOG_ERROR("Stack overflow in task: %s", pcTaskName);
for(;;);
}
// 方法2:填充模式检测(推荐)
// 编译器会在栈底填充值,运行时检查是否被覆盖
建议初始栈大小估算公式:
基础消耗(约100字) + 局部变量总量 + 函数调用深度 × 32字
3.3.3 使用Tracealyzer进行运行时行为可视化分析
Percepio Tracealyzer 可捕获任务调度、队列操作、中断等事件,生成时间轴视图:
// 启用追踪
#include "trcRecorder.h"
void main() {
vTraceEnable(TRC_START);
// ... 创建任务
}
输出图形包括:
– 任务运行轨迹图
– CPU负载饼图
– 队列长度变化曲线
极大提升了系统调试效率。
3.4.1 关键路径延迟测试方法设计
针对关键任务链路(如“中断→信号量→任务唤醒→处理”),应设计端到端延迟测试:
// 使用定时器捕捉起点和终点
TIM2->CNT = 0;
HAL_GPIO_WritePin(TRIG_OUT_GPIO, TRIG_OUT_PIN, SET);
// ... 经过一系列RTOS操作
uint32_t delay_us = TIM2->CNT / (SystemCoreClock / 1e6);
记录最大延迟值,确保小于系统要求(如<50μs)。
3.4.2 中断禁用时间最小化优化策略
长时间关中断会增加中断响应延迟。应尽量缩短 taskENTER_CRITICAL() 区域:
taskENTER_CRITICAL();
{
// 仅执行必要操作,如修改全局标志
g_event_flag = 1;
} // 尽快退出临界区
taskEXIT_CRITICAL();
// 替代方案:使用队列或信号量进行异步通信
此外,合理配置中断优先级,确保RTOS内核中断(如SysTick)具有最高优先级,防止调度失准。
在现代嵌入式开发中,操作系统的选择直接决定了系统的性能边界、开发效率、维护成本以及长期可扩展性。随着物联网设备复杂度的不断提升,开发者面临一个核心决策问题:是选择轻量级实时操作系统(如FreeRTOS),还是采用功能更强大的嵌入式Linux?这一决策不仅涉及技术指标的权衡,还需综合考虑产品生命周期、硬件平台能力、团队技能结构和市场定位等多重因素。本章将深入剖析嵌入式Linux与FreeRTOS之间的本质差异,从启动时间、资源占用、实时性保障、文件系统支持到开发运维等多个维度展开系统性分析,并通过实际案例构建科学的选型模型,帮助工程师在不同应用场景下做出最优决策。
嵌入式操作系统的选型并非简单地“好”或“坏”的判断,而是一个基于具体应用需求的技术匹配过程。不同的项目对处理能力、响应延迟、存储容量、网络协议栈、用户界面复杂度等方面的要求各不相同,因此必须建立一套多维评估体系来指导选型工作。以下从三个关键技术维度出发——应用复杂度与负载能力、启动时间要求、文件系统支持——逐一解析其对操作系统选择的影响机制。
4.1.1 应用复杂度与操作系统负载能力匹配原则
应用复杂度是决定是否使用嵌入式Linux的关键前置条件。对于仅需完成数据采集、定时控制、串口通信等基础任务的小型终端设备(如温湿度传感器节点、智能门锁模块),FreeRTOS这类轻量级RTOS足以胜任;而对于需要运行Web服务器、图形界面(GUI)、数据库、AI推理引擎或多路视频流处理的应用(如工业HMI、智能家居网关、车载信息娱乐系统),则必须依赖嵌入式Linux提供的完整进程管理、虚拟内存机制和丰富的用户空间工具链。
为量化这种差异,可以引入 任务复杂度指数(TCI, Task Complexity Index) 模型进行初步评估:
例如,在设计一款支持OTA升级、远程监控和本地UI显示的智能电表时,若包含HTTP服务、SQLite数据库记录历史用电数据、LCD屏幕刷新界面,则其TCI评分可达8分以上,此时应优先考虑嵌入式Linux方案。
此外,还需关注 CPU负载能力与调度开销 之间的关系。FreeRTOS采用协作式或抢占式调度,任务切换开销通常小于2μs,适合硬实时场景;而Linux虽然具备CFS(Completely Fair Scheduler)调度器,但上下文切换时间较长(约10–50μs),且存在不可预测的内核抢占延迟,难以满足严格的时间约束。
// 示例:FreeRTOS中创建两个高优先级任务用于实时控制
void vControlTask(void *pvParameters) {
TickType_t xLastWakeTime;
const TickType_t xFrequency = pdMS_TO_TICKS(10); // 每10ms执行一次
xLastWakeTime = xTaskGetTickCount();
for (;;) {
// 实时控制逻辑:PID计算、PWM输出更新
UpdateMotorControl();
