1、 实体类(表)
2、 导航(编程方便)
a) 通过学生 取出 学生所先的课程
b) 但是通过课程 取出 学该课程的 学生不好。学的学生太多
c) 确定编程的方式
3、 可以利用联合主键映射可以,
a) 学生生成一个表
b) 课程生成一个表
c) 再生成一个表,主键是联合主键(学生ID、课程ID) + 学生共生成一个表
4、 也可以利用一对多,多对多 都可以(推荐)
a) 学生生成一个表
b) 课程生成一个表
c) 分数生成一个表,并且有两个外键,分别指向学生、课程表
* 课程
@Entity
public class Course
public void setId(int id) { this.id = id;}
public String getName() {return name;}
public void setName(Stringname) {this.name = name;}}
* 分数
@Entity
@Table(name = “score”)
public class Score
@ManyToOne
@JoinColumn(name = “student_id”)
public StudentgetStudent() {return student;}
@ManyToOne
@JoinColumn(name = “score_id”)
public Course getCourse(){ return course;}
public int getScore() { return score;}
public void setScore(int score) {this.score = score;}
public void setStudent(Studentstudent) {this.student = student;}
public void setCourse(Coursecourse) {this.course = course;}
public void setId(int id) { this.id = id;}}
* 学生通过课程可以导航到分数
@Entity
public class Student
@ManyToMany
@JoinTable(name = “score”, //此表就是Score实体类在数据库生成的表叫score
joinColumns= @JoinColumn(name = “student_id”),
inverseJoinColumns= @JoinColumn(name = “course_id”)
)
public Set<Course>getCourses() {return courses;}
public voidsetCourses(Set<Course> courses) {this.courses = courses;}
public void setId(int id) { this.id = id;}
public String getName() {return name;}
public void setName(Stringname) {this.name = name;}}
在Student实体类中的使用的第三方表使用了两个字段,而hibernate会使这两个字段生成联合主键,这并不是我们需要的结果,因为我们需要手动到数据库中修改。这样才可以存储数据,否则数据存储不进去。这可能是hibernate的一个小bug
HQL VS EJBQL
1、 NativeSQL:本地语言(数据库自己的SQL语句)
2、 HQL :Hibernate自带的查询语句,可以使用HQL语言,转换成具体的方言
3、 EJBQL:JPQL 1.0,可以认为是HQL的一个子节(重点)
4、 QBC:Query By Cretira
5、 QBE:Query By Example
注意:上面的功能是从1至5的比较,1的功能最大,5的功能最小
1、 版块
/** 版块*/
@Entity
public class Category
public void setId(int id) {this.id = id;}
public String getName() {return name;}
public void setName(Stringname) {this.name = name;}}
2、 主题
/**主题*/
@Entity
public class Topic
public void setCreateDate(DatecreateDate) {this.createDate = createDate;}
@ManyToOne(fetch=FetchType.LAZY)
public CategorygetCategory() { return category;}
public voidsetCategory(Category category) {this.category = category; }
@Id
@GeneratedValue
public int getId() {return id;}
public void setId(int id) {this.id = id;}
public String getTitle(){return title;}
public void setTitle(Stringtitle) {this.title = title;}}
3、 主题回复
/**主题回复*/
@Entity
public class Msg
public void setTopic(Topictopic) {this.topic = topic;}
@Id
@GeneratedValue
public int getId() {return id;}
public void setId(int id) {this.id = id;}
public String getCont() {return cont;}
public void setCont(Stringcont) {this.cont = cont;}}
4、 临时类
/**临时类 */
public class MsgInfo { //VO DTO Value Object username p1 p2UserInfo->User->DB
private int id;
private String cont;
private String topicName;
private String categoryName;
public MsgInfo(int id, String cont,String topicName, String categoryName) {
super();
this.id = id;
this.cont = cont;
this.topicName = topicName;
this.categoryName =categoryName;
}
public StringgetTopicName() {return topicName;}
public voidsetTopicName(String topicName) {this.topicName = topicName;}
public StringgetCategoryName() {return categoryName;}
public voidsetCategoryName(String categoryName) {
this.categoryName =categoryName;
}
public int getId() {return id;}
public void setId(int id) {this.id = id;}
public String getCont() {return cont;}
public void setCont(Stringcont) {this.cont = cont;}}
//初始化数据
@Test
public void testSave()
for(int i=0; i<10; i++)
for(int i=0; i<10; i++)
session.getTransaction().commit();
session.close();
}
/** QL:from + 实体类名称 */
Query q =session.createQuery(“from Category”);
List<Category>categories = (List<Category>)q.list();
for(Category c : categories)
/* 可以为实体类起个别名,然后使用它 */
Query q =session.createQuery(“from Category c wherec.name > ‘c5′”);
List<Category>categories = (List<Category>)q.list();
for(Category c : categories)
//排序
Query q =session.createQuery(“from Category c orderby c.name desc”);
List<Category>categories = (List<Category>)q.list();
for(Category c : categories)
* 为加载上来的对象属性起别名,还可以使用
Query q =session.createQuery(“select distinct c fromCategory c order by c.name desc”);
List<Category>categories = (List<Category>)q.list();
for(Category c : categories)
/*Query q = session.createQuery(“from Category c where c.id > :minand c.id < :max”);
//q.setParameter(“min”,2);
//q.setParameter(“max”,8);
q.setInteger(“min”,2);
q.setInteger(“max”,8);*/
