目录
1、先搞懂核心问题:什么是机器翻译?
(一)人类 vs 机器翻译的区别(超形象对比)
2、机器翻译的完整处理流程(像开 “AI 翻译公司”)
2.1、Step1:准备 “翻译教材”(数据预处理)
2.1.1、基础整理
2.1.2、精细整理
2.2、Step2:选 “翻译老师”(模型架构)
2.2.1、Transformer 核心公式(通俗解释)
2.2.2、人话翻译:
2.3、Step3:教 “AI 员工” 学翻译(模型训练)
2.3.1、训练逻辑:
2.3.2、预训练 + 微调(进阶技巧)
2.4、Step4:检查翻译质量(BLEU 评估)
2.4.1、BLEU 核心公式(通俗拆解)
2.4.2、人话翻译:
2.5、Step5:输出可用结果(去词元化 + 整理)
3、机器翻译的 “行业应用”(为啥要学它?)
4、机器翻译的 “痛点与未来”(学完心里有数)
4.1、当前痛点(别被 “完美翻译” 骗了)
4.2、未来趋势(学它不亏)
5、预处理数据集
5.1、理论逻辑
5.1.1、基础清洗 —— 解决 “数据标准化” 问题
5.1.2、词汇表优化 —— 解决 “模型复杂度” 问题
5.1.3、两部分的协同作用:从 “能用” 到 “好用”
5.2、实验代码
5.2.1、基础清洗
5.2.2、词汇表优化
6、采用BLU评估机器翻译
6.1、理论逻辑
6.1.1、平滑技术:避免 “一棍子打死”
6.1.2、几何评估:算分要 “顾全大局”
6.1.3、两者结合:既公平又合理
6.2、实验代码
想搞懂机器翻译到底咋回事?别慌,咱们把它拆成 “人话”,从概念到流程,再到公式,一步一步唠明白!
简单说:机器翻译就是让 AI 模仿人类,把一种语言(比如中文)转换成另一种语言(比如英文)的技术。 但 AI 没人的思维,它靠 “数学公式 + 海量数据” 实现 —— 就像教小孩学翻译,但小孩是 “死记硬背找规律” 的机器人。
机器翻译的核心流程,其实是 “数据→模型→结果” 的闭环,咱们拆解成 5 步:
就像教小孩学英语,得先准备 “中英对照句子库”(专业说法:平行语料)。但原始数据很 “脏”,得整理:
2.1.1、基础整理
- 删重复:把 “你好 = Hello”“你好呀 = Hello” 里重复的 “你好” 合并
- 统一格式:把 “吃了吗?=Have you eaten?” 的标点、大小写统一 → 让 AI 学的资料更 “干净整齐”
2.1.2、精细整理
- 拆长句:把 “今天阳光好,适合出去玩 = Today’s sunny, good for outdoor” 拆成短句
- 处理生僻词:遇到 “螺蛳粉 = Luosifen” 这种新词,标记出来专门学 → 让 AI 学的资料更 “精准好用”
AI 翻译的 “大脑” 是模型(比如 Transformer、RNN),最常用的是 Transformer(因为又快又准)。
2.2.1、Transformer 核心公式(通俗解释)
Transformer 靠 “注意力机制(Attention)” 让 AI 学翻译,核心逻辑像 “人类翻译时的‘聚焦重点’”:
公式简化版:
2.2.2、人话翻译:
简单说:Transformer 让 AI 翻译时,像人类一样 “聚焦重点词”,避免逐字硬翻出错。
- Q(Query):AI 想 “查的词”(比如翻译 “火锅” 时,Q 是 “火锅”)
- K(Key):数据里的 “关键词库”(比如所有中文词对应的英文)
- V(Value):关键词的 “翻译结果”(比如 “火锅” 对应 “hotpot”)