// 使用vTaskDelayUntil实现精确周期控制
vTaskDelayUntil(&xLastWakeTime, xFrequency);
}
}
// 创建任务示例
xTaskCreate(vControlTask, "Control", configMINIMAL_STACK_SIZE, NULL, tskIDLE_PRIORITY + 3, NULL);
代码逻辑逐行解读:
– 第1–2行:定义任务函数及其局部变量xLastWakeTime用于记录上次唤醒时间。
– 第3行:设置任务执行频率为每10毫秒一次,转换为滴答数(Tick)。
– 第5行:初始化当前时间为首次唤醒基准。
– 第7–13行:无限循环中执行控制逻辑后调用vTaskDelayUntil,确保任务以固定周期运行,避免累积误差。
– 第16行:使用xTaskCreate创建任务,指定名称、堆栈大小、参数、优先级和任务句柄。
该代码体现了FreeRTOS在实时控制中的优势:确定性的调度行为、低延迟的任务响应和高效的资源利用。相比之下,Linux环境下即使启用PREEMPT_RT补丁,也难以保证如此严格的周期性执行精度。
4.1.2 启动时间要求对Bootloader与OS启动流程的影响
启动时间是另一个影响深远的技术指标,尤其在医疗设备、工业自动化和汽车电子等领域,系统冷启动至进入正常工作状态的时间往往被严格限定(如<1秒)。FreeRTOS因其极简内核结构和无需外部存储加载的特性,通常可在数十毫秒内完成初始化并进入主循环;而嵌入式Linux由于需经历多个阶段(BootROM → SPL/U-Boot → Kernel decompression → RootFS mount → Init process),总启动时间可能长达数秒。
下面以典型启动流程为例进行对比分析:
graph TD
A[上电复位] --> B{选择OS}
B --> C[FreeRTOS路径]
B --> D[Linux路径]
C --> C1[执行Reset_Handler]
C1 --> C2[初始化堆栈、中断向量表]
C2 --> C3[调用main()]
C3 --> C4[启动Scheduler]
C4 --> C5[进入第一个任务]
D --> D1[BootROM加载SPL]
D1 --> D2[SPL初始化DDR]
D2 --> D3[U-Boot加载Kernel镜像]
D3 --> D4[解压zImage/Image]
D4 --> D5[启动内核,解析Device Tree]
D5 --> D6[挂载RootFS]
D6 --> D7[运行/sbin/init]
D7 --> D8[启动systemd或自定义服务]
流程图说明:
– FreeRTOS路径简洁明了,几乎无中间引导层,适合追求极速启动的场景。
– Linux路径层级复杂,每一阶段都可能成为瓶颈,尤其是U-Boot阶段的MMC读取速度、内核解压耗时及根文件系统挂载方式(NFS vs JFFS2 vs SPI-NOR Flash)均显著影响整体表现。
为了优化Linux启动时间,常见策略包括:
– 使用XIP(eXecute In Place)技术跳过Flash拷贝;
– 缩减内核配置,移除不必要的驱动和服务;
– 采用initramfs替代传统rootfs减少挂载延迟;
– 启用kexec快速重启机制。
然而这些优化仍无法使Linux达到FreeRTOS级别的启动性能。因此,当项目明确要求“上电即用”时,FreeRTOS仍是首选。
4.1.3 文件系统支持需求:ext4、JFFS2与LittleFS选型依据
文件系统的存在与否及其类型选择,也是区分FreeRTOS与嵌入式Linux的重要标志。FreeRTOS本身不内置完整的文件系统支持,但可通过第三方组件(如FatFs)实现FAT格式的SD卡访问;而Linux原生支持多种日志型、闪存友好型文件系统,适用于大容量存储管理和持久化数据保存。
举例说明:某环境监测终端需每小时记录一次GPS坐标和空气质量数据,预计每天生成约1MB数据,存储周期为一年。若使用SPI Flash(仅4MB),推荐采用LittleFS以确保断电安全性和寿命延长;若使用eMMC(8GB以上),则可选用ext4配合定期备份策略,充分发挥其高性能优势。
// FatFs在FreeRTOS中的典型使用片段
FATFS fs; // 文件系统对象
FIL file; // 文件对象
FRESULT fr;
fr = f_mount(&fs, "", 1); // 挂载SD卡
if (fr == FR_OK)
f_unmount("");
}
参数说明与逻辑分析:
–f_mount():挂载逻辑卷,第三个参数1表示立即挂载而非延迟。
–f_open():打开文件,FA_OPEN_APPEND确保追加写入,防止覆盖旧日志。
–f_write():异步写入缓冲区数据,&bw返回实际写入字节数,可用于错误检测。
– 整个操作在FreeRTOS任务中同步执行,适用于低频次、小数据量的日志记录。