* 可以使用冒号(:),作为占位符,来接受参数使用。如下(链式编程)
Query q =session.createQuery(“from Category c wherec.id > :min and c.id < :max”)
.setInteger(“min”, 2)
.setInteger(“max”, 8);
List<Category>categories = (List<Category>)q.list();
for(Category c : categories)
Query q =session.createQuery(“from Category c wherec.id > ? and c.id < ?”);
q.setParameter(0, 2)
.setParameter(1, 8);
// q.setParameter(1, 8);
List<Category>categories = (List<Category>)q.list();
for(Category c : categories)
//分页
Query q =session.createQuery(“from Category c orderby c.name desc”);
q.setMaxResults(4);//每页显示的最大记录数
q.setFirstResult(2);//从第几条开始显示,从0开始
List<Category>categories = (List<Category>)q.list();
for(Category c : categories)
Query q =session.createQuery(“select c.id, c.name from Category c order by c.namedesc”);
List<Object[]>categories = (List<Object[]>)q.list();
for(Object[] o : categories) {
System.out.println(o[0] + “-” + o[1]);
}
//设定fetch type 为lazy后将不会有第二条sql语句
Query q =session.createQuery(“from Topic t wheret.category.id = 1”);
List<Topic>topics = (List<Topic>)q.list();
for(Topic t : topics)
//设定fetch type 为lazy后将不会有第二条sql语句
Query q =session.createQuery(“from Topic t wheret.category.id = 1”);
List<Topic>topics = (List<Topic>)q.list();
for(Topic t : topics)
Query q =session.createQuery(“from Msg m wherem.topic.category.id = 1”);
for(Object o : q.list())
//了解即可
//VO Value Object
//DTO data transfer object
Query q =session.createQuery(“select newcom.bjsxt.hibernate.MsgInfo(m.id, m.cont, m.topic.title, m.topic.category.name)from Msg”);
for(Object o : q.list())
//动手测试left right join
//为什么不能直接写Category名,而必须写t.category
//因为有可能存在多个成员变量(同一个类),需要指明用哪一个成员变量的连接条件来做连接
Query q =session.createQuery(“select t.title, c.namefrom Topic t join t.category c “); //join Category c
for(Object o : q.list()) {
Object[] m = (Object[])o;
System.out.println(m[0] + “-” + m[1]);
}
//学习使用uniqueResult
Query q = session.createQuery(“from Msg m where m = :MsgToSearch “); //不重要
Msg m = new Msg();
m.setId(1);
q.setParameter(“MsgToSearch”, m);
Msg mResult =(Msg)q.uniqueResult();
System.out.println(mResult.getCont());
Query q =session.createQuery(“select count(*) fromMsg m”);
long count = (Long)q.uniqueResult();
System.out.println(count);
Query q = session.createQuery(“select max(m.id), min(m.id), avg(m.id), sum(m.id)from Msg m”);
Object[] o =(Object[])q.uniqueResult();
System.out.println(o[0] + “-” + o[1] + “-” + o[2] + “-” + o[3]);
Query q =session.createQuery(“from Msg m where m.idbetween 3 and 5”);
for(Object o : q.list())
Query q =session.createQuery(“from Msg m where m.idin (3,4, 5)”);
for(Object o : q.list())
//is null 与 is notnull
Query q =session.createQuery(“from Msg m where m.contis not null”);
for(Object o : q.list())
注意:实体二,实体类,只是在实体一的基础上修改了Topic类,添加了多对一的关联关系
@Entity
@NamedQueries({
@NamedQuery(name=”topic.selectCertainTopic”, query=”from Topic t where t.id = :id”)
})
/*@NamedNativeQueries(
{
@NamedNativeQuery(name=”topic.select2_5Topic”,query=”select * from topic limit 2, 5″)
})*/
public class Topic
public void setMsgs(List<Msg> msgs) {this.msgs = msgs;}
public Date getCreateDate() {return createDate;}
public void setCreateDate(Date createDate) {this.createDate = createDate; }
@ManyToOne(fetch=FetchType.LAZY)
public Category getCategory() { return category;}
public void setCategory(Category category) {this.category = category;}
@Id
@GeneratedValue
public int getId() {return id;}
public void setId(int id) {this.id = id;}
public String getTitle() { return title;}
public void setTitle(String title) {this.title = title;}}
注意:测试数据是实例一的测试数据
//is empty and is not empty
Query q =session.createQuery(“from Topic t wheret.msgs is empty”);
for(Object o : q.list())
Query q =session.createQuery(“from Topic t wheret.title like ‘%5′”);
for(Object o : q.list())
Query q =session.createQuery(“from Topic t wheret.title like ‘_5′”);
for(Object o : q.list())
//不重要
Query q = session.createQuery(“select lower(t.title),” +
“upper(t.title),” +
“trim(t.title),” +
“concat(t.title,’***’),” +
“length(t.title)” +
” from Topict “);
for(Object o : q.list()) {
Object[] arr = (Object[])o;
System.out.println(arr[0] + “-” + arr[1] + “-” + arr[2] + “-” + arr[3] + “-” + arr[4] + “-“);
}
Query q =session.createQuery(“select abs(t.id),” +
“sqrt(t.id),” +
“mod(t.id,2)” +
” from Topict “);
for(Object o : q.list()) {
Object[] arr =(Object[])o;
System.out.println(arr[0] + “-” + arr[1] + “-” + arr[2] );
}