- 整体逻辑:AI 查 “Q 对应的 K”,然后输出 “V 的结果”→ 本质是 “精准查字典”
有了 “教材(数据)” 和 “老师(模型)”,下一步是训练模型—— 让 AI 从数据里 “找翻译规律”。
2.3.1、训练逻辑:
- 把整理好的 “中英对照数据” 喂给模型
- 模型用 “注意力公式” 反复计算,调整内部参数(比如 “火锅” 对应 “hotpot” 的权重)
- 训练到 “输出结果和人类翻译越来越像” 为止
2.3.2、预训练 + 微调(进阶技巧)
- 预训练:先喂给模型 “海量通用文本”(比如维基百科),让它先学 “通用语言规律”(像小孩先学日常对话)
- 微调:再喂 “翻译专用数据”,让模型专注学 “翻译规律”(像小孩学 “专业翻译技巧”)
翻译完总得知道好不好吧?BLEU(Bilingual Evaluation Understudy) 是机器翻译的 “阅卷老师”,核心逻辑是 “对比 AI 翻译和人类翻译的‘重合度’”。
2.4.1、BLEU 核心公式(通俗拆解)
BLEU 的核心是 “N-gram 匹配度”,公式简化版:
2.4.2、人话翻译:
- (n-gram 匹配率):对比 AI 翻译和人类翻译的 “单词片段重合度”。比如 “今天吃火锅”,AI 翻译 “Today eat hotpot”,人类翻译 “Today had hotpot”→ “Today”“hotpot” 匹配(n=1 或 n=2 的片段)。
- (权重):给不同长度的片段分配 “重要性分数”(比如短片段权重低,长片段权重大)。
- BP( brevity penalty,简短惩罚):如果 AI 翻译比人类翻译短太多,会扣分项(避免 “偷工减料”)。
简单说:BLEU 是 “看 AI 翻译和人类翻译的‘单词片段重合度’,越重合分越高,但太短会扣分”。
AI 模型输出的翻译是 “词元(Token)”(机器能懂的编码),得转成人类能懂的文字:
- 去词元化:把 “Today_eat_hotpot” 转成 “Today eat hotpot”
- 整理格式:加标点、换行,让翻译更像 “人话”
机器翻译不是 “玩具”,而是生产力工具,典型应用:
- 日常翻译:Google 翻译、DeepL 等 App,靠机器翻译实现 “实时跨语言交流”
- 专业领域:法律、医疗翻译(比如合同、病历翻译),靠 “定制模型 + 领域数据” 实现精准翻译
- 内容出海:短视频、网文批量翻译成外语,靠机器翻译 “降本增效”
- 语境理解差:比如 “意思” 的多义(“你什么意思?” vs “这意思不错”),机器容易翻错
- 生僻词 / 文化词翻车:翻译 “相声”“过年”,机器可能直接音译,不懂背后的文化
- 逻辑复杂句难搞:“虽然他没来,但大家都知道他懂这个意思”,长句逻辑容易乱
- 多模态翻译:结合图片、语音理解语境(比如看图片是 “火锅”,翻译更准)
- 小模型 + 大效果:用更少数据、更低成本,实现更准翻译(适合普通人玩)
- 人机协同:机器翻译初稿,人类润色收尾(像 “AI 写作文,人类改语法”)
数据集:
5.1.1、基础清洗 —— 解决 “数据标准化” 问题
第一部分的核心是对原始文本进行格式统一和噪声过滤,确保数据的 “干净度”,为后续处理打下基础。具体包括:
- 去除冗余信息:如标点符号、特殊字符、非打印字符(比如控制字符)。
- 统一格式:将文本转为小写、规范化 Unicode 字符(比如法语的重音字符转为拉丁字符)。
- 过滤无效内容:如包含数字的单词(机器翻译更关注纯文本语义)。
为什么这一步是必需的?