综上所述,若应用涉及大量文件操作、目录结构管理或需支持POSIX标准API,则嵌入式Linux更具优势;反之,若仅需简单的配置保存或日志记录,FreeRTOS配合FatFs或LittleFS即可满足需求。
FreeRTOS作为全球最广泛使用的开源实时操作系统之一,凭借其小巧体积(最小可裁剪至几KB ROM/RAM)、高度可移植性和出色的实时性能,成为资源受限嵌入式系统的理想选择。然而,任何技术都有其适用边界,FreeRTOS也不例外。理解其核心优势的同时,也必须正视其在安全性、稳定性和扩展性方面的潜在缺陷。
4.2.1 适用于传感器节点与低功耗终端设备的典型场景
在电池供电的无线传感网络(WSN)、NB-IoT模组、可穿戴设备等低功耗场景中,FreeRTOS展现出无可比拟的优势。它允许开发者精细控制每个任务的运行时机,结合芯片的睡眠模式(Sleep/Deep Sleep)实现微安级待机电流。
例如,在一个基于STM32L4 + LoRa模块的土壤湿度监测节点中,系统设计如下:
void vSensorTask(void *pvParameters) {
for (;;) {
// 1. 唤醒传感器
EnableMoistureSensor();
vTaskDelay(pdMS_TO_TICKS(50));
// 2. 读取ADC值
uint16_t raw = Read_ADC_Channel(CHANNEL_1);
// 3. 发送LoRa数据包
Send_LoRa_Packet(raw);
// 4. 进入深度睡眠,持续2分钟
Enter_DeepSleep_Mode();
// MCU在此处暂停,由RTC闹钟唤醒
}
}
执行逻辑说明:
– 任务周期性运行,每次激活后迅速完成采样与传输,随后主动进入低功耗模式。
– FreeRTOS调度器在睡眠期间停止运行,所有任务挂起,仅保留中断服务例程监听唤醒源。
– 使用RTC定时器作为唤醒源,实现精准休眠周期控制。
此类设计充分利用了FreeRTOS“按需运行”的特点,极大降低了平均功耗,使得设备可持续工作数年无需更换电池。
4.2.2 缺乏内存保护机制带来的稳定性风险应对
FreeRTOS最大的结构性缺陷在于 缺乏MMU(内存管理单元)支持 ,导致所有任务共享同一地址空间,一旦某个任务发生指针越界或野指针访问,极易引发整个系统崩溃。这在安全关键领域(如医疗、航空)中构成严重隐患。
为缓解此问题,可采取以下措施:
configCHECK_FOR_STACK_OVERFLOW=1/2 特别是MPU的引入,可以在不改变FreeRTOS内核的前提下实现一定程度的内存隔离。例如,在STM32H7系列MCU上配置MPU规则,将 .text 段设为只读,外设寄存器区域禁止用户访问,从而防止非法修改代码或误写控制寄存器。
// MPU配置示例(基于CMSIS)
void Setup_MPU(void) {
MPU_Region_InitTypeDef MPU_InitStruct;
HAL_MPU_Disable(); // 先关闭MPU
MPU_InitStruct.Enable = MPU_REGION_ENABLE;
MPU_InitStruct.BaseAddress = 0x08000000; // Flash基址
MPU_InitStruct.Size = MPU_REGION_SIZE_512KB;
MPU_InitStruct.AccessPermission = MPU_REGION_PRIV_RO; // 只读
MPU_InitStruct.IsBufferable = MPU_ACCESS_NOT_BUFFERABLE;
MPU_InitStruct.IsCacheable = MPU_ACCESS_CACHEABLE;
MPU_InitStruct.IsShareable = MPU_ACCESS_NOT_SHAREABLE;
MPU_InitStruct.Number = MPU_REGION_NUMBER0;
MPU_InitStruct.TypeExtField = MPU_TEX_LEVEL0;
MPU_InitStruct.SubRegionDisable = 0x00;
MPU_InitStruct.DisableExec = MPU_INSTRUCTION_ACCESS_ENABLE;
HAL_MPU_ConfigRegion(&MPU_InitStruct);
HAL_MPU_Enable(MPU_PRIVILEGED_DEFAULT);
}
参数详解:
–BaseAddress和Size定义受保护区域范围;
–AccessPermission控制访问权限(此处为特权模式只读);
–IsCacheable/Bufferable影响性能,合理设置可提升执行效率;
–DisableExec设为ENABLE表示允许执行指令,否则将阻止代码运行。