Query q = session.createQuery(“selectcurrent_date, current_time, current_timestamp, t.id from Topic t”);
for(Object o : q.list()) {
Object[] arr =(Object[])o;
System.out.println(arr[0] + ” | ” + arr[1] + ” | ” + arr[2] + ” | ” + arr[3]);
}
Query q =session.createQuery(“from Topic t wheret.createDate < :date”);
q.setParameter(“date”, new Date());
for(Object o : q.list())
Query q =session.createQuery(“select t.title,count(*) from Topic t group by t.title”) ;
for(Object o : q.list()) {
Object[] arr =(Object[])o;
System.out.println(arr[0] + “|” + arr[1]);
}
Query q = session.createQuery(“selectt.title, count(*) from Topic t group by t.title having count(*) >= 1”) ;
for(Object o : q.list()) {
Object[] arr =(Object[])o;
System.out.println(arr[0] + “|” + arr[1]);
}
Query q =session.createQuery(“from Topic t where t.id< (select avg(t.id) from Topic t)”) ;
for(Object o : q.list())
Query q =session.createQuery(“from Topic t where t.id< ALL (select t.id from Topic t where mod(t.id, 2)= 0) “) ;
for(Object o : q.list())
//用in 可以实现exists的功能
//但是exists执行效率高
// t.id not in (1)
Query q =session.createQuery(“from Topic t where notexists (select m.id from Msg m where m.topic.id=t.id)”) ;
// Query q =session.createQuery(“from Topic t where exists (select m.id from Msg mwhere m.topic.id=t.id)”) ;
for(Object o : q.list())
//update and delete
//规范并没有说明是不是要更新persistent object,所以如果要使用,建议在单独的trasaction中执行
Query q =session.createQuery(“update Topic t sett.title = upper(t.title)”) ;
q.executeUpdate();
q = session.createQuery(“from Topic”);
for(Object o : q.list())
session.createQuery(“update Topic t set t.title = lower(t.title)”)
.executeUpdate();
//不重要
Query q =session.getNamedQuery(“topic.selectCertainTopic”);
q.setParameter(“id”, 5);
Topic t =(Topic)q.uniqueResult();
System.out.println(t.getTitle());
//Native(了解)
SQLQuery q =session.createSQLQuery(“select *from category limit 2,4”).addEntity(Category.class);
List<Category>categories = (List<Category>)q.list();
for(Category c : categories)
public void testHQL_35() {
//尚未实现JPA命名的NativeSQL
}
QBC(Query By Criteria)查询方式是Hibernate提供的“更加面向对象”的一种检索方式。QBC在条件查询上比HQL查询更为灵活,而且支持运行时动态生成查询语句。
在Hibernate应用中使用QBC查询通常经过3个步骤
(1)使用Session实例的createCriteria()方法创建Criteria对象
(2)使用工具类Restrictions的相关方法为Criteria对象设置查询对象
(3)使用Criteria对象的list()方法执行查询,返回查询结果
注意:数据是使用Hibernate查询章节的数据
//criterion 标准/准则/约束
Criteria c =session.createCriteria(Topic.class) //from Topic
.add(Restrictions.gt(“id”, 2)) //greater than = id > 2
.add(Restrictions.lt(“id”, 8)) //little than = id < 8
.add(Restrictions.like(“title”, “t_”))
.createCriteria(“category”)
.add(Restrictions.between(“id”, 3, 5)) //category.id >= 3 and category.id <=5
;
//DetachedCriterea
for(Object o : c.list())
Hibernate中Restrictions的方法 说明
Restrictions.eq =
Restrictions.allEq 利用Map来进行多个等于的限制
Restrictions.gt >
Restrictions.ge >=
Restrictions.lt <
Restrictions.le <=
Restrictions.between BETWEEN
Restrictions.like LIKE
Restrictions.in in
Restrictions.and and
Restrictions.or or
Restrictions.sqlRestriction 用SQL限定查询
============================================
QBE (QueryBy Example)
Criteria cri = session.createCriteria(Student.class);
cri.add(Example.create(s)); //s是一个Student对象
list cri.list();
实质:创建一个模版,比如我有一个表serial有一个 giftortoy字段,我设置serial.setgifttoy(“2”),
则这个表中的所有的giftortoy为2的数据都会出来
2: QBC (Query By Criteria) 主要有Criteria,Criterion,Oder,Restrictions类组成
session = this.getSession();
Criteria cri = session.createCriteria(JdItemSerialnumber.class);
Criterion cron = Restrictions.like(“customer”,name);
cri.add(cron);
list = cri.list();
==============================
Hibernate中 Restrictions.or()和Restrictions.disjunction()的区别是什么?
比较运算符
HQL运算符 QBC运算符 含义
= Restrictions.eq() 等于
<> Restrictions.not(Exprission.eq()) 不等于
> Restrictions.gt() 大于
>= Restrictions.ge() 大于等于
< Restrictions.lt() 小于
<= Restrictions.le() 小于等于
is null Restrictions.isnull() 等于空值
is not null Restrictions.isNotNull() 非空值
like Restrictions.like() 字符串模式匹配
and Restrictions.and() 逻辑与
and Restrictions.conjunction() 逻辑与
or Restrictions.or() 逻辑或
or Restrictions.disjunction() 逻辑或
not Restrictions.not() 逻辑非
in(列表) Restrictions.in() 等于列表中的某一个值
ont in(列表) Restrictions.not(Restrictions.in())不等于列表中任意一个值
between x and y Restrictions.between() 闭区间xy中的任意值
not between x and y Restrictions.not(Restrictions..between()) 小于值X或者大于值y
3: HQL
String hql = “select s.name ,avg(s.age) from Student s group bys.name”;
Query query = session.createQuery(hql);
list = query.list();
….