原始数据集(如 Europarl 的会议记录)存在大量 “自然噪声”:比如大小写混用(“Hello” 和 “hello”)、标点符号不一致(“word.” 和 “word”)、特殊字符(如法语的 “锓à”)等。这些噪声会干扰模型对 “语义” 的学习(比如模型可能会误认为 “Hello” 和 “hello” 是两个不同的词)。基础清洗通过标准化处理,让文本格式统一,减少无效特征,确保模型聚焦于 “单词本身的含义”。
5.1.2、词汇表优化 —— 解决 “模型复杂度” 问题
第二部分的核心是控制词汇表规模,通过过滤低频词、标记未登录词(OOV),降低模型的学习难度。具体包括:
- 统计词频:计算每个单词在数据集中的出现次数。
- 过滤低频词:保留高频词(如出现≥5 次),移除低频词(如仅出现 1-2 次的生僻词)。
- 统一标记 OOV:用 “unk” 替换所有低频词,确保模型不会因词汇表过大而难以训练。
为什么这一步是必需的?
机器翻译模型的复杂度与词汇表大小直接相关:词汇表越大,模型需要学习的 “词向量”“映射关系” 就越多,训练时间越长、容易过拟合。而原始数据中存在大量低频词(比如特定人名、地名、生僻术语),这些词对整体语义的贡献极小,但会显著增加词汇表规模。
通过词汇表优化,既能保留核心词汇(高频词承载了大部分语义),又能通过 “unk” 统一处理低频词,在 “信息保留” 和 “模型效率” 之间找到平衡。
5.1.3、两部分的协同作用:从 “能用” 到 “好用”
- 基础清洗是前提:如果跳过基础清洗,文本中混杂的标点、特殊字符会导致词频统计错误(比如 “word” 和 “word.” 会被视为两个词),后续的词汇表优化也会失去意义。
- 词汇表优化是升华:如果只有基础清洗而不优化词汇表,模型会被海量低频词拖累,训练效率低且泛化能力差(低频词缺乏足够样本让模型学会其翻译规律)。
5.2.1、基础清洗
"""基础清晰"""
import pickle
from pickle import dump
# 将指定文件内容加载到内存中
def load_doc(filename):
# 以只读文本模式打开文件,并指定UTF-8编码
file = open(filename, mode='rt', encoding='utf-8')
# 读取文件全部内容
text = file.read()
# 关闭文件释放资源
file.close()
return text
# 将加载的文档按行拆分为句子列表
def to_sentences(doc):
# 去除首尾空白字符并按换行符分割文本
return doc.strip().split('
')
# 计算句子长度的最小值和最大值
def sentence_lengths(sentences):
# 对每个句子按空格分词并计算词数
lengths = [len(s.split()) for s in sentences]
return min(lengths), max(lengths)
# 文本清洗函数,处理每行文本
import re
import string
import unicodedata
def clean_lines(lines):
cleaned = list()
# 编译正则表达式,用于过滤非可打印字符
re_print = re.compile('[^%s]' % re.escape(string.printable))
# 创建翻译表,用于移除所有标点符号
table = str.maketrans('', '', string.punctuation)
for line in lines:
# 规范化Unicode字符,转换为标准形式
line = unicodedata.normalize('NFD', line).encode('ascii', 'ignore')
line = line.decode('UTF-8')
# 按空格分词
line = line.split()
# 转换为小写
line = [word.lower() for word in line]
# 移除每个词中的标点符号
line = [word.translate(table) for word in line]
# 过滤非可打印字符
line = [re_print.sub('', w) for w in line]
# 仅保留纯字母的词
line = [word for word in line if word.isalpha()]
# 重新组合为字符串并保存
cleaned.append(' '.join(line))
return cleaned
if __name__ == '__main__':
# 处理英文数据集
filename = 'E:/WH/llm_finetune/llm_finetune/NLP/Transformers-for-NLP-2nd-Edition-main/Chapter06/fr-en/europarl-v7.fr-en.en'
# 加载英文语料库文件
doc = load_doc(filename)
# 拆分为句子列表
sentences = to_sentences(doc)
# 统计句子长度范围
minlen, maxlen = sentence_lengths(sentences)
print('英文数据: 句子数=%d, 最小长度=%d, 最大长度=%d' % (len(sentences), minlen, maxlen))
# 清洗文本数据
cleanf = clean_lines(sentences)
# 保存处理后的英文数据为pickle文件
filename = 'E:/WH/llm_finetune/llm_finetune/NLP/Transformers-for-NLP-2nd-Edition-main/Chapter06/fr-en/English.pkl'
outfile = open(filename, 'wb')
pickle.dump(cleanf, outfile)
outfile.close()
print(filename, " 已保存")
# 处理法文数据集
filename = 'E:/WH/llm_finetune/llm_finetune/NLP/Transformers-for-NLP-2nd-Edition-main/Chapter06/fr-en/europarl-v7.fr-en.fr'
# 加载法文语料库文件
doc = load_doc(filename)
# 拆分为句子列表
sentences = to_sentences(doc)
# 统计句子长度范围
minlen, maxlen = sentence_lengths(sentences)
print('法文数据: 句子数=%d, 最小长度=%d, 最大长度=%d' % (len(sentences), minlen, maxlen))
# 清洗文本数据
cleanf = clean_lines(sentences)