尽管如此,MPU仍无法提供Linux那样的完整进程隔离机制。因此,在高可靠性要求的系统中,建议结合静态代码分析、单元测试和运行时断言(assert)构建多层次防护体系。
相较于FreeRTOS的“微型内核”设计理念,嵌入式Linux采用了宏内核架构,集成了进程管理、内存管理、设备驱动、网络协议栈和文件系统等全套功能模块,形成了一个完整的类UNIX运行环境。其复杂性虽带来更高的学习曲线,但也赋予了前所未有的灵活性和生态优势。
4.3.1 U-Boot引导程序配置与设备树(Device Tree)作用解析
嵌入式Linux的启动始于U-Boot(Universal Boot Loader),它是连接硬件与内核之间的桥梁。U-Boot负责初始化DRAM、配置时钟、加载内核镜像和传递启动参数。
典型U-Boot配置片段如下:
setenv bootcmd 'mmc dev 0; mmc read ${kernel_addr_r} 0x800 0x2000; bootm ${kernel_addr_r}'
setenv bootargs 'console=ttyS0,115200 root=/dev/mmcblk0p2 rw rootwait'
saveenv
boot
命令解释:
–mmc dev 0:选择SD卡作为启动设备;
–mmc read:从SD卡偏移0x800扇区读取内核到内存地址${kernel_addr_r};
–bootm:启动内核映像;
–bootargs:传递给内核的参数,指定控制台、根文件系统位置等。
其中, 设备树(Device Tree) 是现代嵌入式Linux的核心机制之一,用于描述硬件拓扑结构,取代旧式的“内核内建板级信息”。设备树源文件(.dts)编译为二进制格式(.dtb)后由U-Boot加载并传给内核。
/dts-v1/;
/ {
model = "My IoT Gateway";
compatible = "mycompany,iot-gateway";
chosen {
stdout-path = "serial0:115200n8";
};
memory@80000000 {
device_type = "memory";
reg = <0x80000000 0x40000000>; /* 1GB RAM */
};
soc {
serial0: serial@48020000 {
compatible = "ti,omap3-uart";
reg = <0x48020000 0x100>;
interrupts = <70>;
status = "okay";
};
};
};
结构说明:
–model和compatible用于匹配机器驱动;
–chosen指定默认控制台输出;
–memory节点声明物理内存布局;
–soc子系统中定义UART控制器,供内核自动绑定驱动。
设备树机制实现了“一次编译,多平台部署”的灵活性,极大提升了内核的可重用性。
4.3.2 根文件系统构建方式:BusyBox与Buildroot实践
根文件系统(RootFS)是Linux用户空间的基础,包含基本命令、库文件和启动脚本。常用构建方法有两种:
BusyBox被称为“嵌入式Linux的瑞士军刀”,它将上百个Unix工具(如ls、cp、sh、ifconfig)集成在一个可执行文件中,极大节省空间。
# .config 配置片段(BusyBox)
CONFIG_SH=y
CONFIG_LS=y
CONFIG_CP=y
CONFIG_IFCONFIG=y
CONFIG_TFTP=y
CONFIG_HTTPD=n
CONFIG_FEATURE_WGET_LONG_OPTIONS=y
通过交叉编译生成静态链接的 busybox 二进制文件后,配合 /dev , /proc , /sys 等虚拟文件系统挂载点,即可组成最小可行RootFS。
Buildroot则进一步封装了交叉编译链、内核、U-Boot和RootFS的一体化构建流程:
make menuconfig
# Target options → Target Architecture → ARM (little endian)
# Toolchain → External toolchain
# System configuration → Root password
# Target packages → BusyBox, Dropbear SSH server
make
最终输出包含 u-boot.bin , zImage , rootfs.tar 等完整烧录镜像,极大简化了量产准备流程。
4.3.3 Yocto Project定制化发行版构建流程简介
对于需要高度定制的企业级产品,Yocto Project提供了更为强大的解决方案。它基于BitBake构建引擎,使用Layer机制组织代码,支持精细化版本控制和许可证合规检查。
典型Yocto构建流程如下:
source oe-init-build-env
bitbake-layers add-layer meta-myproduct