4: 本地SQL查询
session = sessionFactory.openSession();
tran = session.beginTransaction();
SQLQuery sq = session.createSQLQuery(sql);
sq.addEntity(Student.class);
list = sq.list();
tran.commit();
5: QID
Session的get()和load()方法提供了根据对象ID来检索对象的方式。该方式被用于事先知道了要检索对象ID的情况。
Order.asc(String propertyName)
升序排序
Order.desc(String propertyName)
降序排序
Porjections.avg(String propertyName)
求某属性的平均值
Projections.count(String propertyName)
统计某属性的数量
Projections.countDistinct(String propertyName)
统计某属性的不同值的数量
Projections.groupProperty(String propertyName)
指定一组属性值
Projections.max(String propertyName)
某属性的最大值
Projections.min(String propertyName)
某属性的最小值
Projections.projectionList()
创建一个新的projectionList对象
Projections.rowCount()
查询结果集中记录的条数
Projections.sum(String propertyName)
返回某属性值的合计
Criteria为我们提供了两个有用的方法:setFirstResult(intfirstResult)和setMaxResults(int maxResults).
setFirstResult(int firstResult)方法用于指定从哪一个对象开始检索(序号从0开始),默认为第一个对象(序号为0);setMaxResults(int maxResults)方法用于指定一次最多检索出的对象数目,默认为所有对象。
Session session = HibernateSessionFactory.getSessionFactory().openSession();
Transaction ts = null;
Criteria criteria = session.createCriteria(Order.class);
int pageSize = 15;
int pageNo = 1;
criteria.setFirstResult((pageNo-1)*pageSize);
criteria.setMaxResults(pageSize);
Iterator it = criteria.list().iterator();
ts.commit();
HibernateSessionFactory.closeSession();
复合查询就是在原有的查询基础上再进行查询。例如在顾客对定单的一对多关系中,在查询出所有的顾客对象后,希望在查询定单中money大于1000的定单对象。
Session session = HibernateSessionFactory.getSessionFactory().openSession();
Transaction ts = session.beginTransaction();
Criteria cuscriteria = session.createCriteria(Customer.class);
Criteria ordCriteria = cusCriteria.createCriteria(“orders”);
ordCriteria.add(Restrictions.gt(“money”, new Double(1000)));
Iterator it = cusCriteria.list().iterator();
ts.commit();
HibernateSessionFactory.closeSession();
离线查询又叫DetachedCriteria查询,它可以在Session之外进行构造,只有在需要执行查询时才与Session绑定。Session session =HibernateSessionFactory.getSessionFactory().openSession();
Transaction ts =session.beginTransaction();
Criteria cuscriteria =session.createCriteria(Customer.class);
Criteria ordCriteria =cusCriteria.createCriteria(“orders”);
ordCriteria.add(Restrictions.gt(“money”,new Double(1000)));
Iterator it =cusCriteria.list().iterator();
ts.commit();
HibernateSessionFactory.closeSession();
QBE查询就是检索与指定样本对象具有相同属性值的对象。因此QBE查询的关键就是样本对象的创建,样本对象中的所有非空属性均将作为查询条件。QBE查询的功能子集,虽然QBE没有QBC功能大,但是有些场合QBE使用起来更为方便。
工具类Example为Criteria对象指定样本对象作为查询条件
Session session = sf.openSession();
session.beginTransaction();
Topic tExample = new Topic();
tExample.setTitle(“T_”);
Example e = Example.create(tExample)
.ignoreCase().enableLike();
Criteria c = session.createCriteria(Topic.class)
.add(Restrictions.gt(“id”, 2))
.add(Restrictions.lt(“id”, 8))
.add(e);
for(Object o : c.list())
session.getTransaction().commit();
session.close();
Session session = HibernateSessionFactory.getSessionFactory().openSession();
Transaction ts = session.beginTransaction();
Customer c = new Customer();
c.setCname(“Hibernate”);
Criteria criteria = session.createCriteria(Customer.class);
Criteria.add(Example.create(c));
Iterator it = criteria.list().iterator();
ts.commit();
HibernateSessionFactory.closeSession();
* query.iterate()方式返回迭代查询
* 会开始发出一条语句:查询所有记录ID语句
* Hibernate: select student0_.id as col_0_0_from t_student student0_
* 然后有多少条记录,会发出多少条查询语句。
* n + 1问题:n:有n条记录,发出n条查询语句;1 :发出一条查询所有记录ID语句。
* 出现n+1的原因:因为iterate(迭代查询)是使用缓存的,
第一次查询数据时发出查询语句加载数据并加入到缓存,以后再查询时hibernate会先到ession缓存(一级缓存)中查看数据是否存在,如果存在则直接取出使用,否则发出查询语句进行查询。
session= HibernateUtils.getSession();
tx = session.beginTransaction();
/**
* 出现N+1问题
* 发出查询id列表的sql语句
* Hibernate: select student0_.id as col_0_0_ from t_student student0_
*
* 再依次发出根据id查询Student对象的sql语句
* Hibernate: select student0_.id as id1_0_, student0_.name as name1_0_,
* student0_.createTime as createTime1_0_, student0_.classesid as classesid1_0_
* from t_student student0_ where student0_.id=?
*/
Iterator students = session.createQuery(“fromStudent”).iterate();
while (students.hasNext())
tx.commit();
先执行query.list(),再执行query.iterate,这样不会出现N+1问题,
* 因为list操作已经将Student对象放到了一级缓存中,所以再次使用iterate操作的时候
* 它首先发出一条查询id列表的sql,再根据id到缓存中取数据,只有在缓存中找不到相应的
* 数据时,才会发出sql到数据库中查询
Liststudents = session.createQuery(“from Student”).list();
for (Iterator iter = students.iterator();iter.hasNext();) System.out.println(“———————————————————“);
// 不会出现N+1问题,因为list操作已经将数据加入到一级缓存。
Iterator iters =session.createQuery(“from Student”).iterate();
while (iters.hasNext())
* 会再次发出查询sql
* 在默认情况下list每次都会向数据库发出查询对象的sql,除非配置了查询缓存
* 所以:虽然list操作已经将数据放到一级缓存,但list默认情况下不会利用缓存,而再次发出sql
* 默认情况下,list会向缓存中放入数据,但不会使用数据。
Liststudents = session.createQuery(“from Student”).list();
for (Iterator iter = students.iterator();iter.hasNext();)
System.out.println(“————————————————“);
//会再次发现SQL语句进行查询,因为默认情况list只向缓存中放入数据,不会使用缓存中数据
students = session.createQuery(“fromStudent”).list();
for (Iterator iter = students.iterator();iter.hasNext();)
1、 注意session.clear()的动用,尤其在不断分页循环的时候
a) 在一个大集合中进行遍历,遍历msg,取出其中的含有敏感字样的对象
b) 另外一种形式的内存泄露 //面试是:Java有内存泄漏吗?