# 保存处理后的法文数据为pickle文件
filename = 'E:/WH/llm_finetune/llm_finetune/NLP/Transformers-for-NLP-2nd-Edition-main/Chapter06/fr-en/French.pkl'
outfile = open(filename, 'wb')
pickle.dump(cleanf, outfile)
outfile.close()
print(filename, " 已保存")清洗后生成的文件
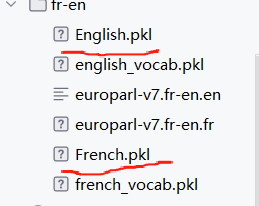
5.2.2、词汇表优化
# 机器翻译数据集预处理 - 词汇表构建与优化
from pickle import load
from pickle import dump
from collections import Counter
# 加载已处理好的干净数据集
def load_clean_sentences(filename):
return load(open(filename, 'rb'))
# 将处理后的句子列表保存到文件
def save_clean_sentences(sentences, filename):
dump(sentences, open(filename, 'wb'))
print('已保存: %s' % filename)
# 构建词汇表,统计所有单词的出现频率
def to_vocab(lines):
# 使用Counter对象统计词频
vocab = Counter()
for line in lines:
# 将句子分词并更新词频统计
tokens = line.split()
vocab.update(tokens)
return vocab
# 过滤低频词,保留出现次数大于等于min_occurance的单词
def trim_vocab(vocab, min_occurance):
# 筛选符合条件的单词,构建新词汇表
tokens = [k for k, c in vocab.items() if c >= min_occurance]
return set(tokens)
# 将词汇表外的词标记为"unk",统一处理未登录词
def update_dataset(lines, vocab):
new_lines = list()
for line in lines:
new_tokens = list()
for token in line.split():
# 检查单词是否在词汇表中
if token in vocab:
new_tokens.append(token)
else:
# 词汇表外的词标记为"unk"
new_tokens.append('unk')
# 重新组合处理后的句子
new_line = ' '.join(new_tokens)
new_lines.append(new_line)
return new_lines
if __name__ == '__main__':
# 处理英文数据集
filename = 'E:/WH/llm_finetune/llm_finetune/NLP/Transformers-for-NLP-2nd-Edition-main/Chapter06/fr-en/English.pkl'
# 加载之前处理好的英文句子
lines = load_clean_sentences(filename)
# 构建英文词汇表并统计词频
vocab = to_vocab(lines)
print('英文原始词汇表大小: %d' % len(vocab))
# 过滤低频词,保留至少出现5次的单词
vocab = trim_vocab(vocab, 5)
print('优化后的英文词汇表大小: %d' % len(vocab))
# 替换原始句子中的低频词为"unk"
lines = update_dataset(lines, vocab)
# 保存优化后的英文数据集
filename = 'E:/WH/llm_finetune/llm_finetune/NLP/Transformers-for-NLP-2nd-Edition-main/Chapter06/fr-en/english_vocab.pkl'
save_clean_sentences(lines, filename)
# 抽查前20个句子,验证处理效果
print("英文数据集抽查结果:")
for i in range(20):
print(f"第{i}行:", lines[i])
# 处理法文数据集
filename = 'E:/WH/llm_finetune/llm_finetune/NLP/Transformers-for-NLP-2nd-Edition-main/Chapter06/fr-en/French.pkl'
# 加载之前处理好的法文句子
lines = load_clean_sentences(filename)
# 构建法文词汇表并统计词频
vocab = to_vocab(lines)
print('法文原始词汇表大小: %d' % len(vocab))
# 过滤低频词,保留至少出现5次的单词
vocab = trim_vocab(vocab, 5)
print('优化后的法文词汇表大小: %d' % len(vocab))
# 替换原始句子中的低频词为"unk"
lines = update_dataset(lines, vocab)
# 保存优化后的法文数据集
filename = 'E:/WH/llm_finetune/llm_finetune/NLP/Transformers-for-NLP-2nd-Edition-main/Chapter06/fr-en/french_vocab.pkl'
save_clean_sentences(lines, filename)
# 抽查前20个句子,验证处理效果
print("法文数据集抽查结果:")
for i in range(20):
print(f"第{i}行:", lines[i])生成后的文件
E:WHanaconda3envsllm_finetunepython.exe E:WHllm_finetunellm_finetuneNLPTransformers-for-NLP-2nd-Edition-mainChapter06
ead_clean.py
英文原始词汇表大小: 105357
优化后的英文词汇表大小: 41746
已保存: E:/WH/llm_finetune/llm_finetune/NLP/Transformers-for-NLP-2nd-Edition-main/Chapter06/fr-en/english_vocab.pkl
英文数据集抽查结果:
第0行: resumption of the session