echo 'MACHINE="myboard"' >> conf/local.conf
bitbake core-image-minimal
生成的镜像不仅包含操作系统,还可集成专属应用、加密模块和安全启动机制,适用于金融终端、工业控制器等高端设备。
4.4.1 基于功耗、成本、开发周期与维护性的多因素评分法
为实现客观选型,可构建如下评分模型:
加权计算得:
– FreeRTOS总分 ≈ 7.8
– 嵌入式Linux总分 ≈ 6.7
可见,在通用场景下FreeRTOS更具优势;但在强调安全性、生态和长期维护的项目中,Linux反超。
4.4.2 医疗设备与智能家居产品中的选型案例对比
案例一:便携式血糖仪(医疗设备)
– 要求:高可靠性、快速启动、低功耗、FDA认证
– 选择:FreeRTOS + MPU保护 + 静态分配
– 理由:避免复杂依赖,降低故障概率
案例二:智能音箱(智能家居)
– 要求:语音识别、Wi-Fi/BT连接、OTA升级、云同步
– 选择:嵌入式Linux(ASoC音频框架 + BlueZ + systemd)
– 理由:丰富中间件支持,便于集成第三方SDK
结论:没有绝对优劣,唯有适配场景的最佳平衡。
嵌入式系统开发离不开高效、可靠的工具链支持。从代码编写到最终烧录运行,整个流程依赖于编译器、链接器、调试器以及集成开发环境(IDE)的协同工作。主流嵌入式开发工具链主要包括开源阵营的 GCC + GDB 组合,以及商业级解决方案如 Keil MDK 和 IAR Embedded Workbench。这些工具在性能优化、调试能力、目标架构支持和易用性方面各有侧重,理解其底层机制与实际操作方法,是构建高质量嵌入式软件系统的前提。
本章将深入剖析各类工具链的核心组成与工作机制,重点讲解交叉编译环境搭建、Makefile 自动化构建设计、链接脚本内存布局规划,并结合 STM32 等典型 MCU 平台演示 GDB 配合 OpenOCD 实现远程调试的完整流程。同时,针对 Keil RTX5 内核实例的调试技巧和 IAR 编译优化等级的影响分析也将展开详细说明。最后通过对比不同编译选项对代码体积与执行效率的实际影响,探讨如何利用静态分析工具提升代码质量与系统稳定性。
现代嵌入式开发中,开发者通常在一个高性能主机(如 x86 架构 PC)上进行程序编写和编译,然后将生成的目标代码下载到资源受限的嵌入式设备(如 ARM Cortex-M 微控制器)上运行。这种“在一种平台上编译,在另一种平台上执行”的模式称为 交叉编译 (Cross Compilation)。实现这一过程的关键在于构建一个稳定、可复用的交叉编译环境,并深刻理解编译器的工作流程。
5.1.1 GCC编译流程四阶段:预处理、编译、汇编与链接详解
GNU Compiler Collection(GCC)是目前最广泛使用的开源编译器集合之一,尤其在嵌入式 Linux 和裸机开发中占据主导地位。对于 C/C++ 源码,GCC 的编译过程分为四个清晰的阶段:预处理、编译、汇编和链接。掌握这四个阶段不仅有助于排查编译错误,还能为后续的性能调优提供基础支持。
预处理(Preprocessing)
预处理器负责处理源文件中的 #include 、 #define 、 #ifdef 等宏指令,输出一个经过展开后的纯 C 代码文件(通常以 .i 为扩展名)。该阶段不涉及语法检查,仅做文本替换。
arm-none-eabi-gcc -E main.c -o main.i
- 参数说明 :
-
arm-none-eabi-gcc:针对 ARM 架构的交叉编译器前缀。 -
-E:仅执行预处理阶段。 -
main.c:输入源文件。 -
-o main.i:指定输出文件名为main.i。
逻辑分析 :此命令可用于查看头文件包含路径是否正确,或验证宏定义是否按预期展开。例如,若某个条件编译块未生效,可通过观察
.i文件确认宏是否被正确定义。
编译(Compilation)
编译阶段将预处理后的 .i 文件转换为特定架构的汇编语言代码( .s 文件),这是真正意义上的“翻译”过程,包括词法分析、语法分析、语义分析、中间表示生成及目标汇编代码生成。
arm-none-eabi-gcc -S main.i -o main.s
- 参数说明 :
-
-S:停止在编译阶段,输出汇编代码。 - 输出文件
main.s包含 ARM Thumb-2 指令集代码(适用于 Cortex-M 系列)。
逻辑分析 :通过阅读
.s文件可以判断编译器是否进行了有效的寄存器分配和函数内联优化。例如,频繁访问的变量可能被分配至 R0-R3 寄存器以提高访问速度。
汇编(Assembly)
汇编器将 .s 文件转换为机器码形式的目标文件( .o ),每个 .o 文件对应一个编译单元,包含符号表、重定位信息和二进制指令。
arm-none-eabi-as main.s -o main.o
或者更常用的是直接由 GCC 调用:
arm-none-eabi-gcc -c main.c -o main.o
- 参数说明 :
-