2、 1 + N问题 //典型的面试题
a) Lazy
b) BatchSize 设置在实体类的前面
c) joinfetch
3、 list 和 iterate不同之处
a) list取所有
b) Iterate先取ID,等用到的时候再根据ID来取对象
c) session中list第二次发出,仍会到数据库查询
d) iterate第二次,首先找session级缓存
一级缓存很短和session的生命周期一致,因此也叫session级缓存或事务级缓存
hibernate一级缓存
那些方法支持一级缓存:
* get()
* load()
* iterate(查询实体对象)
如何管理一级缓存:
*session.clear(),session.evict()
如何避免一次性大量的实体数据入库导致内存溢出
* 先flush,再clear
如果数据量特别大,考虑采用jdbc实现,如果jdbc也不能满足要求可以考虑采用数据本身的特定导入工具
Hibernate默认的二级缓存是开启的。
二级缓存也称为进程级的缓存,也可称为SessionFactory级的缓存(因为SessionFactory可以管理二级缓存),它与session级缓存不一样,一级缓存只要session关闭缓存就不存在了。而二级缓存则只要进程在二级缓存就可用。
二级缓存可以被所有的session共享
二级缓存的生命周期和SessionFactory的生命周期一样,SessionFactory可以管理二级缓存
二级缓存同session级缓存一样,只缓存实体对象,普通属性的查询不会缓存
二级缓存一般使用第三方的产品,如EHCache
1、 二级缓存的配置和使用:
配置二级缓存的配置文件:模板文件位于hibernateetc目录下(如ehcache.xml),将模板存放在ClassPath目录中,一般放在根目录下(src目录下)
<ehcache>
<!– 设置当缓存对象益出时,对象保存到磁盘时的保存路径。
如 d:xxxx
The following properties aretranslated:
user.home – User’s home directory
user.dir – User’s current workingdirectory
java.io.tmpdir – windows的临时目录 –>
<diskStore path=“java.io.tmpdir”/>
<!–默认配置/或对某一个类进行管理
maxInMemory – 缓存中可以存入的最多个对象数
eternal – true:表示永不失效,false:不是永久有效的。
timeToIdleSeconds – 空闲时间,当第一次访问后在空闲时间内没有访问,则对象失效,单位为秒
timeToLiveSeconds – 被缓存的对象有效的生命时间,单位为秒
overflowToDisk 当缓存中对象数超过核定数(益出时)时,对象是否保存到磁盘上。true:保存;false:不保存
如果保存,则保存路径在标签<diskStore>中属性path指定
–>
<defaultCache
maxElementsInMemory=“10000”
eternal=“false”
timeToIdleSeconds=“120”
timeToLiveSeconds=“120”
overflowToDisk=“true”
/>
</ehcache>
2、 二级缓存的开启:
Hibernate中二级缓存默认就是开启的,也可以显示的开启
二级缓存是hibernate的配置文件设置如下:
<!–开启二级缓存,hibernate默认的二级缓存就是开启的 –>
<property name=“hibernate.cache.use_second_level_cache”>true</property>
3、 指定二级缓存产品提供商:
修改hibernate的 配置文件,指定二级缓存提供商,如下:
<!–指定二级缓存提供商–>
<property name=“hibernate.cache.provider_class”>
org.hibernate.cache.EhCacheProvider
</property>
以下为常见缓存提供商:
Cache
Provider class
Type
Cluster Safe
Query Cache Supported
Hashtable (not intended for production use)
org.hibernate.cache.HashtableCacheProvider
memory
yes
EHCache
org.hibernate.cache.EhCacheProvider
memory, disk
yes
OSCache
org.hibernate.cache.OSCacheProvider
memory, disk
yes
SwarmCache
org.hibernate.cache.SwarmCacheProvider
clustered (ip multicast)
yes (clustered invalidation)
JBoss TreeCache
org.hibernate.cache.TreeCacheProvider
clustered (ip multicast), transactional
yes (replication)
yes (clock sync req.)
4、 使用二级缓存
a) xml方式:指定哪些实体类使用二级缓存:
方法一:在实体类映射文件中,使用<cache>来指定那个实体类使用二级缓存,如下:
<cache
usage="transactional|read-write|nonstrict-read-write|read-only" (1)
region="RegionName" (2)
include="all|non-lazy" (3)
/>
(1) usage(必须)说明了缓存的策略: transactional、 read-write、nonstrict-read-write或read-only。
(2) region (可选, 默认为类或者集合的名字(class orcollection role name)) 指定第二级缓存的区域名(name of the secondlevel cache region)
(3) include (可选,默认为 all) non-lazy 当属性级延迟抓取打开时, 标记为lazy="true"的实体的属性可能无法被缓存
另外(首选?), 你可以在hibernate.cfg.xml中指定<class-cache>和 <collection-cache> 元素。
这里的usage 属性指明了缓存并发策略(cache concurrency strategy)。
策略:只读缓存(Strategy:read only)
如果你的应用程序只需读取一个持久化类的实例,而无需对其修改, 那么就可以对其进行只读 缓存。这是最简单,也是实用性最好的方法。甚至在集群中,它也能完美地运作。
<class name="eg.Immutable" mutable="false">
<cache usage="read-only"/>
....