第1行: i declare resumed the session of the european parliament adjourned on friday december and i would like once again to wish you a happy new year in the hope that you enjoyed a pleasant festive period
第2行: although as you will have seen the dreaded millennium bug failed to materialise still the people in a number of countries suffered a series of natural disasters that truly were dreadful
第3行: you have requested a debate on this subject in the course of the next few days during this partsession
第4行: in the meantime i should like to observe a minute s silence as a number of members have requested on behalf of all the victims concerned particularly those of the terrible storms in the various countries of the european union
第5行: please rise then for this minute s silence
第6行: the house rose and observed a minute s silence
第7行: madam president on a point of order
第8行: you will be aware from the press and television that there have been a number of bomb explosions and killings in sri lanka
第9行: one of the people assassinated very recently in sri lanka was mr unk unk who had visited the european parliament just a few months ago
第10行: would it be appropriate for you madam president to write a letter to the sri lankan president expressing parliaments regret at his and the other violent deaths in sri lanka and urging her to do everything she possibly can to seek a peaceful reconciliation to a very difficult situation
第11行: yes mr evans i feel an initiative of the type you have just suggested would be entirely appropriate
第12行: if the house agrees i shall do as mr evans has suggested
第13行: madam president on a point of order
第14行: i would like your advice about rule concerning inadmissibility
第15行: my question relates to something that will come up on thursday and which i will then raise again
第16行: the cunha report on multiannual guidance programmes comes before parliament on thursday and contains a proposal in paragraph that a form of quota penalties should be introduced for countries which fail to meet their fleet reduction targets annually
第17行: it says that this should be done despite the principle of relative stability
第18行: i believe that the principle of relative stability is a fundamental legal principle of the common fisheries policy and a proposal to subvert it would be legally inadmissible
第19行: i want to know whether one can raise an objection of that kind to what is merely a report not a legislative proposal and whether that is something i can competently do on thursday
法文原始词汇表大小: 141642
优化后的法文词汇表大小: 58800
已保存: E:/WH/llm_finetune/llm_finetune/NLP/Transformers-for-NLP-2nd-Edition-main/Chapter06/fr-en/french_vocab.pkl
法文数据集抽查结果:
第0行: reprise de la session
第1行: je declare reprise la session du parlement europeen qui avait ete interrompue le vendredi decembre dernier et je vous renouvelle tous mes vux en esperant que vous avez passe de bonnes vacances
第2行: comme vous avez pu le constater le grand bogue de lan ne sest pas produit en revanche les citoyens dun certain nombre de nos pays ont ete victimes de catastrophes naturelles qui ont vraiment ete terribles