-c:只编译和汇编,不进行链接。 - 输出为可重定位目标文件,尚未解析外部引用。
逻辑分析 :多个
.o文件可以在链接阶段合并成一个可执行映像。此时各模块之间的函数调用仍为符号引用,需由链接器完成地址绑定。
链接(Linking)
链接器(ld)将多个 .o 文件以及标准库或启动文件组合成单一的可执行二进制文件(如 .elf 或 .bin ),并根据链接脚本安排代码和数据在内存中的布局。
arm-none-eabi-gcc main.o startup_stm32f407xx.o -T stm32_flash.ld -o firmware.elf
- 参数说明 :
-
-T stm32_flash.ld:指定链接脚本,定义内存区域(FLASH、RAM)、入口点_start、堆栈段等。 - 输出
firmware.elf是 ELF 格式的可执行文件,可用 GDB 调试。
逻辑分析 :链接阶段决定了程序在 Flash 和 RAM 中的具体分布。若未正确配置
.data段的加载地址与运行地址,可能导致初始化失败。
以下是 GCC 四阶段流程的 Mermaid 流程图展示:
graph TD
A[main.c] --> B{预处理}
B --> C[main.i]
C --> D{编译}
D --> E[main.s]
E --> F{汇编}
F --> G[main.o]
G --> H{链接}
H --> I[firmware.elf]
J[startup.o] --> H
K[lib.a] --> H
该流程图清晰地展示了从源码到可执行文件的转化路径,强调了各个阶段的输入输出关系。
5.1.2 Makefile编写规范与自动化构建脚本设计
随着项目规模扩大,手动执行上述每条命令变得不可行。因此,使用 Makefile 实现自动化构建成为必要技能。Make 是一款基于依赖关系的构建工具,能够智能判断哪些文件需要重新编译,极大提升开发效率。
下面是一个典型的嵌入式项目 Makefile 示例:
# 工具链定义
CC = arm-none-eabi-gcc
AS = arm-none-eabi-as
LD = arm-none-eabi-gcc
OBJCOPY = arm-none-eabi-objcopy
# 源文件与对象文件
SOURCES = main.c system_stm32f4xx.c startup_stm32f407xx.s
OBJECTS = $(SOURCES:.c=.o)
OBJECTS := $(OBJECTS:.s=.o)
# 编译选项
CFLAGS = -mcpu=cortex-m4 -mthumb -O2 -Wall -Tstm32_flash.ld
LDFLAGS = -nostartfiles -Wl,-Map=firmware.map
# 目标文件
TARGET = firmware.elf
# 默认目标
all: $(TARGET)
# 链接生成 ELF
$(TARGET): $(OBJECTS)
$(LD) $(LDFLAGS) $^ -o $@
$(OBJCOPY) -O binary $@ firmware.bin
# 编译 C 文件
%.o: %.c
$(CC) $(CFLAGS) -c $< -o $@
# 汇编 S 文件
%.o: %.s
$(AS) -o $@ $<
# 清理构建产物
clean:
rm -f $(OBJECTS) $(TARGET) firmware.bin firmware.map
.PHONY: all clean
参数与逻辑逐行解读:
arm-none-eabi- 前缀确保调用的是交叉编译工具 .c 和 .s 文件统一转为 .o 对象文件 -mcpu 指定目标 CPU; -O2 启用优化; -T 加载链接脚本 $^ 表示所有依赖项, $@ 表示目标名 %.o: %.c 实现通配符编译,自动处理所有 C 文件 扩展说明 :该 Makefile 支持增量编译——当仅修改
main.c时,只有main.o被重新生成,其余不变。此外,生成的firmware.map文件可用于分析符号地址、段大小及堆栈使用情况。
5.1.3 链接脚本(Linker Script)中内存布局规划技巧
链接脚本(通常以 .ld 结尾)是控制程序在物理内存中分布的核心配置文件。它定义了 Flash、RAM 区域的位置与大小,并指定代码段( .text )、只读数据段( .rodata )、已初始化数据段( .data )和未初始化数据段( .bss )的存放位置。
以下是一个适用于 STM32F407VG(Flash: 1MB, RAM: 128KB)的简化链接脚本示例:
MEMORY
{
FLASH (rx) : ORIGIN = 0x08000000, LENGTH = 1M
RAM (rwx) : ORIGIN = 0x20000000, LENGTH = 128K
}
SECTIONS
{
.text :
{
KEEP(*(.isr_vector)) /* 中断向量表必须位于起始位置 */