</class>
策略:读/写缓存(Strategy:read/write)
如果应用程序需要更新数据,那么使用读/写缓存 比较合适。 如果应用程序要求“序列化事务”的隔离级别(serializable transaction isolation level),那么就决不能使用这种缓存策略。 如果在JTA环境中使用缓存,你必须指定hibernate.transaction.manager_lookup_class属性的值, 通过它,Hibernate才能知道该应用程序中JTA的TransactionManager的具体策略。 在其它环境中,你必须保证在Session.close()、或Session.disconnect()调用前, 整个事务已经结束。 如果你想在集群环境中使用此策略,你必须保证底层的缓存实现支持锁定(locking)。Hibernate内置的缓存策略并不支持锁定功能。
<class name="eg.Cat" .... >
<cache usage="read-write"/>
....
<set name="kittens" ... >
<cache usage="read-write"/>
....
</set>
</class>
策略:非严格读/写缓存(Strategy: nonstrictread/write)
如果应用程序只偶尔需要更新数据(也就是说,两个事务同时更新同一记录的情况很不常见),也不需要十分严格的事务隔离,那么比较适合使用非严格读/写缓存策略。如果在JTA环境中使用该策略,你必须为其指定hibernate.transaction.manager_lookup_class属性的值, 在其它环境中,你必须保证在Session.close()、或Session.disconnect()调用前, 整个事务已经结束。
策略:事务缓存(transactional)
Hibernate的事务缓存策略提供了全事务的缓存支持, 例如对JBoss TreeCache的支持。这样的缓存只能用于JTA环境中,你必须指定为其hibernate.transaction.manager_lookup_class属性。
没有一种缓存提供商能够支持上列的所有缓存并发策略。下表中列出了各种提供器、及其各自适用的并发策略。
表 19.2. 各种缓存提供商对缓存并发策略的支持情况(Cache Concurrency Strategy Support)
Cache
read-only
nonstrict-read-write
read-write
transactional
Hashtable (not intended for production use)
yes
yes
yes
EHCache
yes
yes
yes
OSCache
yes
yes
yes
SwarmCache
yes
yes
JBoss TreeCache
yes
yes
注:此方法要求:必须要标签<cache>放在<id>标签之前
<class name=“com.wjt276.hibernate.Student”table=“t_student”>
<!– 指定实体类使用二级缓存 –>
<cache usage=“read-only”/>//***********
<id name=“id”column=“id”>
<generator class=“native”/>
</id>
<property name=“name”column=“name”/>
<!–
使用多对一标签映射 一对多双向,下列的column值必需与多的一端的key字段值一样。
–>
<many-to-one name=“classes”column=“classesid”/>
</class>
方法二:在hibernate配置文件(hibernate.cfg.xml)使用<class-cache>标签中指定
要求:<class-cache>标签必须放在<maping>标签之后。
<hibernate-configuration>
<session-factory>
…………
<mapping resource=“com/wjt276/hibernate/Classes.hbm.xml”/>
<mapping resource=“com/wjt276/hibernate/Student.hbm.xml”/>
<class-cache class=“com.wjt276.hibernate.Student”usage=“read-only”/>
</session-factory>
</hibernate-configuration>
一般推荐使用方法一。
b) annotation注解
为了优化数据库访问,你可以激活所谓的Hibernate二级缓存.该缓存是可以按每个实体和集合进行配置的.
@org.hibernate.annotations.Cache定义了缓存策略及给定的二级缓存的范围. 此注解适用于根实体(非子实体),还有集合.
@Entity
@Cache(usage= CacheConcurrencyStrategy.NONSTRICT_READ_WRITE)
publicclass Forest { … }
@OneToMany(cascade=CascadeType.ALL,fetch=FetchType.EAGER)
@JoinColumn(name=”CUST_ID”)
@Cache(usage =CacheConcurrencyStrategy.NONSTRICT_READ_WRITE)
public SortedSet<Ticket> getTickets(){
return tickets;
}
@Cache(
CacheConcurrencyStrategy usage(); (1)
String region() default “”; (2)
String include() default”all”; (3)
)
(1)
usage: 给定缓存的并发策略(NONE, READ_ONLY, NONSTRICT_READ_WRITE, READ_WRITE, TRANSACTIONAL)
(2)
region (可选的):缓存范围(默认为类的全限定类名或是集合的全限定角色名)
(3)
include (可选的):值为all时包括了所有的属性(proterty), 为non-lazy时仅含非延迟属性(默认值为all)
5、 应用范围
没有变化,近似于静态的数据。
6、 二级缓存的管理:
1、 清除指定实体类的所有数据
SessionFactory.evict(Student.class);
2、 清除指定实体类的指定对象
SessionFactory.evict(Student.class, 1);//第二个参数是指定对象的ID,就可以清除指定ID的对象
使用SessionFactory清除二级缓存
Sessionsession = null;
try catch(Exception e) finally {
HibernateUtils.closeSession(session);
}
//管理二级缓存
SessionFactory factory = HibernateUtils.getSessionFactory();
//factory.evict(Student.class);
factory.evict(Student.class, 1);
try catch(Exception e) finally {
HibernateUtils.closeSession(session);
}
7、 二级缓存的交互
Sessionsession = null;
try catch(Exception e) finally {
HibernateUtils.closeSession(session);
}
try catch(Exception e) finally {