第3行: vous avez souhaite un debat a ce sujet dans les prochains jours au cours de cette periode de session
第4行: en attendant je souhaiterais comme un certain nombre de collegues me lont demande que nous observions une minute de silence pour toutes les victimes des tempetes notamment dans les differents pays de lunion europeenne qui ont ete touches
第5行: je vous invite a vous lever pour cette minute de silence
第6行: le parlement debout observe une minute de silence
第7行: madame la presidente cest une motion de procedure
第8行: vous avez probablement appris par la presse et par la television que plusieurs attentats a la bombe et crimes ont ete perpetres au sri lanka
第9行: lune des personnes qui vient detre assassinee au sri lanka est m unk unk qui avait rendu visite au parlement europeen il y a quelques mois a peine
第10行: ne pensezvous pas madame la presidente quil conviendrait decrire une lettre au president du sri lanka pour lui communiquer que le parlement deplore les morts violentes dont celle de m unk et pour linviter instamment a faire tout ce qui est en son pouvoir pour chercher une reconciliation pacifique et mettre un terme a cette situation particulierement difficile
第11行: oui monsieur evans je pense quune initiative dans le sens que vous venez de suggerer serait tout a fait appropriee
第12行: si lassemblee en est daccord je ferai comme m evans la suggere
第13行: madame la presidente cest une motion de procedure
第14行: je voudrais vous demander un conseil au sujet de larticle qui concerne lirrecevabilite
第15行: ma question porte sur un sujet qui est a lordre du jour du jeudi et que je souleverai donc une nouvelle fois
第16行: le paragraphe du rapport cunha sur les programmes dorientation pluriannuels qui sera soumis au parlement ce jeudi propose dintroduire des sanctions applicables aux pays qui ne respectent pas les objectifs annuels de reduction de leur flotte
第17行: il precise que cela devrait etre fait malgre le principe de stabilite relative
第18行: a mon sens le principe de stabilite relative est un principe juridique fondamental de la politique commune de la peche et toute proposition le bouleversant serait juridiquement irrecevable
第19行: je voudrais savoir si lon peut avancer une objection de ce type a ce qui nest quun rapport pas une proposition legislative et si je suis habilite a le faire ce jeudiProcess finished with exit code 0
6.1.1、平滑技术:避免 “一棍子打死”
想象你是老师,给学生的作文打分。如果作文里有一个句子写得完全错误(比如跑题),你会直接给 0 分吗?显然不会 —— 可能其他句子写得不错,你会扣掉一部分分,但至少给个 30、40 分,体现 “部分正确”。
BLEU 里的平滑技术就干这个事:
- 机器翻译的 “错误” 就像作文里的错句。如果候选翻译和参考翻译的某个 n-gram(比如 4 个词的短语)完全不匹配,按原始规则,这个 n-gram 的分数就是 0,最后总分数也会被拉成 0(因为几何平均的特性,见下文)。
- 平滑技术就像老师的 “手下留情”:给这个完全不匹配的 n-gram 加一点点 “安慰分”(比如 0.001),让它不至于拖垮整个分数。这样即使有个别 n-gram 不匹配,总分也能反映 “整体匹配度”,而不是直接给 0 分。
例子:
参考翻译是 “我爱吃苹果”,候选翻译是 “我爱吃香蕉”。
- 原始规则:“苹果” 和 “香蕉” 完全不匹配,4-gram(整个句子)分数 0,总分 0。
- 平滑后:给 “香蕉” 和 “苹果” 的不匹配加一点分,总分可能变成 0.3(表示 “前半句匹配,后半句不匹配”),比 0 分更合理。
6.1.2、几何评估:算分要 “顾全大局”
还是老师打分的例子。如果给作文的 “词汇”“句子通顺度”“结构” 三个维度打分,怎么算总分?