*(.text)
*(.rodata)
} > FLASH
.ARM.exidx : { *(.ARM.exidx) } > FLASH
.data :
{
PROVIDE(__data_start__ = .);
*(.data)
PROVIDE(__data_end__ = .);
} > RAM AT > FLASH
.bss :
{
PROVIDE(__bss_start__ = .);
*(.bss)
*(COMMON)
PROVIDE(__bss_end__ = .);
} > RAM
}
关键参数与结构解析:
MEMORY 块 (rx) / (rwx) ORIGIN 和 LENGTH > FLASH .text 存放程序代码 AT > FLASH .data 初始化值从 Flash 复制到 RAM PROVIDE() __bss_start__ 可用于清零 .bss 段 初始化逻辑补充 :在启动代码(如
startup_stm32f4xx.s)中,通常会插入一段汇编逻辑,将.data段从 Flash 复制到 RAM,并将.bss段清零。该过程依赖链接脚本提供的符号地址。
下表总结常见段的作用与属性:
.text .rodata .data .bss .stack 合理规划内存布局不仅能避免溢出问题,还可为多核系统或安全固件预留专用区域(如 TrustZone)。例如,在双 bank Flash 设备中,可通过修改链接脚本实现 A/B 安全更新机制。
在嵌入式系统开发过程中,系统集成是连接软硬件模块、实现端到端功能的关键阶段。该阶段的核心目标是确保各个独立开发的组件——包括底层驱动、中间件、RTOS/Linux内核、应用逻辑和外设接口——能够协同工作并满足原始设计需求。
6.1.1 硬件驱动与上层应用接口联调流程
系统集成的第一步通常是完成硬件抽象层(HAL)或板级支持包(BSP)中的设备驱动与上层应用程序之间的通信验证。以STM32平台为例,假设系统包含一个温湿度传感器(如SHT30),其通过I²C总线连接至MCU。
典型联调步骤如下:
- 确认引脚配置与时钟使能
在初始化代码中启用I²C外设时钟,并将对应GPIO设置为复用开漏模式。 - 编写低层I²C读写函数
HAL_StatusTypeDef i2c_write(uint8_t dev_addr, uint8_t reg, uint8_t data) {
return HAL_I2C_Mem_Write(&hi2c1, dev_addr << 1, reg, I2C_MEMADD_SIZE_8BIT,
&data, 1, HAL_MAX_DELAY);
}
HAL_StatusTypeDef i2c_read(uint8_t dev_addr, uint8_t reg, uint8_t *buf, uint8_t len) {
return HAL_I2C_Mem_Read(&hi2c1, dev_addr << 1, reg, I2C_MEMADD_SIZE_8BIT,
buf, len, HAL_MAX_DELAY);
}
注:
hi2c1为HAL库定义的I²C句柄;左移<<1符合多数传感器对7位地址的协议要求。
- 构建传感器驱动API层
float sht30_read_temperature() {
uint8_t cmd[2] = {0x2C, 0x06}; // 高重复性测量命令
uint8_t raw_data[6];
i2c_write(SHT30_ADDR, cmd[0], cmd[1]); // 发送命令
HAL_Delay(50); // 等待转换完成
i2c_read(SHT30_ADDR, 0x00, raw_data, 6); // 读取6字节数据
uint16_t st = (raw_data[0] << 8) | raw_data[1];
return -45 + 175 * ((float)st / 65535.0); // 转换为摄氏度
}
- 在应用任务中调用并打印结果
void TempTask(void *pvParameters) {
float temp;
for(;;) {
temp = sht30_read_temperature();
printf("Temperature: %.2f°C
", temp);
vTaskDelay(pdMS_TO_TICKS(1000));
}
}
此过程需配合串口调试助手观察输出,结合逻辑分析仪抓取I²C波形进行协议一致性校验。
功能测试旨在验证系统是否实现了规格书中规定的所有行为。
6.2.1 基于需求规格说明书的测试用例覆盖方法
采用“需求追溯矩阵”(Requirement Traceability Matrix, RTM)可确保每个需求都有对应的测试用例。
6.2.2 自动化测试框架搭建:Python+串口通信实现回归测试
利用Python的 pyserial 和 unittest 模块构建自动化测试脚本,可大幅提升长期维护效率。