HibernateUtils.closeSession(session);
}
try catch(Exception e) finally {
HibernateUtils.closeSession(session);
}
CacheMode参数用于控制具体的Session如何与二级缓存进行交互。
· CacheMode.NORMAL – 从二级缓存中读、写数据。
· CacheMode.GET – 从二级缓存中读取数据,仅在数据更新时对二级缓存写数据。
· CacheMode.PUT – 仅向二级缓存写数据,但不从二级缓存中读数据。
· CacheMode.REFRESH – 仅向二级缓存写数据,但不从二级缓存中读数据。通过hibernate.cache.use_minimal_puts的设置,强制二级缓存从数据库中读取数据,刷新缓存内容。
如若需要查看二级缓存或查询缓存区域的内容,你可以使用统计(Statistics) API。
Map cacheEntries = sessionFactory.getStatistics()
.getSecondLevelCacheStatistics(regionName)
.getEntries();
此时,你必须手工打开统计选项。可选的,你可以让Hibernate更人工可读的方式维护缓存内容。
hibernate.generate_statistics true
hibernate.cache.use_structured_entries true
8、 总结
load默认使用二级缓存,iterate默认使用二级缓存
list默认向二级缓存中加数据,但是查询时候不使用
查询缓存,是用于缓存普通属性查询的,当查询实体时缓存实体ID。
默认情况下关闭,需要打开。查询缓存,对list/iterator这样的操作会起作用。
可以使用<property name=”hibernate.cache.use_query_cache”>true</property>来打开查询缓存,默认为关闭。
所谓查询缓存:即让hibernate缓存list、iterator、createQuery等方法的查询结果集。如果没有打开查询缓存,hibernate将只缓存load方法获得的单个持久化对象。
在打开了查询缓存之后,需要注意,调用query.list()操作之前,必须显式调用query.setCachable(true)来标识某个查询使用缓存。
查询缓存的生命周期:当前关联的表发生修改,那么查询缓存生命周期结束
注意查询缓存依赖于二级缓存,因为使用查询缓存需要打开二级缓存
查询缓存的配置和使用:
* 在hibernate.cfg.xml文件中启用查询缓存,如:
<propertyname=”hibernate.cache.use_query_cache”>true</property>
* 在程序中必须手动启用查询缓存,如:
query.setCacheable(true);
例如:
session= HibernateUtils.getSession();
session.beginTransaction();
Query query = session.createQuery(“selects.name from Student s”);
//启用查询查询缓存
query.setCacheable(true);
List names = query.list();
for (Iterator iter=names.iterator();iter.hasNext();) {
String name =(String)iter.next();
System.out.println(name);
}
System.out.println(“————————————-“);
query = session.createQuery(“selects.name from Student s”);
//启用查询查询缓存
query.setCacheable(true);
//没有发出查询sql,因为启用了查询缓存
names = query.list();
for (Iteratoriter=names.iterator();iter.hasNext(); ) {
String name =(String)iter.next();
System.out.println(name);
}
session.getTransaction().commit();
Session session = sf.openSession();
session.beginTransaction();
List<Category>categories = (List<Category>)session.createQuery(“from Category”)
.setCacheable(true).list();
session.getTransaction().commit();
session.close();
Session session2 = sf.openSession();
session2.beginTransaction();
List<Category>categories2 = (List<Category>)session2.createQuery(“from Category”)
.setCacheable(true).list();
session2.getTransaction().commit();
session2.close();
注:查询缓存的生命周期与session无关。
查询缓存只对query.list()起作用,query.iterate不起作用,也就是query.iterate不使用
1、 LRU、LFU、FIFO
1、 ReadUncommited(未提交读):没有提交就可以读取到数据(发出了Insert,但没有commit就可以读取到。)很少用
2、 ReadCommited(提交读):只有提交后才可以读,常用,
3、 RepeatableRead(可重复读):mysql默认级别, 必需提交才能见到,读取数据时数据被锁住。
4、 Serialiazble(序列化读):最高隔离级别,串型的,你操作完了,我才可以操作,并发性特别不好,
隔离级别
是否存在脏读
是否存在不可重复读
是否存在幻读
Read Uncommitted(未提交读)
Y
Y
Y
Read Commited(提交读)
N
Y(可采用悲观锁解决)
Y
Repeatable Read(可重复读)
N
N
Y
Serialiazble(序列化读)
脏读:没有提交就可以读取到数据称为脏读
不可重复读:再重复读一次,数据与你上的不一样。称不可重复读。
幻读:在查询某一条件的数据,开始查询的后,别人又加入或删除些数据,再读取时与原来的数据不一样了。
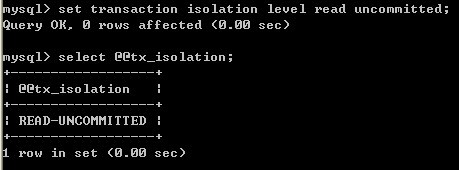
1、 Mysql查看数据库隔离级别:
方法:select@@tx_isolation;

2、 Mysql数据库修改隔离级别:
方法:set transactionisolation level 隔离级别名称;
例如:修改为未提交读:settransaction isolation level read uncommitted;
ACID即:事务的原子性、一致性、独立性及持久性
事务的原子性:是指一个事务要么全部执行,要么不执行.也就是说一个事务不可能只执行了一半就停止了.比如你从取款机取钱,这个事务可以分成两个步骤:1划卡,2出钱.不可能划了卡,而钱却没出来.这两步必须同时完成.要么就不完成.
事务的一致性:是指事务的运行并不改变数据库中数据的一致性.例如,完整性约束了a+b=10,一个事务改变了a,那么b也应该随之改变.
事务的独立性:是指两个以上的事务不会出现交错执行的状态.因为这样可能会导致数据不一致.
事务的持久性:是指事务运行成功以后,就系统的更新是永久的.不会无缘无故的回滚.