- 算术平均:(词汇分 + 通顺度分 + 结构分)÷3。比如词汇 100 分,通顺度 0 分,结构 0 分,总分 33 分。
- 几何平均:三个分数相乘后开三次方。同样上面的情况,(100×0×0)开三次方 = 0 分。
BLEU 用的就是 “几何平均”:
- 它给翻译的 4 个维度打分:1 个词的匹配(词汇)、2 个词的匹配(短语)、3 个词的匹配(短句)、4 个词的匹配(长句)。
- 几何平均的特点是:只要有一个维度分数极低(比如 0),总分就会被拉很低。这就逼着机器翻译 “全面发展”—— 不仅单个词要对,短语、句子结构也要对,不能只靠 “蒙对几个词” 混分。
例子:
参考翻译是 “小猫喜欢喝牛奶”,候选翻译是 “小猫喝牛奶喜欢”。
- 1 个词的匹配:“小猫”“喝”“牛奶”“喜欢” 都对,分数 100。
- 2 个词的匹配:“小猫喜欢” vs “小猫喝”,不匹配,分数 0。
- 几何平均总分:(100×0×…)开 4 次方 = 0 分。这说明:即使单个词对了,语序错了(短语不匹配),整体分数也会很低 —— 符合人类对 “翻译通顺” 的要求。
6.1.3、两者结合:既公平又合理
平滑技术和几何评估配合起来,就像老师打分的 “标准流程”:
- 先用几何平均,要求翻译 “全面正确”(词汇、短语、结构都要对,否则总分低);
- 再用平滑技术,避免因为 “某一个小错误” 就给 0 分(比如某个短语错了,但其他都对,至少给点分)。
这样既保证了对翻译质量的严格要求,又不会因为一点小问题 “一棍子打死”,让分数更符合人类的直觉。
# BLEU评估:双语评估辅助分数计算
from nltk.translate.bleu_score import sentence_bleu
from nltk.translate.bleu_score import SmoothingFunction
# 示例1:完全匹配的候选翻译
# 参考译文列表(可包含多个正确译文)
reference = [['the', 'cat', 'likes', 'milk'], ['cat', 'likes', 'milk']]
# 机器生成的候选译文
candidate = ['the', 'cat', 'likes', 'milk']
# 计算BLEU分数(默认计算1-4元语法的加权分数)
score = sentence_bleu(reference, candidate)
print('示例1分数:', score)
# 示例2:单参考译文的完全匹配
reference = [['the', 'cat', 'likes', 'milk']]
candidate = ['the', 'cat', 'likes', 'milk']
score = sentence_bleu(reference, candidate)
print('示例2分数:', score)
# 示例3:部分匹配(同义词替换)
reference1 = [['the', 'cat', 'likes', 'milk']]
candidate1 = ['the', 'cat', 'enjoys', 'milk'] # "likes"替换为同义词"enjoys"
score1 = sentence_bleu(reference1, candidate1) #1.0547686614863434e-154 是科学计数法表示的数值,它表示的是一个非常小的数
print('示例3分数:', score1)
# 示例4:跨语言翻译评估(法语到英语)
# 参考译文(法语)
reference = [['je', 'vous', 'invite', 'a', 'vous', 'lever', 'pour', 'cette', 'minute', 'de', 'silence']]
# 候选译文(法语,机器翻译结果)
candidate = ['levez', 'vous', 'svp', 'pour', 'cette', 'minute', 'de', 'silence']
# 未使用平滑处理的BLEU分数(可能因短句导致分数为0)
score = sentence_bleu(reference, candidate)
print("未使用平滑处理的分数:", score)
# 使用平滑处理改善短句的BLEU分数计算
chencherry = SmoothingFunction()
# 将参考译文和候选译文按字符拆分(错误示范,应为分词列表)
r1 = list('je vous invite a vous lever pour cette minute de silence')
candidate = list('levez vous svp pour cette minute de silence')
# 平滑方法1计算BLEU分数
# 注意:此处r1和candidate的分词方式错误,正确方式应为单词列表
print("使用平滑处理的分数:", sentence_bleu([r1], candidate, smoothing_function=chencherry.method1))示例1分数: 1.0
示例2分数: 1.0
示例3分数: 1.0547686614863434e-154
未使用平滑处理的分数: 0.37188004246466494
使用平滑处理的分数: 0.6194291765462159