import serial
import unittest
import time
class TestEmbeddedSystem(unittest.TestCase):
def setUp(self):
self.ser = serial.Serial('COM7', 115200, timeout=2)
time.sleep(2) # 等待系统重启完成
def tearDown(self):
self.ser.close()
def test_temperature_response(self):
self.ser.write(b"GET_TEMP
")
line = self.ser.readline().decode().strip()
self.assertIn("Temp:", line)
temp_val = float(line.split(":")[1].strip().replace("°C", ""))
self.assertGreater(temp_val, -40)
self.assertLess(temp_val, 85)
def test_uart_echo(self):
self.ser.write(b"HELLO
")
response = self.ser.readline().decode().strip()
self.assertEqual(response, "ECHO: HELLO")
if __name__ == '__main__':
unittest.main()
上述脚本可通过CI/CD流水线每日自动运行,生成HTML报告并发送邮件通知。配合 matplotlib 还可绘制历史数据趋势图,用于识别性能退化。
graph TD
A[启动测试脚本] --> B{串口连接成功?}
B -- 是 --> C[发送测试指令]
B -- 否 --> D[记录失败并退出]
C --> E[接收响应数据]
E --> F{格式正确且数值合理?}
F -- 是 --> G[标记通过]
F -- 否 --> H[截图日志并报警]
G --> I[生成测试报告]
H --> I
I --> J[上传至服务器归档]
6.3.1 CPU占用率、内存泄漏监测与长期运行压力测试
使用FreeRTOS自带的 uxTaskGetStackHighWaterMark() 函数监控各任务栈使用情况:
void MonitorTask(void *pvParameters)
vTaskDelay(xDelay);
}
}
同时,在主循环中定期调用内存统计函数(适用于启用heap_4或heap_5的FreeRTOS配置):
size_t free_heap = xPortGetFreeHeapSize();
size_t min_free = xPortGetMinimumEverFreeHeapSize();
printf("Free Heap: %zu bytes, Min Ever: %zu bytes
", free_heap, min_free);
部署连续运行72小时的压力测试,记录以下指标变化:
未发现内存持续下降趋势,表明无显著泄漏。
6.3.2 温升测试与电磁兼容性(EMC)初步评估
在密闭外壳中运行满负荷负载程序(如持续PWM输出+高频ADC采样),使用红外热像仪监测PCB热点分布:
// 模拟高负载场景
void HeavyLoadTask(void *pvParameters) {
while(1) {
for(int i=0; i<1000; i++) {
TIM3->CCR1 = rand() % 100; // 随机改变占空比
adc_value = ADC1->DR; // 触发软件注入
}
taskYIELD(); // 主动让出CPU
}
}
建议阈值:
– 芯片表面温度 ≤ 85°C(工业级标准)
– PCB局部温升 ≤ 40K(相对于环境温度)
EMC初步测试包括:
– 使用近场探头扫描电源走线与晶振区域
– 在开机瞬间测量电源纹波(应 < 5% VDD)
– 将示波器耦合至模拟输入通道,检测是否存在高频干扰耦合
6.3.3 故障注入测试提升系统鲁棒性设计水平
主动引入异常条件以检验系统的容错能力:
此类测试有助于完善“故障—恢复—记录”闭环机制,提高产品在现场复杂环境下的可用性。
本文还有配套的精品资源,点击获取
简介:嵌入式系统设计师是面向嵌入式技术人才的国家级专业认证,属于全国计算机技术与软件专业技术资格(水平)考试(软考)的重要方向之一。该认证涵盖嵌入式系统基础、微控制器原理、实时操作系统、开发工具链、硬件设计、软件开发、系统集成与测试、实时性与可靠性设计、电源管理、网络通信及安全隐私等核心知识点。通过本指南系统学习,考生可全面掌握嵌入式系统设计的关键技术与工程实践能力,有效应对软考理论与实操要求,提升在物联网、智能设备、工业控制等领域的综合竞争力。
本文还有配套的精品资源,点击获取