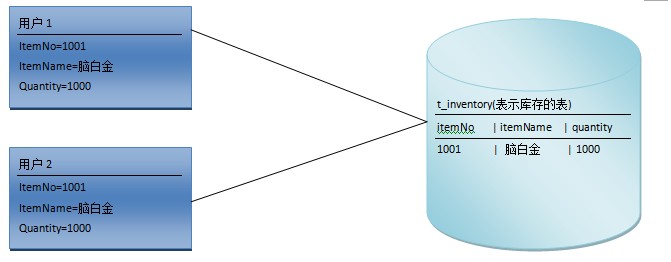
1、第一类丢失更新(Lost Update)
时间
Hibernate谈到悲观锁、乐观锁,就要谈到数据库的并发问题,数据库的隔离级别越高它的并发性就越差
并发性:当前系统进行了序列化后,当前读取数据后,别人查询不了,看不了。称为并发性不好
数据库隔离级别:见前面章级
悲观锁:具有排他性(我锁住当前数据后,别人看到不此数据)
悲观锁一般由数据机制来做到的。
通常依赖于数据库机制,在整修过程中将数据锁定,其它任何用户都不能读取或修改(如:必需我修改完之后,别人才可以修改)
悲观锁一般适合短事务比较多(如某一数据取出后加1,立即释放)
长事务占有时间(如果占有1个小时,那么这个1小时别人就不可以使用这些数据),不常用。
yon
用户1、用户2 同时读取到数据,但是用户2先 -200,这时数据库里的是800,现在用户1也开始-200,可是用户1刚才读取到的数据是1000,现在用户用刚刚一开始读取的数据1000-200为800,而用户1在更新时数据库里的是用房更新的数据800,按理说用户1应该是800-200=600,而现在是800,这样就造成的更新丢失。这种情况该如何处理呢,可采用两种方法:悲观锁、乐观锁。先看看悲观锁:用户1读取数据后,用锁将其读取的数据锁上,这时用户2是读取不到数据的,只有用户1释放锁后用户2才可以读取,同样用户2读取数据也锁上。这样就可以解决更新丢失的问题了。
实体类:
public class Inventory
public voidsetItemNo(intitemNo) {
this.itemNo =itemNo;
}
publicString getItemName() {
return itemName;
}
public voidsetItemName(String itemName) {
this.itemName =itemName;
}
public intgetQuantity() {
return quantity;
}
public voidsetQuantity(intquantity) {
this.quantity =quantity;
}
}
映射文件:
<hibernate-mapping>
<class name=“com.wjt276.hibernate.Inventory”table=“t_inventory”>
<id name=“itemNo”>
<generator class=“native”/>
</id>
<property name=“itemName”/>
<property name=“quantity”/>
</class>
</hibernate-mapping>
如果需要使用悲观锁,肯定在加载数据时就要锁住,通常采用数据库的for update语句。
Hibernate使用Load进行悲观锁加载。
Session.load(Classarg0, Serializable arg1, LockMode arg2) throws HibernateException
LockMode:悲观锁模式(一般使用LockMode.UPGRADE)
session= HibernateUtils.getSession();
tx = session.beginTransaction();
Inventory inv =(Inventory)session.load(Inventory.class, 1,LockMode.UPGRADE);
System.out.println(inv.getItemName());
inv.setQuantity(inv.getQuantity()-200);
session.update(inv);
tx.commit();
Hibernate:select inventory0_.itemNo as itemNo0_0_, inventory0_.itemName as itemName0_0_,inventory0_.quantity as quantity0_0_ from t_inventory inventory0_ where inventory0_.itemNo=?for update //在select语句中加入for update进行使用悲观锁。
脑白金
Hibernate:update t_inventory set itemName=?, quantity=? where itemNo=?
注:只有用户释放锁后,别的用户才可以读取
注:如果使用悲观锁,那么lazy(悚加载无效)
乐观锁:不是锁,是一种冲突检测机制。
乐观锁的并发性较好,因为我改的时候,别人随边修改。
乐观锁的实现方式:常用的是版本的方式(每个数据表中有一个版本字段version,某一个用户更新数据后,版本号+1,另一个用户修改后再+1,当用户更新发现数据库当前版本号与读取数据时版本号不一致(等于小于数据库当前版本号),则更新不了。
Hibernate使用乐观锁需要在映射文件中配置项才可生效。
实体类:
public classInventory
public voidsetItemNo(intitemNo) {
this.itemNo =itemNo;
}
publicString getItemName() {
return itemName;
}
public voidsetItemName(String itemName) {
this.itemName =itemName;
}
public intgetQuantity() {
return quantity;
}
public voidsetQuantity(intquantity) {
this.quantity =quantity;
}
public intgetVersion() {
return version;
}
public voidsetVersion(intversion) {
this.version =version;
}
}
映射文件
<hibernate-mapping>
<!– 映射实体类时,需要加入一个开启乐观锁的属性
optimistic-lock=”version” 共有好几种方式:
– none -version – dirty – all
同时需要在主键映射后面映射版本号字段
–>
<class name=“com.wjt276.hibernate.Inventory”table=“t_inventory”optimistic-lock=“version”>
<id name=“itemNo”>
<generator class=“native”/>
</id>
<version name=“version”/><!—必需配置在主键映射后面 –>
<property name=“itemName”/>
<property name=“quantity”/>
</class>
</hibernate-mapping>
导出输出SQL语句:
createtable t_inventory (itemNo integer not null auto_increment, versioninteger not null, itemName varchar(255), quantity integer,primary key (itemNo))
注:添加的版本字段version,还是我们来维护的,是由hibernate来维护的。
乐观锁在存储数据时不用关心